随着训练数据规模的持续扩大,模型特征的持续增长,常用的机器学习算法面临着越来越多的挑战。从很多人熟悉的R语言,到基于MPI的多机的计算框架,再到支持超大规模特征的Parameter Server架构,再到如今的深度学习计算框架,机器学习平台上的编程模型也在不断演进,以满足业务上持续的挑战。本次主题主要和大家分享PAI分布式机器学习平台的多种编程模型的演进过程。
机器学习在阿里的应用
阿里是一家数据公司,阿里的各项业务都严重依赖机器学习,比如搜索、个性化推荐、精准广告、风控模型、智能客服和物流等多项业务,在使用这些业务的背后都依赖于机器学习。
为了支撑集团业务对机器学习的需求,我们构建阿里云机器学习平台PAI,我们致力于构建阿里集团的统一机器学习平台,该平台致力于建设一站式的数据挖掘建模平台,平台具备的功能如下:
该平台提供完整链路的数据建模服务,包括数据清洗组件、特征处理组件、模型训练组件、模型生命周期管理组件和在线预测服务。通过机器学习平台,完整的从前端数据清洗到最后模型的预测,整个生命周期都可以基于机器学习PAI来做。
阿里数据规模及其庞大,机器学习平台PAI致力于提供先进计算框架,通过技术推动商业的发展,具体支持MapReduce、MPI、Parameter Server和Deep Learning Framework等框架。
编程模型演进
MapReduce编程模型
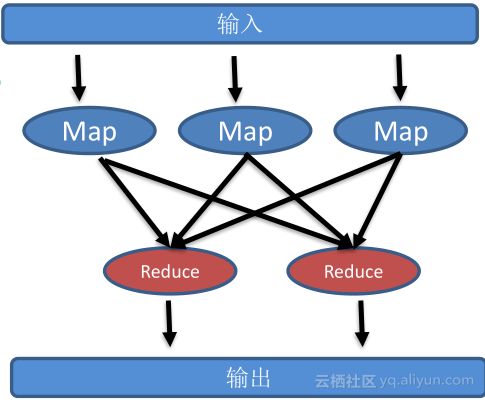
MapReduce编程模型的核心是分而治之,将常见的数据处理抽象成两个操作,Map & Reduce,Map操作就是根据用户数据分片映射成特定输出,后接Reduce对数据进行加工,MapReduce模型之所以非常流行,因为MapReduce在框架层面解决了以下几个分布式难题:
支持计算任务的划分和调度
支持数据的分布式存储和划分
支持计算任务的同步
支持计算节点的容错与恢复
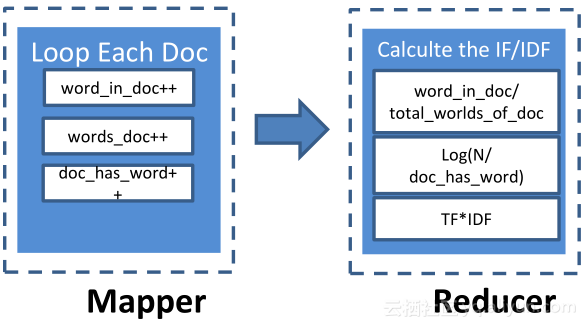
那么,PAI上的算法是怎样基于MapReduce实现的?举例说明:
TF-IDF(term frequency–inverse document frequency),是用来评价某一单词对于某篇文档的重
要性。
• TF = COUNT(Word, Document) / SIZE(Document)代表单个单词在文档中出现次数
• IDF = log(N / docs(Word, Document)代表某单词在所有文档出现的次数
在Mapper里加载每一篇文档,同时我们会遍历这篇文档,统计文档中每个单词出现的频率,统计这篇文档中所有单词的个数,也会统计包含单词的文档个数;在Mapper里实现后,会将相应数据推送到Reducer,在Reducer算子里,会根据某个单词在文档里出现的次数除以这篇文档包含所有单词个数,就会得到term frequyency,然后我们会拿到一个单词出现的次数和所有文档里包含单词的次数,根据公式可以计算出inverse document frequency,将TF与IDF相乘,从而得到某个单词对某篇文档重要性。
和其它机器学习算法相比,MapReduce模型特别适合一些不同计算任务之间独立、数据并行度高的算法,也适合不需要不同节点通信的机器学习算法。
MPI编程模型
MPI全称叫消息传递接口(Message Passing Interface),严格意义来说,MPI并不是编程模型,更多是消息传递接口。MPI定义了很多底层通信接口,包括Send、Receive、Bcast和AllReduce等,MPI库支持单机多Instance和多机多Instance实现,正是由于MPI提供了高度灵活,描述能力强的接口,在过去的一二十年里,在科学计算领域得到大量应用。如今,在分布式计算集群里,也有很多算法可以借鉴MPI进行实现。
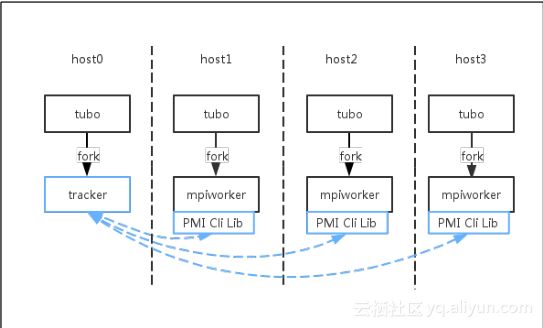
由于MPI计算任务通过底层分布式调度系统动态调度到不同机器上,而跑MPI任务时需要提前知道MPI任务需要运行相应host名字,所以我们对MPI底层网络拖口建立进行了重构,以此适配分布式调度系统。目前PAI机器学习上,支持两个版本的MPI,分别是MPICH (CPU)和OpenMPI (GPU),PAI MPI支持分布式调度,无需事先指定资源,支持本地调试,线上执行。
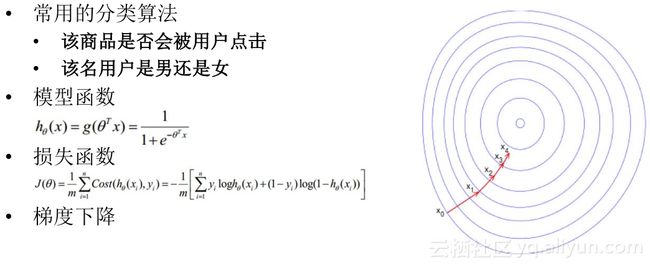
当给客户推荐商品时,会基于逻辑回归模型去判断商品是否会被用户点击,该名用户是男是女,方便给用户推荐商品。根据模型函数建立模型损失函数和梯度函数,图右为模型状态,我们想要收敛到最佳状态的模型,通过多轮迭代达到收敛,得到满意模型。这就要求在每轮迭代间对不同节点之间大家计算出的模型进行通信,进行allReduce的操作。

图为PAI MPI逻辑回归具体实现,假设有N个节点做好数据的分片,在每一轮迭代里会加载用户的训练数据,同时会基于当前模型计算梯度,在本地加和后会调用MPI接口AllReduce,这样,每轮迭代后所有计算节点都会得到新的模型,基于最新模型开始下一轮迭代,就会得到相对较优的逻辑回归模型。
PAI Parameter Server
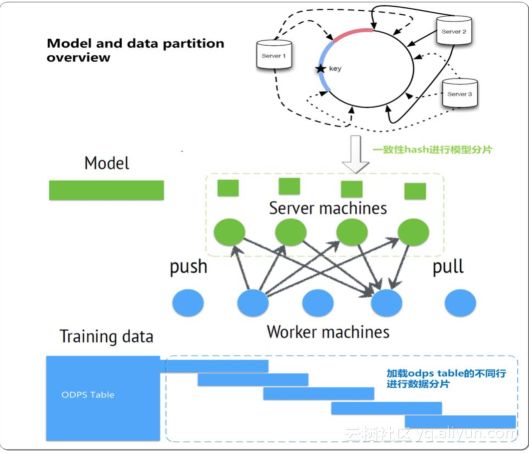
MPI虽然接口灵活,算法实现快,但MPI也有缺点,比如不支持单点容错等。由于模型越来越复杂,训练样本越来越多,特征维数越来越高,对此,阿里独立自研设计实现Parameter Server框架,在集团内大规模使用,框架特点如下:
支持上百亿超大规模特征
支持多种数据切分方式
模型分片
高速通信框架,使得在不同worker和server间数据同步效率提高
优化内存使用
支持节点容错,使得PAI Parameter Server在数千台机器上进行模型训练任务成为可能
Deep Learning深度学习
传统机器学习算法做模型训练时,注意力可能放在训练数据上,放在了数据加工、图形处理上,我们需要更多理解数据,发现新特征;深度学习与常规的机器学习相比,从数据的理解到模型的创新,目前理论上可以证明,神经网络层数越多,层次越深,模型训练效果就会越好,这意味着我们需要支持更深的人工神经网络,更多的参数,更庞大的模型,更高量级的通信量,更灵活的表示模型。
TensorFlow
TensorFlow是谷歌第二代深度学习框架,支持各种神经网络,具备高度的灵活性和丰富的社区生态,支持CNN、RNN、LSTM等网络。
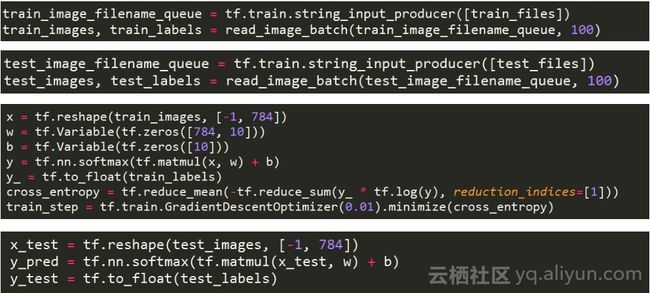
图为一个简单的分类模型,第一块和第二块代码,定义了训练样本和测试样本,第三块定义了模型结构,第四块定义了模型评估的实现,我们会用测试样本评估当前模型准确度。
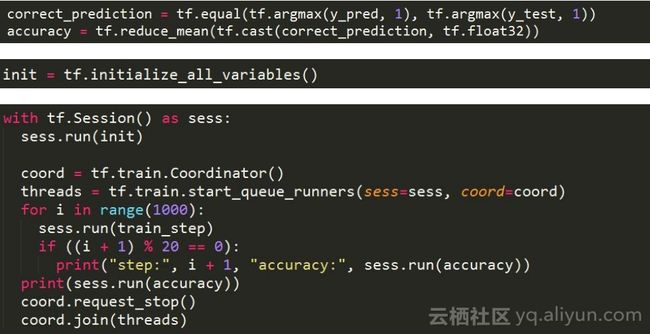
接下来通过TensorFlow session API开始驱动模型训练,可以看出,TensorFlow提供API非常灵活,功能强大。目前在PAI上也提供了TensorFlow的计算服务。
PAI Pluto (多机多卡Caffe)
Caffe在图像领域得到大量使用,是流行的深度学习框架,网络通过有向无环图定义,对于CNN网络可以支持的更好,大量用于图像识别。
我们实现了多机多卡版Caffe,完全兼容Caffe语法,基于OpenMPI通信框架,支持线性加速比,多数据源支持。
机器学习即服务

PAI本身就是机器学习即服务的产品,通过PAI提供包括数据清洗、特征工程、模型训练和模型评价等多套工具。