一、python介绍
1、版本区别
2.x.x:运行速度更快,使用它开发的库和软件更多。
3.x.x:拥有很多新型编程语言特性。
2、开发环境搭建
-
www.python.org:下载安装python运行环境
(1)配置环境变量,使得cmd可用:path-> C:\Python27
cmd进入python开发模式:python + Enter键
cmd退出python开发模式:exit() + Enter键 / ctrl + Z + Enter键
cmd运行python源程序:cmd进入源文件所在位置,输入:python xx.py
(2)python自带编译器:IDLE。
使用Ctrl+N可输入多行python语句,保存后按F5运行。
www.aptana.com:aptana编译器
www.jetbrains.com:下载pyCharm Professional版本,即python集成开发环境。(注册码)
www.web2py.com:非常强大的python网站开发框架:web2py。
3、python语言介绍
3大优点:
- 简单
- 功能强大
- 支持面向对象
7个特点:
- 大小写严格区分
- 简单、易学、支持面向对象
- 开源
- 库非常丰富。
如标准库:电子邮件、正则表达式、密码系统、GUI、FTP等;非标准库即扩展库:wxpython、图像库等。 - 跨平台使用。
任何平台写的python程序,在其他平台通用。 - 解释型语言
- 高级语言
二、数据类型
1、数
- int
- long
- float
- bool
- complex 复数型(如4+2j、-9+20j、56+7j等)
2、字符串
用单引号、双引号和三引号引起来的字符串。
单引号:
c1 = 'hello'
print c1
c2 = 'It is a "dog"!' # 单引号中可使用双引号,且双引号可输出出来
print c2
双引号:
c1 = "hello"
print c1
c2 = "It is a 'dog'!" # 双引号中可使用单引号,且单引号可输出出来
print c2
三引号:
c1 = '''he # 3个单引号
she
my
you are'''
print c1
c2 = """he # 3个双引号
she
my
you are"""
print c2
# 三引号引起的字符串可换行。
例子:
# 输出 It's a dog!
print "It's a dog!"
print 'It\'s a dog!'
# 输出 hello world!
# hello python!
print '''hello world!
hello python!'''
print "hello world!\nhello python!"
自然字符串
若一串字符串需要原样保留转义符,不进行任何处理,则使用自然字符串:在字符串前加上r。
print r"hello world!\nhello python!"
字符串的重复
# 方法1:手动重复输入
# 方法2:重复运算符 *
"hello"*20 # 计算机自动执行重复输出指令,将hello重复输出20次
子字符串
索引运算法:[]
返回下标所对应的一个字符。
切片运算法:[:]
[a:b] 从第a下标开始到第b-1下标。
[:b]
[a:]
取字符串长度
a="helloworld"
print len(a) # 10
切割字符串
a="student"
b=a.split("u")
print b # ['st', 'dent']
3、列表 []
用来存储一连串元素的容器。
列表中的元素值可以修改、添加或删除。
# coding=utf-8
students = ["小明", "小华", "小军", "小云"]
print students[3]
students[3] = "小东"
print students[3]
4、元组 ()
用来存储一连串元素的容器。
元组中的元素值不可以修改、添加或删除。
# coding=utf-8
students = ("小明", "小华", "小军", "小云")
print students[1]
students[1] = "小强"
print students[1] # 报错:TypeError: 'tuple' object does not support item assignment
5、集合 set(元素)
# 去除重复元素
a = set("abcnmaaaaggsng")
print a # 打印:set(['a', 'c', 'b', 'g', 'm', 'n', 's'])
b = set("cdfm")
# 交集
x = a&b
# 并集
y = a|b
# 差集
z = a-b
6、字典/关联数组 {}
字典中包含的是一整个事情,里面包括各方面的具体信息。
zidian = {'name':'zhangsan', 'home':'beijing', 'like':'music'}
# 搜某个信息的值
k = {'name':'zhangsan', 'home':'beijing'}
print k['home']
# 添加字典里的项
k['like'] = 'music'
print k['name']
print k['like']
三、python对象
1、python对象类型
内置的对象类型有:数、字符串、列表、元组、字典、集合等。
在python中,一切皆对象。
2、pickle腌制
在python中如果我们有一些对象需要持久性存储,并且不丢失我们这个对象的类型与数据,则需要将这些对象进行序列化,序列化之后,在需要使用时,我们再恢复为原来的数据。
序列化的这个过程,称为pickle(腌制)。
import pickle
# 方法1:把对象序列化后存储到内存中
# dumps(object) 将对象序列化
lista=["mingyue","jishi","you"]
listb=pickle.dumps(lista)
print listb
# loads(string) 将对象数据原样恢复,并且对象类型也恢复为原来的格式
listc=pickle.loads(listb)
print listc
# 方法2:把对象序列化后存储到第三方文件中
# dump(object,file) 将对象存储到文件中序列化
group1=("bajiu","wen","qingtian")
f1=file("1.pk1","wb") # wb:写入
pickle.dump(group1,f1,True)
f1.close()
# load(object,file) 将dump()存储在文件里面的数据恢复
f2=file("1.pk1","rb") # rb:读取
t=pickle.load(f2)
print t
f2.close()
四、行与缩进
1、逻辑行与物理行
逻辑行:一段代码意义上的行数
物理行:一段代码实际占用的行数
# coding=utf-8
print "abc"; print "789"; print "777" # 1个物理行,3个逻辑行
print '''这里是
北京!
欢迎来玩!''' # 1个逻辑行,3个物理行
2、分号使用规则
每个逻辑行后面必须有分号;每个物理行行末可省略分号(也可不省略)。
3、行连接
1个逻辑行,写在多个物理行,需要使用反斜扛“\”进行行连接。
# coding=utf-8
print "我们都是\
好孩子"
4、缩进
python中,逻辑行行首的空白是有规定的,行首空白不对,会导致程序执行出错。
- 行首不应出现空白
- if和while,缩进一个TAB
a="789"
print a # 报错:IndentationError: unexpected indent
五、运算符
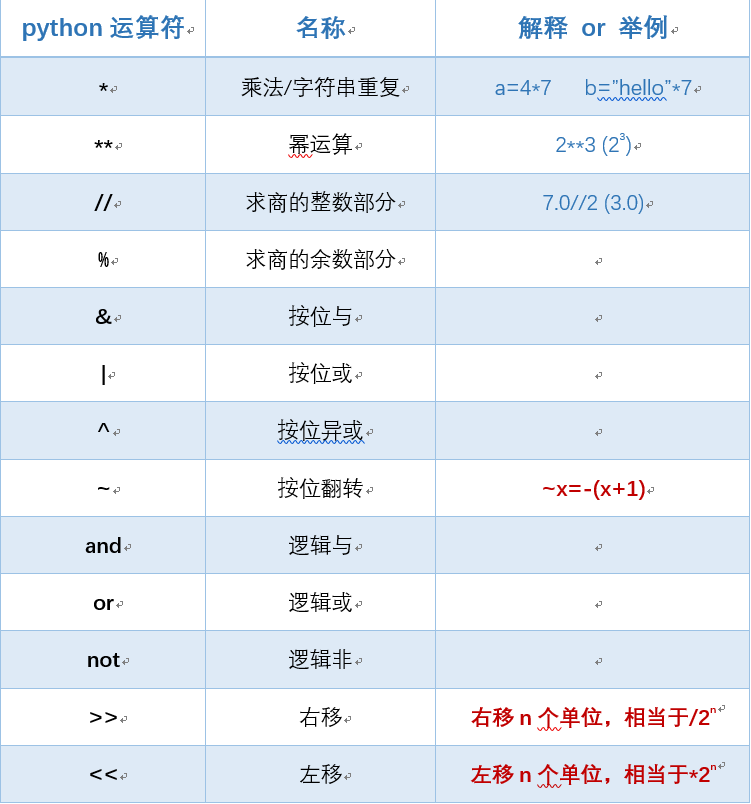
优先级:
- 函数调用、寻址、下标
- **
- ~
- 正负号
- *、/、%
- +、-
- <<、>>
- &、^、|
- 比较运算符
- not、and、or
- lambda表达式
六、控制流
1、for
for i in 集合:
执行该部分
else:
执行该部分
例子:
# One
for i in [1,2,8,9,0]:
print i
#Two
for i in range(1,7): # range()函数的作用:生成一个集合的序列
print i
#Three
for i in range(1,10,2): # range(start,stop,step)
print i
2、if
例子:
for i in range(1,10):
if i%2==0: # 注意:python中比较必须是==,=只做赋值运算符
print "odd"
else:
print "even"
3、while
例子:
a=7
while a:
print "hello"
a=a-1
else: # 注意:python中,while还可以加else
print "world"
4、break
在双层循环语句中,break只能跳出内层循环:
a=10
while a<=12:
a=a+1
for i in range(1,7):
print i
if i==5:
break
如果要跳出多层循环外,要使用标示:
// Java代码
public class BreakTest{
public statis void main(String args[]){
out:
for(int i=0; i<10; i++){
for(int j=0; j<10; j++){
if(j=9){
break out;
}
}
}
}
}
七、函数
1、自定义函数
def 函数名():
函数内容; 函数内容
函数内容
# 例子
def a():
print "hello"
2、参数
参数:函数在执行功能时所要用到的数据。
关键参数:一个函数中出现多个参数时,可通过参数名字直接给参数赋值,这些参数称为关键参数。
def function(a=1,b=6,c=7):
print a
print b
print c
function(5) # 5 6 7
function(b=7,a=8) # 8 7 7
function(5,c=2,b=3) # 5,3,2
function(b=4,c=2,a=1) # 1,4,2
3、全局变量
def func3():
global i
i=7
print i
func3()
4、函数调用
#无返回值
def a():
i=1
a()
#有1个返回值
def test1():
i=7
return i # 代表函数整体值为i
print test1()
#有多个返回值
def test2(i,j):
k=i*j
return (i,j,k) # 元组
x=test2(4,5)
print x # (4,5,20)
y,z,m=test2(4,5) # 分别存储
print y # 4
print z # 5
print m # 20
5、文档字符串
针对函数多了就会杂乱的问题,有2种方法解决:
在开发时为每个函数写一个文档进行说明;
在每个函数开头的地方,加上一行说明性文字,即文档字符串。
每次看到函数时,即可看到文档字符串的说明,很方便。
编写:文档字符串必须写在函数定义的正下方;必须用三引号。
def d(i,j):
'''该函数实现了一个乘法运算。 # 简述函数功能
函数会返回一个乘法运算的结果。''' # 具体功能描述
k=i*j
return k
查看:
# 查看d函数的文档字符串内容
print d.__doc__ # 方法1
help(d) # 方法2
八、python模块
1、什么是模块?
函数:实现一项/多项功能的一段程序。
模块:函数功能的扩展,是实现一类功能的程序块。
模块内可以重用多个函数。
# 模块位置
C:\Python27\Lib
# 后缀名:.py / .pyc
2、标准库模块与自定义模块
标准库模块:python官方提供的自带的模块,伴随python的安装而产生。它是某一类模块,而不是特指某一种模块。
# sys模块是其中一种标准库模块
import sys
sys.version #查看python版本信息
sys.executable #查看当前运行程序的地址
sys.getwindowsversion() #返回当前windows OS的运行环境
sys.modules.keys() #返回当前导入模块的关键字



自定义模块:将自己编写的python程序放在Lib目录下,即成为一个模块。
3、如何导入模块?
import 模块名:导入一个模块
import sys
sys.version #查看python版本信息
from 模块名 import 方法名:不仅导入模块,还导入模块中对应的一个功能(属性或方法)。注意:只能一次导入一个模块的一个功能。
from sys import version
version
4、__name__属性
__name__是系统的一个变量,用于判断一个模块是否是主模块。
if __name__=="__main__":
print "It's main"
else:
print "It's not main"
主模块:一个模块是被直接使用的,而未被调用
非主模块:一个模块被调用(被import了)
主函数:调用其他函数完成一项功能的函数
非主函数:没有调用其他函数的函数
5、dir()函数
python中有非常多的模块,但有时我们会忘记一个模块有哪些功能。此时,可以用dir()函数来查看指定模块的功能列表。

6、字节编译
(1)什么是.pyc文件?
执行python模块的2种方式:
- 先将模块中的内容编译成二进制语言,然后执行这些二进制语言
- 直接执行对应模块的二进制语言程序(省略了编译,速度更快)
字节编译:把模块编译成二进制语言程序的过程。
字节编译会产生一个与编译的模块(.py)对应的二进制文件:.pyc文件
(2)字节编译 vs 编译
编译型语言:软件中有一个独立的编译模块去将程序编译。
python中字节编译是由解释器完成的,因此python仍然是解释型语言。
(3).pyc文件的产生
运行某一模块时,会先找对应的.pyc文件,若有,则直接执行.pyc文件。
# 以zipfile.py模块为例
# 方法1
import zipfile
# 方法2
cd c:\Python27\Lib
python -m compileall zipfile.py
(4).pyc文件的用途
加快了模块的运行速度
可以进行反编译:二进制文件 --> 源文件
使用二进制文件查看器Binary Viewer可以查看.pyc文件的内容。
九、数据结构
python内置的数据结构:元组、列表、字典等。
python扩展的数据结构:栈、队列、树等。
1、栈
class Stack():
def __init__(st, size): #初始化
st.stack=[]
st.size=size
st.top=-1
def push(st, content):
if st.Full():
print "Stack is Full!"
else:
st.stack.append(content)
st.top=st.top+1
def out(st):
if st.Empty():
print "Stack is Empty!"
else:
st.top=st.top-1
def Full(st):
if st.top==st.size:
return True
else:
return False
def Empty(st):
if st.top==-1:
return True
else:
return False
2、队列
class Queue(qu,size):
def __init__(qu,size):
qu.queue=[]
qu.size=size
qu.head=-1
qu.tail=-1
def Full(qu):
if qu.tail-qu.head+1==qu.size:
return True
else:
return False
def Empty(qu):
if qu.head==qu.tail:
return True
else:
return False
def enQueue(qu,content):
if qu.Full():
print "Queue is Full!"
else:
qu.queue.append(content)
qu.tail=qu.tail+1
def outQueue(qu):
if qu.Empty():
print "Queue is Empty!"
else:
qu.head=qu.head+1