Stat参数
一个更加复杂的"stat"会做一些计算。我们可以通过实现一个简单版本的geom_smooth来了解。我们将会创建一个新的图层StatLm(继承自Stat)和一个的图层函数stat_lm():
# 基于ggproto创建StatLm
StatLm <- ggproto("StatLm", Stat,
required_aes = c("x", "y"),
compute_group = function(data, scales){
rng <- range(data$x, nr.rm = TRUE)
grid <- data.frame(x = rng)
mod <- lm(y ~ x, data = data)
grid$y <- predict(mod, newdata = grid)
grid
}
)
# 创建图层函数
stat_lm <- function(mapping = NULL, data = NULL, geom = "line",
position = "identity", na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE, ...){
layer(
stat = StatLm, data = data, mapping = mapping, geom = geom,
position = position, show.legend = show.legend, inherit.aes = inherit.aes,
params = list(na.rm = na.rm, ...)
)
}
调用我们写的stat_lm()图形,检查下效果
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_lm()
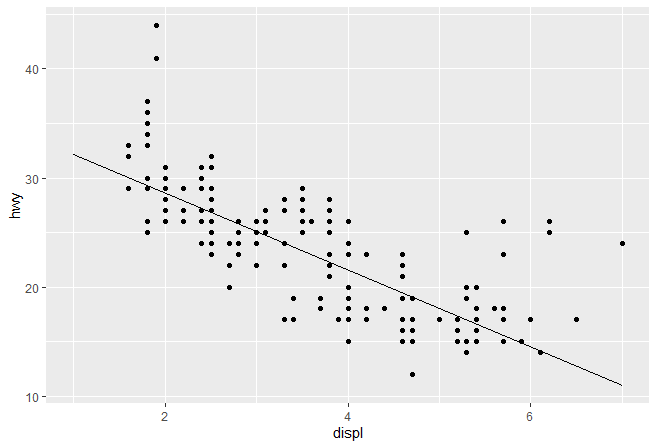
StatLm缺少参数不太灵活,只能做单一线性拟合。最好是允许用户能够自由修改模型公式和创建图层所需要的数据量。为了实现这一需求,我们在compute_group()增加了一些参数,代码如下:
# 增加了参数n和formula
StatLm2 <- ggproto("StatLm2", Stat,
required_aes = c("x", "y"),
compute_group = function(data, scales, params,
n = 100, formula = y ~x){
rng <- range(data$x, na.rm = TRUE)
grid <- data.frame(x = seq(rng[1], rng[2],length = n))
mod <- lm(formula, data = data)
grid$y <- predict(mod, newdata = grid)
grid
})
# 固定模板
stat_lm2 <- function(mapping = NULL, data = NULL, geom = "line",
position = "identity", na.rm = TRUE, show.legend = NA,
inherit.aes = TRUE, n = 50, formula = y ~ x,
...){
layer(stat = StatLm2, data = data, mapping = mapping, geom = geom,
position = position, show.legend = show.legend, inherit.aes = inherit.aes,
params = list( n = n, formula = formula, na.rm = na.rm, ...))
}
# 绘图
ggplot(mpg, aes(displ, hwy)) +
geom_point() +
stat_lm() +
stat_lm2(formula = y ~ poly(x, 10)) +
stat_lm2(formula = y ~ poly(x, 10), geom = "point", colour = "red", n =20)
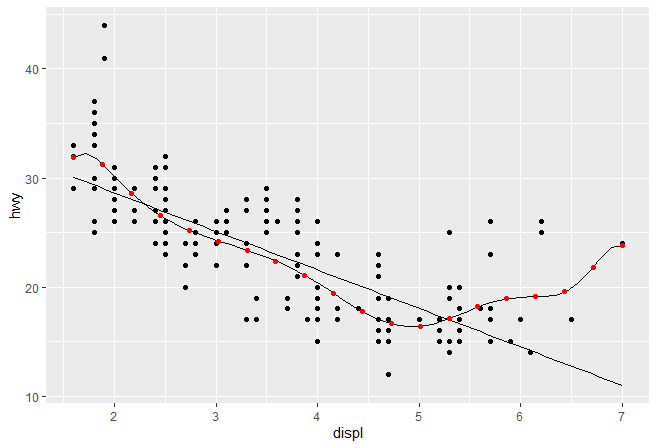
我们并不需要显式在图层中包括新的参数,..会将这些参数放到合适的地方。但是你必须在文档中写出哪些参数是可以让用户调整的,以便用户知道他们的存在。举个一个简单的例子
#' @export
#' @inheritParams ggplot2::stat_identity
#' @param formula The modelling formula passed to \code{lm}. Should only
#' involve \code{y} and \code{x}
#' @param n Number of points used for interpolation.
stat_lm <- function(mapping = NULL, data = NULL, geom = "line",
position = "identity", na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE, n = 50, formula = y ~ x,
...) {
layer(
stat = StatLm, data = data, mapping = mapping, geom = geom,
position = position, show.legend = show.legend, inherit.aes = inherit.aes,
params = list(n = n, formula = formula, na.rm = na.rm, ...)
)
}
上面代码中以#'开头内容都是roxygon语法,其中@inheritParams ggplot2::stat_identity表示在最后输出的帮助文档中会继承stat_identity的参数说明。而@export则是将函数让用户可见,否则用户无法直接调用。
挑选参数
有些时候,你会发现部分运算是针对所有数据集进行,而非每个分组。比较好的方法就是挑选明智的默认值。例如,我们需要做密度预测,我们有理由为整个图形挑选一个带宽(bandwidth)。下面的"Stat"创建了stat_density()的变体,通过选择每组最优带宽的均值作为所有分组的带宽。
StatDensityCommon <- ggproto("StatDensityComon", Stat,
required_aes = "x",
setup_params = function(data, params){
if (!is.null(params$bandwidth))
return(params)
xs <- split(data$x, data$group)
bws <- vapply(xs, bw.nrd0, numeric(1))
bw <- mean(bws)
message("Picking bandwidth of ", signif(bw,3))
params$bandwidth <- bw
params
},
compute_group = function(data, scales, bandwidth = 1){
d <- density(data$x, bw = bandwidth)
data.frame(x = d$x, y = d$y)
}
)
stat_density_common <- function(mapping = NULL, data = NULL, geom = "line",
position = "identity", na.rm = FALSE,
show.legend = NA, inherit.aes = TRUE,
bandwidth = NULL, ...){
layer(stat = StatDensityCommon, data = data, mapping = mapping,
geom = geom, position = position, show.legend = show.legend,
inherit.aes = inherit.aes,
params = list(bandwidth = bandwidth, na.rm = na.rm, ...))
}
ggplot(mpg, aes(displ, colour = drv)) +
stat_density_common()

作者推推荐用NULL作为默认值。如果你通过自动计算的方式挑选了重要参数,那么建议通过message()的形式告知用户(在答应浮点值参数时,用singif()可以只展示部分小数点)。
变量名和默认美学属性
这部分"stat"会阐述另外一个重要的点。当我们想要让当前"stat"对其他geoms更加有用时,我们应该返回一个变量,称之为"density"而不是"y"。之后,我们可以设置"default_aes"自动地将density映射到y, 这允许用户覆盖它从而使用不同的"geom".
StatDensityCommon <- ggproto("StatDentiy2", Stat,
required_aes = "x",
default_aes = aes(y = stat(density)),
compute_group = function(data, scales, bandwidth = 1){
d <- density(data$x, bw= bandwidth)
data.frame(x = d$x , density=d$y)
}
)
ggplot(mpg, aes(displ, drv, colour = stat(density))) +
stat_density_common(bandwidth = 1, geom="point")
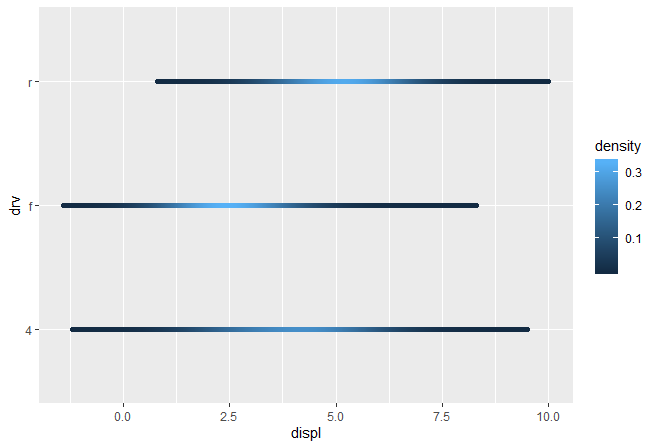
然而直接在stat中用area geom的结果可能和你想的不同。
ggplot(mpg, aes(displ, fill = drv)) +
stat_density_common(bandwidth = 1, geom = "area", position = "stack")
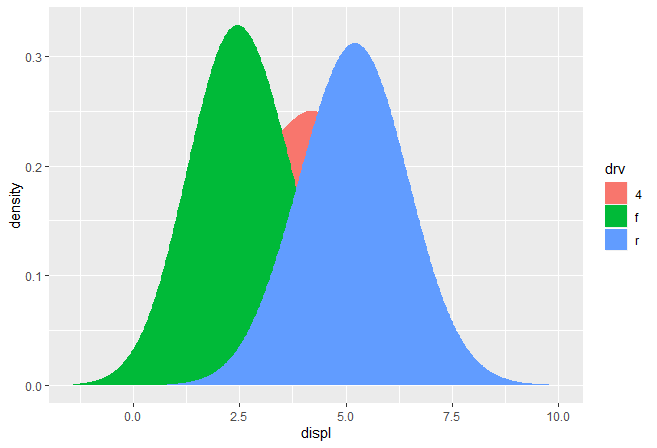
密度不是一个相互累加,而是单独计算,因此预测的x没有对齐。我们可以通过在setup_params()计算数据范围的方式解决该问题
StatDensityCommon <- ggproto("StatDensityCommon", Stat,
required_aes = "x",
default_aes = aes(y = stat(density)),
setup_params = function(data, params) {
min <- min(data$x) - 3 * params$bandwidth
max <- max(data$x) + 3 * params$bandwidth
list(
bandwidth = params$bandwidth,
min = min,
max = max,
na.rm = params$na.rm
)
},
compute_group = function(data, scales, min, max, bandwidth = 1) {
d <- density(data$x, bw = bandwidth, from = min, to = max)
data.frame(x = d$x, density = d$y)
}
)
ggplot(mpg, aes(displ, fill = drv)) +
stat_density_common(bandwidth = 1, geom = "area", position = "stack")
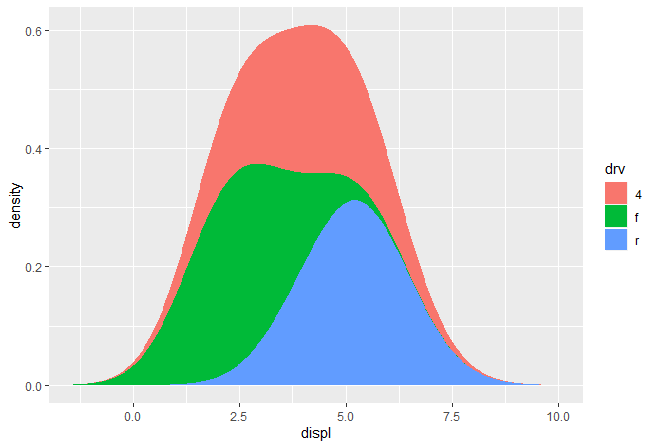
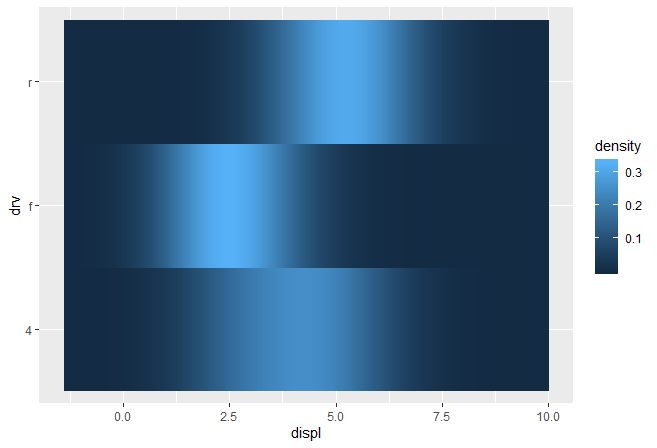
使用"raster"几何形状
ggplot(mpg, aes(displ, drv, fill = stat(density))) +
stat_density_common(bandwidth = 1, geom = "raster")
练习题
- 拓展
stat_chull,使其能够计算alpha hull, 类似于alphahull. 新的"stat"能够接受alpha做为参数 - 修改最终版本的
StatDensityComon, 使其能够接受用户定义的min和max. 你需要同时修改layer函数和compute_group()方法 - 将
StatLm和ggplot2::StatSmooth对比。是什么差异使得StatSmooth比StatLm更加复杂。
版权声明:本博客所有文章除特别声明外,均采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 (CC BY-NC-ND 4.0) 进行许可。
