CentOS下Hadoop+Spark集群环境搭建
硬件环境
虚拟机*3
每台虚拟机配置:系统CentOS6.5 64位,内存1g,硬盘20g。
网络地址:
- master:172.27.35.10
- slave1:172.27.35.11
- slave2:172.27.35.12
软件环境
- java版本:1.8.0_151
- hadoop版本:2.7.6
- spark版本:2.3.0
- scala版本:2.11.12
xshell安装
下载安装xshell,使用SSH远程登录虚拟机。
java安装
1、登录master主机
使用xshell远程登录master主机,登录成功后如下图所示:

2、检查虚拟机网络连接是否正常
可以使用ping命令来检查网络问题:
ping www.baidu.com
如果ping成功,则网络没有问题。
如果ping没有成功,则输入ifconfig,查看网络设置。如果显示如下图:

则说明网卡没有设置启动好,需设置网卡并启动。
修改网卡设置:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改后如图所示:

如上图配置将master主机IP地址设置为静态地址172.27.35.10,其余主机可以参照上述操作将IP地址设置为相应静态地址。
然后配置DNS:
vim /etc/resolv.conf
配置后如图所示:

注意:虚拟机中设置静态IP地址时,网关、子网掩码要和宿主机一样,IP地址也要和宿主机在同一个网段,否则连不上网,桥接模式要记得选择网卡。
配置完成后输入service network restart重启网卡,便可成功连接网络。如果使用的是虚拟机,并且子节点是从其他机器克隆的话,注意修改ifcfg-eht0中的HWADDR硬件地址,并且删除/etc/udev/rules.d/70-persistent-net.rules,这个文件确定了网卡和MAC地址的信息之间的绑定,所以克隆后需删除,待机器重启后重新生成。
3、更新软件包
在终端程序输入以下命令来更新软件包:
yum upgrade
4、安装java
在oracle官网下载对应的jdk,拷贝到master主节点上,这里用的版本为jdk-8u151-linux-x64.tar.gz。
输入解压缩命令:
tar -zxvf jdk-8u151-linux-x64.tar.gz
将解压后文件夹重命名移动到/usr/local/java中(这里软件包都一律安装到/usr/local文件夹中):
mv jdk1.8.0_151/ /usr/local/java
5、配置系统变量
输入命令修改系统配置文件:
vim /etc/profile
在文件末尾输入:
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JRE_HOME/lib
之后保存退出,输入source /etc/profile使配置文件生效。
6、查看java版本
java -version
结果如图所示:

如上,java环境安装配置成功。
7、发送jdk到从节点上
(1) 修改主节点、从节点hosts文件,修改后hosts文件如下图所示:

(2) 配置各个节点ssh免密登陆
在master主节点上输入命令ssh-keygen -t rsa生成公钥,结果如图所示:
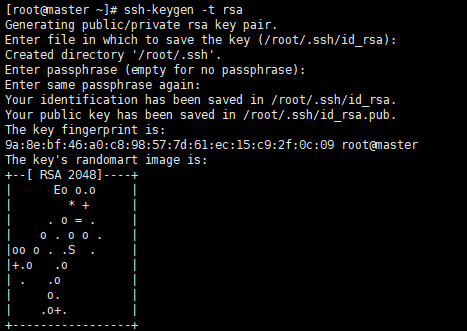
然后输入命令将公钥发送到各个子节点上:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
结果如图所示:

上图所示只是将公钥从master主节点发送到slave1从节点的authorized_keys列表,发送到其他从节点只需改变主机名就可以了。
输入ssh slave1验证是否主节点到从节点免密登陆,结果如图所示:

说明主节点到slave1从节点免密登陆配置成功。
注意:除了配置主节点到各个子节点间免密登陆,我们最好也配置各个子节点到主节点间以及各个子节点间免密登陆,在需要配置到其他节点间免密登陆的主机上按照如上方法操作即可。
(3) 发送jdk到从节点
输入命令scp -r /usr/local/java/ root@slave1:/usr/local/java/,将jdk发送到slave1从节点上,如下图所示:

发送到其他子节点只需修改目标主机名即可。
(4) 配置各个从节点系统变量
参照第5步所示方法。最后输入java -version验证配置是否成功。
Hadoop安装
1、安装Hadoop
到Hadoop官网下载Hadoop安装包,拷贝到主节点上,这里用的版本为hadoop-2.7.6.tar.gz。
输入解压缩命令:
tar -zxvf hadoop-2.7.6.tar.gz
将解压后文件夹重命名移动到/usr/local/hadoop中:
mv hadoop-2.7.6 /usr/local/hadooop
2、配置系统环境变量
输入命令vim /etc/profile,在文件末尾输入如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
之后保存退出,输入source /etc/profile使配置文件生效。
3、hadoop相关文件配置
hadoop配置文件所在目录为$HADOOP_HOME/etc/hadoop,此处HADOOP_HOME为hadoop安装目录,进入hadoop配置文件所在目录,修改相应配置文件。
(1)hadoop-env.sh文件配置
修改JAVA_HOME为当前jdk安装目录:
export JAVA_HOME=/usr/local/java
(2)core-site.xml文件配置如下
fs.default.name
hdfs://master:9000
(3)hdfs-site.xml文件配置如下
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop/hdfs/namenode
dfs.datanode.data.dir
file:/usr/local/hadoop/hdfs/datanode
(4)slaves文件配置如下
slave1
slave2
因为我们没有用到hadoop的yarn与mapreduce,所以hadoop相关配置到此结束。
4、发送hadoop安装包到各个从节点
输入命令scp -r /usr/local/hadoop/ root@slave1:/usr/local/hadoop,将hadoop安装包发送到slave1节点,发送的其他节点只需修改相应主机名即可。
然后修改对应从节点系统变量,方法参照第2步。
5、格式化namenode
在master主节点输入命令hadoop namenode -format格式化namenode,如下图所示:

6、启动hdfs
在master主节点输入命令start-dfs.sh,启动hdfs,如下图所示:

7、检查hdfs是否启动成功
在主节点输入jps,查看已启动的java进程,如下图所示,显示namenode、sercondaryNamenode启动成功:

分别进入各个从节点,查看datanode是否启动成功,如下图所示,则datanode启动成功:
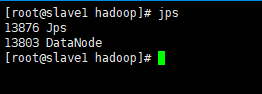
8、hdfs管理界面进入
在地址栏输入http://172.27.35.10:50070,此处172.27.35.10为namenode主机ip,尝试进入hdfs管理界面,如果无法进入,一般是防火墙的问题,可以输入命令service iptables stop关闭防火墙,也可以进一步输入命令chkconfig iptables off关闭防火墙开机自启动,为了集群的顺利运行,可以把集群中的机器防火墙都关闭掉。成功进入hdfs管理界面如下图所示:

scala安装
1、安装scala
在安装Spark之前,我们需要先安装scala,到scala官网下载scala,拷贝到主节点中,此处安装版本为scala-2.11.12.tgz。
输入解压缩命令:
tar -zxvf scala-2.11.12.tgz
将解压后文件夹重命名移动到/usr/local/scala中:
mv scala-2.11.12 /usr/local/scala
2、配置系统环境变量
输入命令vim /etc/profile,在文件末尾添加如下内容:
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
之后保存退出,输入source /etc/profile使配置文件生效。输入scala -version验证安装是否成功,如下图所示:
3、发送scala到从节点
输入命令scp -r /usr/local/scala/ root@slave1:/usr/local/scala,将scala发送到slave1节点,发送到其他节点只需修改相应主机名即可。同时修改系统环境变量,参照第2步。
Spark安装
1、安装Spark
到Spark官网下载Spark,拷贝到主节点中,此处安装版本为spark-2.3.0-bin-hadoop2.7.tgz。解压缩并将解压后文件夹重命名移动到/usr/local/spark中。
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz
mv spark-2.3.0-bin-hadoop2.7 /usr/local/spark
2、配置系统环境变量
输入命令vim /etc/profile,在文件末尾添加如下内容:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
3、spark相关文件配置
spark相关配置文件都在$SPARK_HOME/conf文件夹目录下,此处SPARK_HOME为Spark安装目录,进入Spark配置文件所在目录,修改相应配置文件。
(1)spark-env.sh文件配置
拷贝spark-env.sh.template到spark-env.sh,命令如下:
cp spark-env.sh.template spark-env.sh
spark-env.sh文件配置如下:
export JAVA_HOME=/usr/local/java
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_INSTANCES=2
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://master:9000/historyServerForSpark/logs"
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/usr/local/spark/recovery"
注意:此处历史服务器日志存放地址为hdfs://master:9000/historyServerForSpark/logs,在启动历史服务器前一定要确保该文件夹存在,
可以输入hadoop fs -mkdir -p /historyServerForSpark/logs来创建该文件夹。
(2)slaves文件配置如下
拷贝slaves.template到slaves,命令如下:
cp slaves.template slaves
slaves文件配置如下:
slave1
slave2
(3)spark-defaults.conf文件配置
拷贝spark-defaults.con.template到spark-defaults.conf,命令如下
cp spark-defaults.conf.template spark-defaults.conf
spark-defaults.conf文件配置如下:
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://master:9000/historyServerForSpark/logs
spark.eventLog.compress=true
此处主要是历史服务器相关配置。
4、发送spark安装包到各个从节点
输入命令scp -r /usr/local/spark/ root@slave1:/usr/local/spark,将spark发送到slave节点,发送到其他节点只需修改对应主机名就行。同时修改系统环境变量,参照第2步。
5、启动spark集群
进入SPARK_HOME/sbin目录,输入命令./start-all.sh,结果如下图所示:

6、启动历史服务器
首先确保历史服务器日志存放文件夹已创建,然后进入SPARK_HOME/sbin目录,输入命令./start-history-server.sh,结果如下图所示:
7、检查spark集群、历史服务器是否启动成功
在主节点输入jps,查看已启动的java进程,如下图所示,显示master、historyserver启动成功:

分别进入各个子节点,查看worker是否启动成功,如下图所示,则worker启动成功:

8、进入集群管理、历史服务器管理页面
在浏览器地址栏输入地址http://172.27.35.10:8080,此处172.27.35.10为master ip地址,进入集群管理界面,成功进入如下图所示:

在浏览器地址栏输入地址http://172.27.35.10:18080,进入历史服务器管理界面,成功进入如下图所示:

因为我们还没有跑过程序,所以历史服务器里记录为空。
9、集群测试
下面我们尝试在spark集群中跑个简单的测试程序,进入目录$SPARK_HOME/bin,此处SPARK_HOME为spark安装目录,输入如下命令:
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:6066 \
--deploy-mode cluster \
--supervise \
--executor-memory 1G \
--total-executor-cores 2 \
../examples/jars/spark-examples_2.11-2.3.0.jar \
1000
如下图所示:

然后进入集群管理界面查看应用运行情况,如下图所示:

上图显示应用程序正在运行。
当应用程序运行结束后,进入历史服务器管理界面,如下图所示:

点击相应应用程序,可查看应用程序具体运行情况,如下图所示:
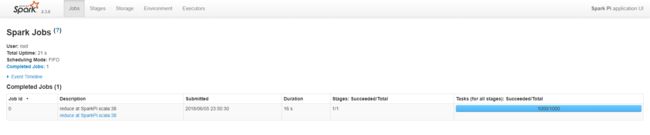
结语
到此CentOS下Hadoop+Spark集群搭建已经成功完成啦,让我们开启愉快的大数据之旅吧!