本文要求读者了解DAGScheduler如何划分一个作业的stages。本文主要内容是作者个人关于spark在提交多个作业时,stage划分的一些小思考。
假设我们有如下图所示的rdd依赖图:
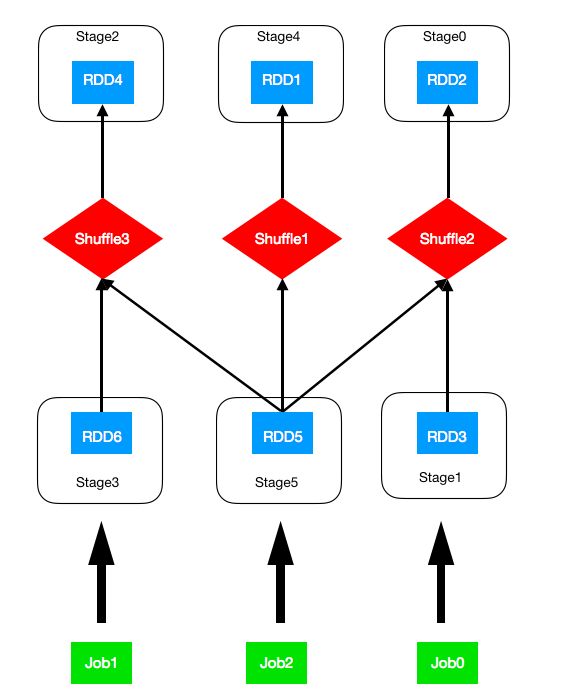
spark-job-submit.png
NOTE:rdd3、rdd6、rdd5分别为job0、job1、job2的final rdd。我们以job0、job1、job2的顺序依次提交这3个作业,得到如图所示的stage划分。(或许你可以自己尝试一下stage划分,看看划分的结果是不是和图中一样。)
关于这张图,简单说两点:
- 第一,图中stage后面的数字表示这3个作业在spark上提交后的真实的stage id。但是,如果我们以job0、job2、job1的顺序依次提交,则RDD1和RDD4的stage id并不可知(注意,我们所说的可知是指告诉job提交的顺序和rdd之间的依赖关系,能够手动划分出和spark一样的stage划分,包括id顺序)。这是因为,spark在划分stages时,会先用一个HashSet来保存RDD的ShuffleDependency。如图所示,RDD5有ShuffleDependency1和ShuffleDependency3。当这两个ShuffleDependency被存储到HashSet中时,则在通常情况下顺序不可知(当然,对于我们例子中的两个shuffle,经过hash结果的顺序还是可知的)。这就导致之后创建的stage的id不可知。
- 第二,一般来说在真实的集群环境中,shuffle时最耗时的。所以在我们提交了job0、job1、job2之后,理论上来说最先执行的3个stage依次会是:Stage0、Stage2、Stage4。假设此时它们正在运行,且其它的stage还没有开始运行。则DAGScheduler的runningStages = (Stage0,Stage2,Stage4 )。且这三个stages又分别对应3个TaskSet,比如TaskSet0, TaskSet1,TaskSet2。如果现在Stage0突然被abort了,那么,接下来执行的是哪个stage呢?答案是Stage3。由于Job0和Job2依赖了Stage0,则Stage0的abort,会导致Job0和Job2被fail掉。而由于Job0和Job2的fail,又会导致正在running的Stage0和Stage4被fail。而Stage5和Stage1则再也没有可执行的机会了。对于Stage2,它被Job1和Job2共同依赖,虽然Job2 fail了,但Job2不会去fail Stage2,因为Stage2还要被Job1所使用。
注:此文对stage abort的描述过于简单,具体abort过程请看我的另一篇文章《Spark之abort stage》。