大家听到“嗅探”这个词应该会觉得跟黑客肯定有关系吧,使用工具嗅探一下参数,然后截获,脱裤o(∩_∩)o 。
事实上,我觉得大家太敏感了,其实这篇文章跟数据库安全没有什么关系,实际上跟数据库性能调优有关
相信大家有泡SQLSERVER论坛的话不多不少应该都会见过“参数嗅探”这几个字
这里有三篇帖子都是讲述参数嗅探的
http://social.msdn.microsoft.com/Forums/zh-CN/sqlserverzhchs/thread/caccb7f3-8366-4954-8f8a-145eb6bca9dd
http://msdn.microsoft.com/zh-cn/magazine/ee236412.aspx
http://social.msdn.microsoft.com/Forums/zh-CN/sqlserverzhchs/thread/bfbe54de-ac00-49e9-a83b-f97a60bf74ef
下面我给出一个测试数据库的备份文件,里面有一些表和一些测试数据 ,大家可以去下载,因为我下面用的测试表都是这个数据库里的
只需要还原数据库就可以了,这个数据库是SQL2005版本的,数据库名:AdventureWorks
下面只需要用到三张表,表里面有索引:
[Production].[Product] [SalesOrderHeader_test] [SalesOrderDetail_test]
数据库下载链接:AdventureWorks

其实简单来讲,参数嗅探我的很通俗的解释就是:SQLSERVER用鼻子嗅不到具体参数是多少
所以他不能选择最合适的执行计划去执行你的查询,所以参数嗅探是一个不好的现象。
想真正了解参数嗅探,大家可以先创建下面两个存储过程
存储过程一:
USE [AdventureWorks] GO DROP PROC Sniff GO CREATE PROC Sniff(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i GO
存储过程二:
复制代码 代码如下:1 USE [AdventureWorks] 2 GO 3 DROP PROC Sniff2 4 GO 5 CREATE PROC Sniff2(@i INT) 6 AS 7 DECLARE @j INT 8 SET @j=@i 9 SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight])10 FROM [dbo].[SalesOrderHeader_test] a11 INNER JOIN [dbo].[SalesOrderDetail_test] b12 ON a.[SalesOrderID]=b.[SalesOrderID]13 INNER JOIN [Production].[Product] p14 ON b.[ProductID]=p.[ProductID]15 WHERE a.[SalesOrderID]=@j16 GO
然后请做下面这两个测试
测试一:
--测试一: USE [AdventureWorks] GO DBCC freeproccache GO EXEC [dbo].[Sniff] @i = 500000 -- int --发生编译,插入一个使用nested loops联接的执行计划 GO EXEC [dbo].[Sniff] @i = 75124 -- int --发生执行计划重用,重用上面的nested loops的执行计划 GO
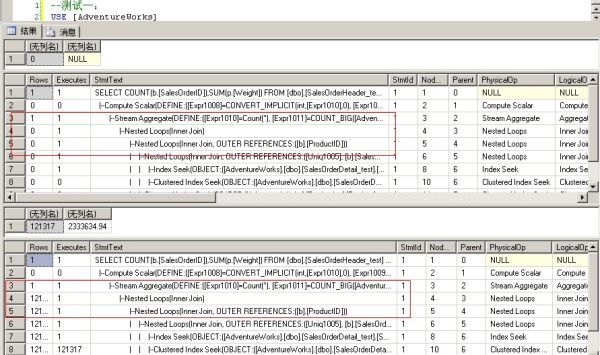
测试二:
--测试二: USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS PROFILE ON EXEC [dbo].[Sniff] @i = 75124 -- int --发生编译,插入一个使用hash match联接的执行计划 GO EXEC [dbo].[Sniff] @i = 50000 -- int --发生执行计划重用,重用上面的hash match的执行计划 GO
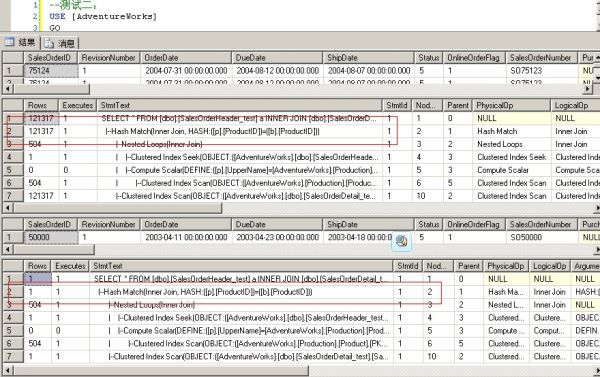
从上面两个测试可以清楚地看到执行计划重用的副作用。
由于数据分布差别很大参数50000和75124只对自己生成的执行计划有好的性能,
如果使用对方生成的执行计划,性能就会下降。参数50000返回的结果集比较小,
所以性能下降不太严重。参数75124返回的结果集大,就有了明显的性能下降,两个执行计划的差别有近10倍
对于这种因为重用他人生成的执行计划而导致的水土不服现象,SQSERVERL有一个专有名词,叫“参数嗅探 parameter sniffing”
因为语句的执行计划对变量的值很敏感,而导致重用执行计划会遇到性能问题,就是我上面说的
“
SQLSERVER用鼻子嗅不到具体参数是多少,所以他不能选择最合适的执行计划去执行你的查询
”
本地变量的影响
那对于有parameter sniffing问题的存储过程,如果使用本地变量,会怎样呢?
下面请看测试3。这次用不同的变量值时,都清空执行计划缓存,迫使其重编译
--第一次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff] @i = 50000 -- int GO
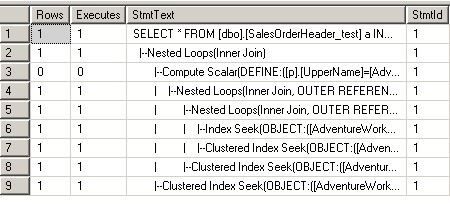
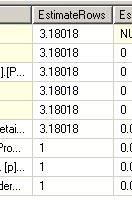
--第二次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff] @i = 75124 -- int GO
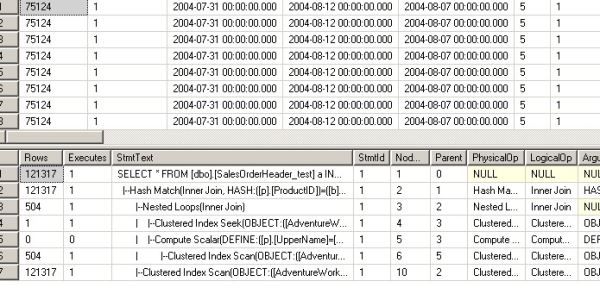
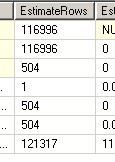
--第三次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff2] @i = 50000 -- int GO
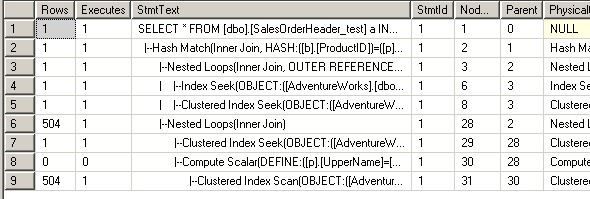
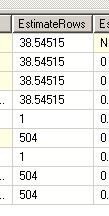
--第四次 USE [AdventureWorks] GO DBCC freeproccache GO SET STATISTICS TIME ON SET STATISTICS PROFILE ON EXEC [dbo].[Sniff2] @i = 75124 -- int GO

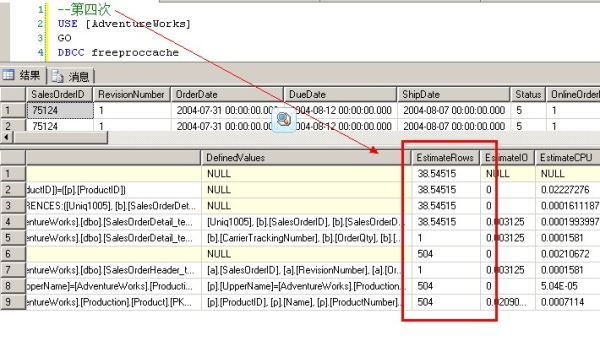
看他们的执行计划:
对于第一句和第二句,因为SQL在编译的时候知道变量的值,所以在做EstimateRows的时候,做得非常准确,选择了最适合他们的执行计划
但是对于第三句和第四句,SQLSERVER不知道@j的值是多少,所以在做EstimateRows的时候,不管代入的@i值是多少,
一律给@j一样的预测结果。所以两个执行计划是完全一样的(都是Hash Match)。
参数嗅探的解决办法
参数嗅探的问题发生的频率并不高,他只会发生在一些表格里的数据分布很不均匀,或者用户带入的参数值很不均匀的情况下。
由于篇幅原因我就不具体说了,只是做一些归纳
(1)用exec()的方式运行动态SQL
如果在存储过程里不是直接运行语句,而是把语句带上变量,生成一个字符串,再让exec()这样的命令做动态语句运行,
那SQL就会在运行到这句话的时候,对动态语句进行编译。
这时SQL已经知道了变量的值,会根据生成优化的执行计划,从而绕过参数嗅探问题
--例如前面的存储过程Sniff,就可以改成这样 USE [AdventureWorks] GO DROP PROC NOSniff GO CREATE PROC NOSniff(@i INT) AS DECLARE @cmd VARCHAR(1000) SET @cmd='SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=' EXEC(@cmd+@i) GO
(2)使用本地变量local variable
(3)在语句里使用query hint,指定执行计划
在select,insert,update,delete语句的最后,可以加一个"option(
对SQLSERVER将要生成的执行计划进行指导。当DBA知道问题所在以后,可以通过加hint的方式,引导
SQL生成一个比较安全的,对所有可能的变量值都不差的执行计划
USE [AdventureWorks] GO DROP PROC NoSniff_QueryHint_Recompile GO CREATE PROC NoSniff_QueryHint_Recompile(@i INT) AS SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i OPTION(RECOMPILE) GO
(4)Plan Guide
可以用下面的方法,在原来那个有参数嗅探问题的存储过程“Sniff”上,解决sniffing问题
USE [AdventureWorks] GO EXEC [sys].[sp_create_plan_guide] @name=N'Guide1', @stmt=N'SELECT COUNT(b.[SalesOrderID]),SUM(p.[Weight]) FROM [dbo].[SalesOrderHeader_test] a INNER JOIN [dbo].[SalesOrderDetail_test] b ON a.[SalesOrderID]=b.[SalesOrderID] INNER JOIN [Production].[Product] p ON b.[ProductID]=p.[ProductID] WHERE a.[SalesOrderID]=@i', @type=N'OBJECT', @module_or_batch=N'Sniff', @params=NULL, @hints=N'option(optimize for(@i=75124))'; GO
对于Plan Guide,他还可以使用在一般的语句调优里
终于搞定了,因为要搞测试数据的原因所以搞了很久啊~~
总结
以上所述是小编给大家介绍的何谓SQLSERVER参数嗅探问题,希望对大家有所帮助!