------------名词解释:
分词:对于中文,由于没有空格,所以需要分词,让程序识别每一个词。英文则不需要。这有现成的工具。
主题抽取:用于抽取文本的分类,一般算法是设置出topic的数量n,抽取出top m个词,这几个词会形成一个topic,常用的方法是TF-IDF,LDA 和 TextRank。然后通过多次调整n的值,获取出一个人认为合理的主题数量。还有一种方法,是通过人工预先标注分类的一些文本来预测当前的文本是什么分类。这些方法都需要通过多次尝试,因为一次算出来的结果可能不是想要的,或者有缺漏。
扩展阅读:https://www.leiphone.com/news/201707/Pe5LRySEwvi6vKiA.html
情感分析:分析出句子的情感是正向还是负向。在分析正负向的时候,首先要分析评价的object,因为人在表达评价的时候,往往是针对不同的object。而分析的目标决定了这些object是什么,所以这个object一般都是由目标驱动的。比如对于餐馆的话,会评价服务、口味、环境和价格,对于产品的话,评价的主要会是质量、设计、服务等。而对于正负向,目前都是通过人工预先标注的正负向的文本,来生成情感值模型计算当前句子的情感值。
扩展阅读:https://zhuanlan.zhihu.com/p/27068121
https://www.zhihu.com/question/20700012
文本摘要:将一片长文章用一句话概括思想。一般用于单主题的文章,可以通过本算法来做。大约的算法是通过分析文章的句子里信息量最大的词,通过预先词库(很大的词库,一般用法是要包含常见的词的所有用法,比如最近几年的新闻和小说文章等)算出的词与词之间的关联权重,重新组成一个句子。
扩展阅读:https://cloud.tencent.com/developer/article/1005548
所有以上的方法,因为出于快速发展期,都没有成熟的套件,所以目前都是写程序来做,而每一项的算法都有很多种,也都各有千秋。这些方法有一个共同点,都需要有一个比较庞大的文章库,和手工标注很多数据。所以对于小数据量并不适用。
-------------------------------------------------------------------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------------------------------------------------
对于小批量数据的话,使用规则效果更好,并且更简单:
有时候,要知道大家对某个产品或者服务的看法,开放性问答必不可少,对于收上来的类似于
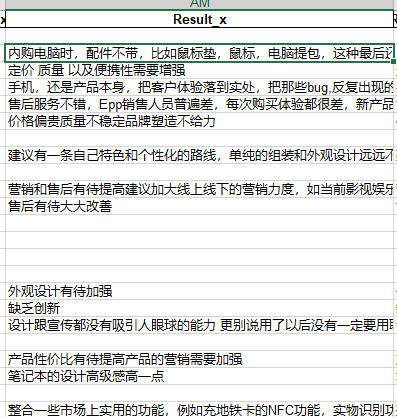
这种文本,众说纷纭。如果少于100条,倒是可以手工一个一个看,根据印象去做分析,但是如果有几百条以上,则必须有一个通用的方法来分析总结这个信息。
但是需求是多变的,像上面的例子,这个描述的对象可能有电脑、配件、手机、销售、售后等,并且语言大部分是中文,少部分的英语和西班牙语。当然,你有时候可能会遇到要分析对于某个产品的看法,那么维度可能就不一样,所以,在做这些问答的分析的时候,第一步是最重要的,就是①确定需求
比如,对于目前的这个例子,我们可以用这样的 方法来确定目标:
(1)我们做这个是为了什么?给谁看,他会关注那些类别?
(2) 我如何确定这么多段话里,究竟说了是10个类别还是20个类别,每个点下面要细分为几个子类?
第一个问题需要自己进行思考,最佳方式是把这这些话全部看一遍,有一个大致的印象,然后猜测报告的接收者关注哪些类别,大概这些类别会包含哪些子类,把这些类别写下来。之后用来根据这些类别来给词归类。
然后正式进入计算了。
②统一语言,如果有其他语言的段落,把它翻译为同一种语言,比如都翻译成中文或者英文。中文和英文的处理方式不一样,本文只讲中文的处理方式。
③对这些句子进行分词,并标注词性
④找出其中的名词,并对这些名词去重,按照出现频率排序,然后依次进行类别标注,这个地方可以根据需求,标注一层或者更多层。
比如,

通过标注之后,基本就可以确定每个句子里包含哪些类别了。
检查分析出的没有类别的句子,需要再次确认,保证不要漏掉有效数据。
如果发现分类不合理,那么需要重新分类。
⑤对句子进行情感分析。
对于已经确定类别的段落,根据句号进行分句子。每个句子可能描述的不同的类别。然后通过情感分析来确定这句话说的是正向的赞扬,还是负向的批评。
情感分析比较麻烦,这个虽然有一些类库可以用,但是普遍由于数据不够全,得出的结果也不尽如人意。此处推荐使用腾讯的NLP接口,由于腾讯是收费的,所以此处可以用爬虫来试用腾讯的情感分析的接口。
http://nlp.qq.com/semantic.cgi
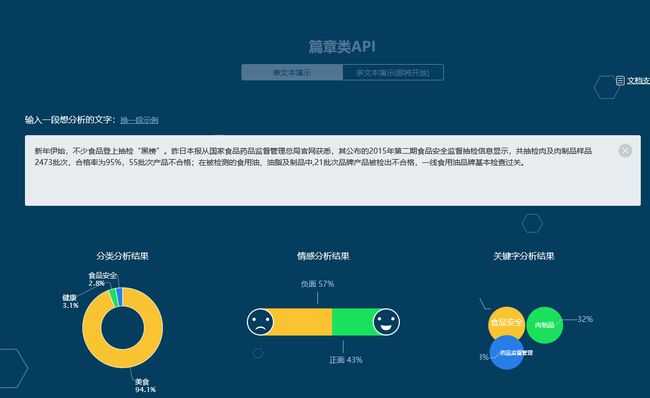
此处之所以不用腾讯的分类分析,也是因为它的分类不满足我们的需求。
⑥情感分析之后,就得出了每个句子的情感指向,那我们就可以进行归类了,比如这句话“”这个电脑质量太差了“的分类是电脑和质量,对应的情感可能是-0.9,那我们就可以归类到电脑和质量里,标明是负向的。
⑦提取每类的观点。归类之后,每一类的句子可以通过情感值分类,并且对正向和负向分别取最高频出现的形容词或副词,用以提取观点。
⑧总结结果:
最终的结果是类似于这样的,
分析结果如下表:总共3783条数据,总体满意度是75%
