原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
原文链接地址:『互联网架构』软件架构-netty高性能序列化协议protobuf(56)
Java默认提供的序列化机制,需要序列化的Java对象只需要实现 Serializable / Externalizable 接口并生成序列化ID,这个类就能够通过 ObjectInput 和 ObjectOutput 序列化和反序列化。
源码:https://github.com/limingios/netFuture/tree/master/源码/『互联网架构』软件架构-io与nio线程模型reactor模型(上)(53)/nio
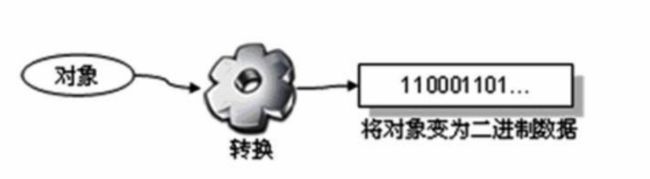
(一)序列化协议基础
目的就是把对象序列化成一堆字节数组,用于网络的传输,序列化存储到磁盘上面。
1.基础类型int在内存中的远生序列化
- Int类型序列化方式
大端序列
先写高位,在写低位
小端序列
先写低位,在写高位
- int 转 byte 是高位在前,低位在后
例如:int value =11。4个字节就是32位。
# value = 11的对应的32位,左边是高位 右边是低位
00000000 00000000 00000000 00001011 = 11
# 0xFF000000 对应的是
11111111 00000000 00000000 00000000
#value & 0xFF000000
00000000 00000000 00000000 00001011
& 11111111 00000000 00000000 00000000
= 00000000 00000000 00000000 00000000
#value & value & 0x00FF0000
00000000 00000000 00000000 00001011
& 00000000 11111111 00000000 00000000
= 00000000 00000000 00000000 00000000
= 00000000 00000000 00000000 00000000
#value & value & 0x0000FF00
00000000 00000000 00000000 00001011
& 00000000 00000000 11111111 00000000
= 00000000 00000000 00000000 00000000
= 00000000 00000000 00000000 00000000
#value & value & 0x000000FF
00000000 00000000 00000000 00001011
& 00000000 00000000 00000000 11111111
= 00000000 00000000 00000000 00001011
最后通过移位后的结果是byte数组[11,0,0,0]
- byte 转 int 是低位在前,高位在后
跟上边是类似的,这里就不在说明了
# 通过 | 等于11
byteArray[0]&0xFF
(byteArray[1]<<1*8) & 0xFF00
(byteArray[2]<<2*8) & 0xFF0000
(byteArray[3]<<3*8) & 0xFF000000
源码:serial\base\serial\Demo01.java
package com.dig8.serial.base.serial;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.util.Arrays;
/**
* 原始int转byte数组
* @author
*/
public class Demo01 {
public static void main(String[] args) throws Exception {
int a = 11;
int b = 22;
int c = 88;
ByteArrayOutputStream os = new ByteArrayOutputStream();
//os.write(a);// 为什么不用这个? 需要写入到磁盘中
os.write(intToBytes(a));
os.write(intToBytes(b));
os.write(intToBytes(c));
byte[] byteArray = os.toByteArray();
System.out.println(Arrays.toString(byteArray));
ByteArrayInputStream is = new ByteArrayInputStream(byteArray);
byte[] aBytes = new byte[4];
byte[] bBytes = new byte[4];
byte[] cBytes = new byte[4];
is.read(aBytes);
is.read(bBytes);
is.read(cBytes);
System.out.println("a: " + bytesToInt(aBytes));
System.out.println("b: " + bytesToInt(bBytes));
System.out.println("c: " + bytesToInt(cBytes));
}
/**
* byte数组转int; 低位在前,高位在后
*/
public static int bytesToInt(byte[] byteArray) {
return (byteArray[0]&0xFF)|
((byteArray[1]<<1*8) & 0xFF00)|
((byteArray[2]<<2*8) & 0xFF0000)|
((byteArray[3]<<3*8) & 0xFF000000);
}
/**
* 将int数值转换为占四个字节的byte数组, 低位在前,高位在后
*/
public static byte[] intToBytes(int value)
{
byte[] byteArray = new byte[4];
// 最高位放在最后一个字节 ,也就是向右移动3个字节 = 24位
byteArray[3] = (byte) ((value & 0xFF000000)>>3*8);// 最高位,放在字节数组最后
byteArray[2] = (byte) ((value & 0x00FF0000)>>2*8);// 左边第二个字节
byteArray[1] = (byte) ((value & 0x0000FF00)>>1*8);
byteArray[0] = (byte) ((value & 0x000000FF)); // 最低位
//[11,0,0,0]
return byteArray;
}
}

2.基于nio的序列化
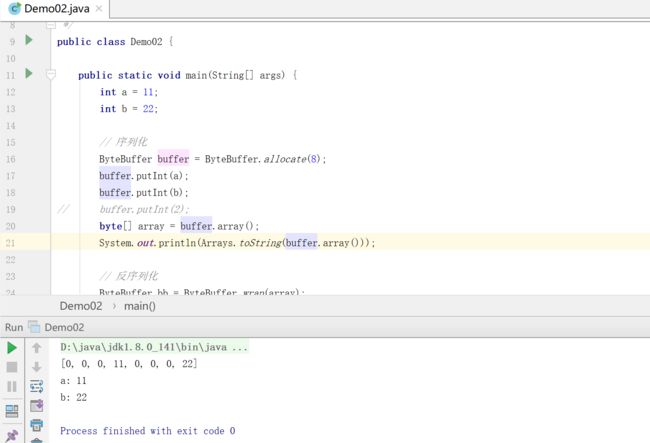
通过jdk自带的nio进行序列化,可以看到几行代码就搞定了
源码:Demo02.java
import java.nio.ByteBuffer;
import java.util.Arrays;
/**
* nio 序列化
* @author
*/
public class Demo02 {
public static void main(String[] args) {
int a = 11;
int b = 22;
// 序列化
ByteBuffer buffer = ByteBuffer.allocate(8);
buffer.putInt(a);
buffer.putInt(b);
// buffer.putInt(2);
byte[] array = buffer.array();
System.out.println(Arrays.toString(buffer.array()));
// 反序列化
ByteBuffer bb = ByteBuffer.wrap(array);
System.out.println("a: " + bb.getInt());
System.out.println("b: " + bb.getInt());
}
}
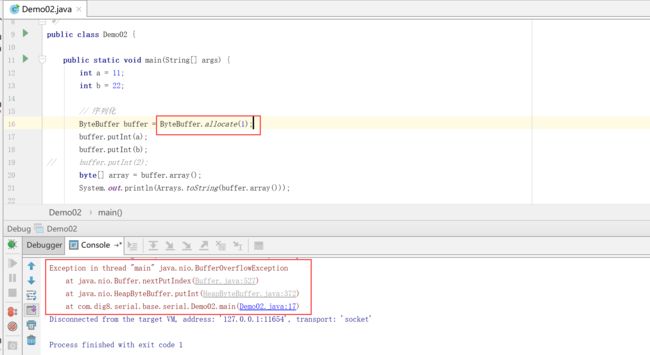
- nio的buffer是固定死的,能够解决复杂的运算,但是不能动态的扩容。
设置长度111,结果int转的byte长达111位

设置长度为1
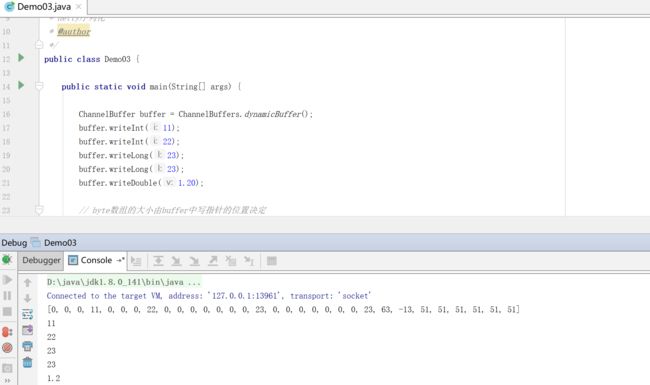
3.基于netty的序列化
netty无需进行长度确定,byte数组的大小由buffer中写指针的位置决定。
源码: Demo3.java
import java.util.Arrays;
import org.jboss.netty.buffer.ChannelBuffer;
import org.jboss.netty.buffer.ChannelBuffers;
/**
* netty序列化
* @author
*/
public class Demo03 {
public static void main(String[] args) {
ChannelBuffer buffer = ChannelBuffers.dynamicBuffer();
buffer.writeInt(11);
buffer.writeInt(22);
buffer.writeLong(23);
buffer.writeLong(23);
buffer.writeDouble(1.20);
// byte数组的大小由buffer中写指针的位置决定
// 往ChannelBuffer中写数据的时候,这个写指针就会移动写的数据的长度
byte[] bytes = new byte[buffer.writerIndex()];
buffer.readBytes(bytes); // 序列化
System.out.println(Arrays.toString(bytes));
// 反序列化
ChannelBuffer wrappedBuffer = ChannelBuffers.wrappedBuffer(bytes);
System.out.println(wrappedBuffer.readInt());
System.out.println(wrappedBuffer.readInt());
System.out.println(wrappedBuffer.readLong());
System.out.println(wrappedBuffer.readLong());
System.out.println(wrappedBuffer.readDouble());
}
}
(二)对象序列化
2.1Java原始对象序列化
- ObjectInputStream 和 ObjectOutputStream
源码:SubscribeReq.java 对象
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
public class SubscribeReq implements Serializable {
private static final long serialVersionUID = 1L;;
private int subReqID;
private String userName;
private String productName;
private List addressList = new ArrayList();
public int getSubReqID() {
return subReqID;
}
public void setSubReqID(int subReqID) {
this.subReqID = subReqID;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getProductName() {
return productName;
}
public void setProductName(String productName) {
this.productName = productName;
}
public List getAddressList() {
return addressList;
}
public void setAddressList(List addressList) {
this.addressList = addressList;
}
@Override
public String toString() {
return "SubscribeReq [subReqID=" + subReqID + ", userName=" + userName + ", productName=" + productName
+ ", addressList=" + addressList + "]";
}
}

java原生的序列化
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* java原始序列化:
* ObjectOutputStream 序列化
* ObjectInputStream 反序列化
*
* @author idig8.com
*/
public class JavaSeri {
public static void main(String[] args) throws Exception{
// 序列化
byte[] result = serialize();
System.out.println(Arrays.toString(result));
// 反序列化
SubscribeReq req = deserialize(result);
System.out.println(req.getSubReqID());
System.out.println(req.getUserName());
System.out.println(req.getProductName());
System.out.println(req.getAddressList().get(0));
System.out.println(req.getAddressList().get(1));
}
// 序列化
public static byte[] serialize() throws Exception{
SubscribeReq req = new SubscribeReq();
req.setSubReqID(1);
req.setUserName("abc");
req.setProductName("netty");
List addressList = new ArrayList();
addressList.add("郑州");
addressList.add("开封");
req.setAddressList(addressList);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(baos);
// 把SubscribeReq对象写入ByteArrayOutputStream中
objectOutputStream.writeObject(req);
// 从ByteArrayOutputStream 获取序列化好的字节数组
byte[] byteArray = baos.toByteArray();
return byteArray ;
}
// 反序列化
public static SubscribeReq deserialize(byte[] byteArray) throws Exception{
ObjectInputStream objectOutputStream = new ObjectInputStream(
new ByteArrayInputStream(byteArray));
SubscribeReq req = (SubscribeReq)objectOutputStream.readObject();
return req;
}
}
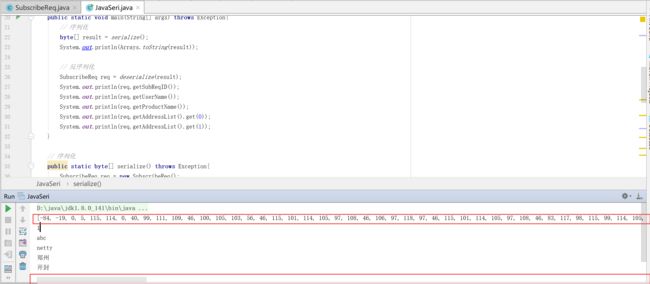
在RPC通信中重点需要关注的2个点
1.码流的大小,也就是解析后的二进制的大小,很明显原生的jdk序列化,字符长度很长,下面的滚动条都很长。数据越多,传输的带宽越大。在项目开发中内网通信的带宽都是固定的,你占的多了,就影响其他人使用带宽。
2.编解码性能,编解码速度越快,肯定就越好。
2.2protobuf序列化
- protobuf
https://github.com/protocolbuffers/protobuf
- 介绍
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
- 使用
源码:https://github.com/limingios/netFuture/tree/master/protobuf
1.同级目录下编写文件
后缀proto,具体的proto这里就不介绍了,可以百度搜下
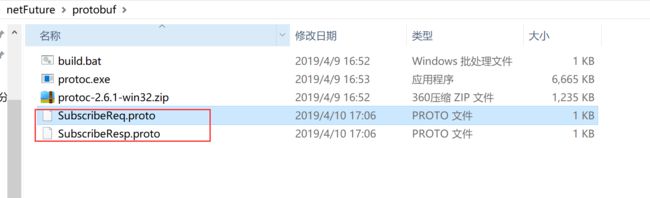
2.双击build.bat 同级目录就会根据proto,生成对应的java代码




3.运行TestProtobuf
/**
*
*/
package com.dig8.serial.protobuf.serial.proto;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import com.google.protobuf.InvalidProtocolBufferException;
import com.dig8.serial.protobuf.serial.proto.SubscribeReqProto.SubscribeReq;
/**
* @author
*/
public class TestProtobuf {
public static void main(String[] args) throws InvalidProtocolBufferException {
byte[] result = serialize();
System.out.println(Arrays.toString(result));
SubscribeReq req = deserialize(result);
System.out.println(req.getSubReqID());
System.out.println(req.getUserName());
System.out.println(req.getProductName());
System.out.println(req.getAddress(0));
System.out.println(req.getAddress(1));
}
/**
* 序列化
* @return
*/
public static byte[] serialize(){
SubscribeReqProto.SubscribeReq.Builder builder = SubscribeReqProto.SubscribeReq.newBuilder();
builder.setSubReqID(1);
builder.setUserName("abc");
builder.setProductName("netty");
List addressList = new ArrayList();
addressList.add("郑州");
addressList.add("开封");
builder.addAllAddress(addressList);
SubscribeReq subscribeReq = builder.build();
return subscribeReq.toByteArray();
}
/**
* 反序列化
* @return
* @throws InvalidProtocolBufferException
*/
public static SubscribeReq deserialize(byte[] bytes) throws InvalidProtocolBufferException{
SubscribeReq result = SubscribeReq.parseFrom(bytes);
return result;
}
}

有老铁说用maven 插件的形式将proto生成java,千万不建议这么弄很熬时间,麻烦死,我这里也不说了,还是用我提供的源码把编辑好一下就生成了。
- 同样的内容 对比java和proto生成的字节数组

可以看出来protobuff的效果太明显了,java是protobuff的6倍。多占用了这么多带宽。在业务系统比较繁忙的系统来说,占用流量就是占用钱。
protobuf占用 1~5个字节
原理:值越小的数字,使用越少的字节数表示
作用:通过减少表示数字的字节数从而进行数据压缩
(三)Netty+Protobuf 测试
- 源码:https://github.com/limingios/netFuture/tree/master/源码/『互联网架构』软件架构-io与nio线程模型reactor模型(上)(53)/nio
这个package com.dig8.serial.protobuf.serial.nettyprotobuf 包下。
源码里面有注释,其实不复杂。看看就懂了。
PS:下次说说编码解码分析,粘包分包现象,其实protobuf确实很牛X,google的开源项目里面基本都有它。
