【云原生】深入浅出 K8s 设备插件技术(Device Plugin)
摘要:Kubernetes 提供了 Device Plugin 机制,用于向 kubelet 上报硬件信息并配置容器资源。本文以 NVIDIA GPU Plugin 为例,通俗易懂 并 深入浅出 地剖析注册、ListAndWatch、Allocate 及 kubelet 管理流程,介绍常见问题和配置要点。
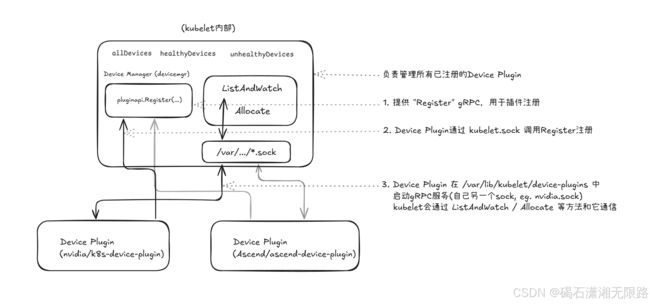
先用一张原理概览图把 Device Plugin 和 kubelet 之间的交互勾勒出来,让大家感受下插件技术的整体架构(示例以 NVIDIA 插件为例):
概念对齐:
kubelet:集群每个节点资源的“管家”
Kubernetes 集群中每个节点上的“管家”,负责管理本节点的容器生命周期(如启动、停止容器),并与 Kubernetes 控制平面通信。Device Plugin 机制扩展了 kubelet 的能力,使其能够管理 GPU 等第三方硬件。
kubelet 与 Device Plugin 之间的通信:sock 文件(Socket)
在 Linux 中,常见的 “.sock 文件” 实际上是一种 Unix 域套接字(Unix Domain Socket)。它类似于网络通信中的 TCP/UDP Socket,但只在本机进程之间进行高效数据交换,不会走网络接口。
在本文中,你会看到 kubelet.sock、nvidia.sock 等文件路径,意味着 kubelet 与 Device Plugin 的所有请求和响应都是通过这些 Socket 文件来传递的。
gRPC:远程过程调用(Remote Procedure Call)框架
当我们说 ListAndWatch、Allocate 等 “RPC 接口” 时,指的是依赖 gRPC 协议来调用。gRPC 让不同进程可以像调用本地函数一样,在 Socket 之间 发送请求、获取结果。
可以简单理解为:“kubelet” 会通知 “插件” 要求列出设备、分配设备,双方都要实现 gRPC 的“请求-响应”流程。
NVML(NVIDIA Management Library)
这是 NVIDIA 官方提供的一套 C 语言库,封装了查询 GPU 信息、监控健康状态等方法。我们常用它获取 GPU UUID、温度、功耗等数据。
许多 NVIDIA GPU Device Plugin 都会依赖 NVML 来确定有哪些 GPU 可用、是否健康。
DaemonSet:在每个节点上运行一个副本
DaemonSet 是 Kubernetes 的一种高级调度机制,可以让某个 Pod 在 集群里每台节点 都有一份副本在运行。
之所以用 DaemonSet 来部署 GPU Device Plugin,是因为我们希望 每个节点上都要启动一个插件,在新增节点的同时自动启动新插件实例,帮助 kubelet 管理当前节点的 GPU。
Container Runtime 与 NVIDIA_VISIBLE_DEVICES
Container Runtime(容器运行时)如 Docker、containerd 等,是在 kubelet 命令下,具体执行 “创建容器、运行镜像” 的软件层。
NVIDIA_VISIBLE_DEVICES 等环境变量,是给 nvidia-container-runtime(NVIDIA 提供的一种特殊容器运行时)用来控制 容器能够使用哪些 GPU。这样可以根据调度分配的 GPU ID,有选择地暴露给容器,而不是让容器看到所有 GPU 资源。
1. 背景:为什么需要 GPU Device Plugin
在 Kubernetes 中,如果我们想让某些容器使用 GPU(或 FPGA、NIC 等特殊硬件),就需要想办法让 kubelet “认识” 这些硬件设备,并且在调度和容器启动时正确地让容器访问到设备。
-
传统方法:在 Kubernetes 1.8 之前,往往需要修改 kubelet 源码来适配具体厂商的硬件,这样一来就会导致:
- Kubernetes 需要内置太多厂商的硬件支持,难以维护;
- 新硬件出来后,想接入 Kubernetes 就必须修改 kubelet,周期长不灵活。
-
Device Plugin 机制:从 Kubernetes 1.8 开始,官方提供了可插拔的 Device Plugin 框架。厂商可以自己实现一个 Device Plugin —— 一个自定义的守护进程(daemon),通过 gRPC 与 kubelet 通信,把硬件信息“上报”给 kubelet。kubelet 不必自带厂商逻辑,只管和这个 Device Plugin 标准对接即可。
因此,NVIDIA 的 GPU Device Plugin(即 nvidia/k8s-device-plugin)就是这么一个“外部插件”。它以 DaemonSet 的方式部署到集群每个节点上,让节点上的 GPU 被 kubelet 发现、上报给 Kubernetes。接下来用户只需要在 Pod spec 里声明 resources.limits.nvidia.com/gpu: 1 就可以使用对应节点上的 GPU 了。
2. Device Plugin 的核心流程概览
2.1 整体流程
- kubelet 启动时,会在
/var/lib/kubelet/device-plugins/kubelet.sock上监听 gRPC 服务,用于 “接受插件的注册”; - NVIDIA Device Plugin 启动时,会跟 kubelet 的
kubelet.sock进行 gRPC 注册(Register()); - 注册成功后,kubelet 就会通过 Device Plugin 内部自己开的 socket(比如
/var/lib/kubelet/device-plugins/nvidia.sock),去调用ListAndWatch了解 GPU 列表,并在有容器需要 GPU 时调用Allocate协商如何设置容器环境变量、挂载、等信息。
对照代码,这个流程最关键的函数有两类:
- Device Plugin 端:
Register(...)(把自己注册给 kubelet)、ListAndWatch(...)(向 kubelet 报告设备列表)、Allocate(...)(提供给 kubelet),等等。 - kubelet 端:内部有一个 Device Manager,对应
ManagerImpl.Register(...)、ListAndWatch(...)回调处理,最终将资源更新到 Node Status。
3. NVIDIA Device Plugin 的关键实现
下面以 nvidia/k8s-device-plugin 为例,结合其 主要函数 以及 简化的核心代码 来看一下每一步是怎么做的。
3.1 代码组织结构概览
常见版本中,代码结构大概如下(只列一些主要文件):
.
├── main.go # 插件入口
├── nvidia_device_plugin.go # 实现 DevicePlugin 接口的核心逻辑
├── nvml # NVIDIA 提供的NVML库封装,用于获取GPU信息
└── ...
main.go 大概就是初始化、启动一个 NvidiaDevicePlugin,并在发现 kubelet 重启时,会重新注册。
nvidia_device_plugin.go 里实现了对 Device Plugin API 的几个接口(ListAndWatch(), Allocate(), …)。
3.2 插件如何启动并注册(Serve → Start → Register)
代码示意(简化):
// main.go 中最核心的逻辑片段:
func main() {
// 1. 初始化 NVML 以获取 GPU 信息
if err := nvml.Init(); err != nil {
log.Fatal("Failed to init NVML")
}
// 2. 监听文件变化(Watch /var/lib/kubelet/device-plugins/kubelet.sock)
// 如果 kubelet.sock 重新被创建,说明 kubelet 重启,需要重新注册
watcher, _ := newFSWatcher(pluginapi.DevicePluginPath)
var devicePlugin *NvidiaDevicePlugin
restart := true
for {
if restart {
// 每次要“重启”时,都先停止旧的,然后重新New、Serve
if devicePlugin != nil {
devicePlugin.Stop()
}
devicePlugin = NewNvidiaDevicePlugin()
err := devicePlugin.Serve() // <-- 核心
if err != nil {
...
}
restart = false
}
// 监听文件事件或系统信号,一旦发现kubelet.sock被删除/新建,就要重启
select {
case event := <-watcher.Events:
if event.Name == pluginapi.KubeletSocket && event.Op&fsnotify.Create == fsnotify.Create {
restart = true
}
...
}
}
}
3.2.1 Serve()
func (m *NvidiaDevicePlugin) Serve() error {
err := m.Start()
if err != nil {
return err
}
// 1. 启动自身 gRPC server(监听 nvidia.sock),并准备好ListAndWatch等实现
// 2. ...
// Register 向kubelet注册:
err = m.Register(pluginapi.KubeletSocket, "nvidia.com/gpu")
if err != nil {
// 若注册失败,停止自己的server
m.Stop()
return err
}
log.Printf("Registered nvidia device plugin with Kubelet")
return nil
}
重点:Serve() 函数里会先 Start()(负责在 /var/lib/kubelet/device-plugins/nvidia.sock 开启 gRPC),再 Register()(把 Endpoint=/var/lib/kubelet/device-plugins/nvidia.sock、ResourceName=nvidia.com/gpu 上报给 kubelet)。
3.2.2 Start()
func (m *NvidiaDevicePlugin) Start() error {
// 1. 先清理旧的 socket 文件
err := m.cleanup()
if err != nil {
return err
}
// 2. 在 nvidia.sock 上启动 gRPC Server
sock, err := net.Listen("unix", m.socket)
if err != nil { return err }
m.server = grpc.NewServer()
pluginapi.RegisterDevicePluginServer(m.server, m) // 注册我们的Server实现
go m.server.Serve(sock) // 开启服务
// 3. 尝试拨号,确保server真的起来了
conn, err := dial(m.socket, 5*time.Second)
if err != nil { return err }
conn.Close()
// 4. 启动GPU健康检查goroutine(见后文healthcheck),用于后续ListAndWatch上报
go m.healthcheck()
return nil
}
- 这里
pluginapi.RegisterDevicePluginServer(m.server, m)就把ListAndWatch,Allocate等接口都“挂载”到 grpc 上了; healthcheck()用来检测 GPU 是否出现 nvmlEventTypeXidCriticalError,一旦检测到某块 GPU 异常,就会在后面ListAndWatch中汇报给 kubelet。
3.2.3 Register()
func (m *NvidiaDevicePlugin) Register(kubeletEndpoint, resourceName string) error {
// 1. 连接到 /var/lib/kubelet/device-plugins/kubelet.sock
conn, err := dial(kubeletEndpoint, 5*time.Second)
if err != nil {
return err
}
defer conn.Close()
// 2. 构造 RegisterRequest
client := pluginapi.NewRegistrationClient(conn)
req := &pluginapi.RegisterRequest{
Version: pluginapi.Version, // v1beta1
Endpoint: path.Base(m.socket), // "nvidia.sock"
ResourceName: resourceName, // "nvidia.com/gpu"
}
// 3. 调用kubelet的 Registration.Register()
_, err = client.Register(context.Background(), req)
return err
}
kubelet 端会在 kubelet.sock 里监听一个 Register(RegisterRequest) 的 gRPC。收到此请求后,kubelet 就记下 ResourceName: nvidia.com/gpu,以及 Endpoint: nvidia.sock。
3.3 kubelet 对接插件:ListAndWatch
一旦注册成功,kubelet 会反过来拨号 /var/lib/kubelet/device-plugins/nvidia.sock,调用 ListAndWatch() 来获取设备列表,并持续接收设备健康状态更新。
在 NVIDIA 插件中,ListAndWatch() 代码大概如下(简化):
func (m *NvidiaDevicePlugin) ListAndWatch(_ *pluginapi.Empty,
s pluginapi.DevicePlugin_ListAndWatchServer) error {
// 1. 第一次调用时,立刻把当前所有GPU列表发送给kubelet
s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
// 2. 然后死循环,监控health管道
for {
select {
case <-m.stop:
return nil
case d := <-m.health:
// 若某块GPU出现异常,就更新它的Health=Unhealthy
d.Health = pluginapi.Unhealthy
// 把最新的 m.devs(带Unhealthy的)再发给kubelet
s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
}
}
}
m.devs里保存了 GPU 的ID(通常是 GPU UUID)以及其Health(默认Healthy);- 当检测到某块 GPU 出了故障,就把它标记为
Unhealthy,再刷新发给 kubelet,kubelet 就会减少可用 GPU 数量,并更新 Node Status; - kubelet 这边 有个对应的“长连”处理,会反复接收
ListAndWatchResponse,更新其本地缓存。
3.4 容器启动:Allocate
当用户创建一个 Pod,需要 nvidia.com/gpu: 1 之类的资源时,调度器把该 Pod 分配给节点后,kubelet 在 创建容器 的流程里会调用 Device Plugin 的 Allocate() 来获取容器运行时需要的一些配置信息,比如 环境变量 / Mount / Device 映射等等。
func (m *NvidiaDevicePlugin) Allocate(ctx context.Context,
reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
responses := pluginapi.AllocateResponse{}
for _, req := range reqs.ContainerRequests {
// 1. 拿到Container请求使用的 GPU ID 列表
devIDs := req.DevicesIDs
// 2. 构造 ContainerAllocateResponse
resp := &pluginapi.ContainerAllocateResponse{
Envs: map[string]string{
// NVIDIA_VISIBLE_DEVICES 是nvidia-container-runtime识别的变量,
// 指定容器可见的GPU
"NVIDIA_VISIBLE_DEVICES": strings.Join(devIDs, ","),
},
}
// 3. 这里也可添加 Mounts, Devices, 等信息(若需要访问 /dev/nvidiaX )
// resp.Devices = ...
// resp.Mounts = ...
responses.ContainerResponses = append(responses.ContainerResponses, resp)
}
return &responses, nil
}
- 可以看到,NVIDIA 的做法比较简单,主要就是把
DevicesIDs打包到NVIDIA_VISIBLE_DEVICES环境变量,依靠 nvidia-container-runtime 的机制让容器只看见指定 GPU; - 有些其他 Device Plugin,会在
resp.Devices字段里声明要挂载/dev/specialX到容器里,或者设置更多Annotations等。这都取决于硬件的实际接入方式。
3.5 小结:NVIDIA Device Plugin 的基本逻辑
-
启动阶段:
- 监听
/var/lib/kubelet/device-plugins/kubelet.sock重建事件,如果 kubelet 重启,会重新向 kubelet 注册; - Serve:自己在
nvidia.sock开 gRPC 服务,实现ListAndWatch,Allocate等。
- 监听
-
ListAndWatch 阶段:
- 一开始就把可用 GPU 全部上报(
Healthy); - 后续如果发现 GPU 故障,就把该 GPU 标为
Unhealthy并再次上报。
- 一开始就把可用 GPU 全部上报(
-
Allocate 阶段:
- Pod/container 要使用 GPU 时,kubelet 调用本方法;
- Plugin 返回对容器的改动(通常是设置
NVIDIA_VISIBLE_DEVICES环境变量,加上/dev/nvidia*访问权限),让容器能正确访问到对应 GPU。
4. 深入K8s内部 设备上报与调度协同原理
在前文中,我们已经重点介绍了:Device Plugin 如何通过 ListAndWatch 和 Allocate 告诉 kubelet 自己有多少设备、分配设备时要怎么配置容器。本节我们再补充一下和 调度器 的配合机制,从而串联起一个 Pod 从“请求 GPU 资源”到“成功使用 GPU 设备”的完整流程。
4.1 kubelet 对不同设备的统一抽象
首先,kubelet 内部有一个 Device Manager(位于 pkg/kubelet/cm/devicemanager/)。它的核心思路是:
- 不管什么品牌或类型的硬件(GPU、FPGA …),只要 Device Plugin 使用了
Register()报告ResourceName,kubelet 便将这类硬件视为 统一的“可分配资源”; - kubelet 会把这些资源更新到 Node Status 中——比如
nvidia.com/gpu: 4,然后在调度时,Scheduler 就会用通用的 资源匹配逻辑 来判断 “哪个节点满足nvidia.com/gpu >= 1” 等; - 在容器启动阶段,kubelet 会再次调用 Device Manager 的 Allocate(其实是去调用具体的 Plugin 的 Allocate),由插件告诉它如何“挂载”或“配置”真正的硬件。
为了让你清楚 kubelet 的这种 “统一抽象” 是怎么实现的,可以看一下 kubelet 源码中 ManagerImpl 的几个关键数据结构(简化):
type ManagerImpl struct {
allDevices map[string]map[string]pluginapi.Device
healthyDevices map[string]sets.String
unhealthyDevices map[string]sets.String
...
}
allDevices:保存了所有插件上报的设备,map[ResourceName] -> map[DeviceID] -> Device信息;healthyDevices:记录每个 ResourceName 下,哪些设备ID是 Healthy 状态;unhealthyDevices:记录每个 ResourceName 下,哪些设备ID是 Unhealthy 状态。
当 plugin 通过 ListAndWatch 告知 kubelet 设备列表时,kubelet 会调用下面这样的方法进行更新:
func (m *ManagerImpl) PluginListAndWatchReceiver(resourceName string, resp *pluginapi.ListAndWatchResponse) {
var devices []pluginapi.Device
for _, d := range resp.Devices {
devices = append(devices, *d)
}
m.genericDeviceUpdateCallback(resourceName, devices)
}
func (m *ManagerImpl) genericDeviceUpdateCallback(resourceName string, devices []pluginapi.Device) {
// 遍历该插件发来的所有设备
for _, dev := range devices {
m.allDevices[resourceName][dev.ID] = dev
if dev.Health == pluginapi.Healthy {
m.healthyDevices[resourceName].Insert(dev.ID)
} else {
m.unhealthyDevices[resourceName].Insert(dev.ID)
}
}
// ...
}
然后 kubelet 会在更新 Node Status 的阶段,把 healthyDevices 的数量当作该节点的可用容量,比如 nvidia.com/gpu: 4。这就是为什么 scheduler 能看到这个节点有 4 个 GPU 可以用——因为 kubelet 做了“抽象”,把真实的硬件数量记到 Node.Status.Allocatable 里。
4.2 调度原理:统一的资源 Filter
当一个 Pod 需要 GPU 资源时(例如 nvidia.com/gpu: 1),调度器并不需要有什么特殊的 GPU 逻辑,它只是在 Filter 阶段检查:
- Node 上分配出去的
nvidia.com/gpu有多少? - Node 上的可用剩余是否 >= 1?
如果满足,就认为 “在资源层面” 通过了。这部分可参考调度器的源码(示例):
func (f *Fit) Filter(ctx context.Context, cycleState *framework.CycleState,
pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
// 1. 先汇总 podRequest: Pod 需要的 CPU/Memory/... 以及 Extended Resource (如 nvidia.com/gpu)
podRequest := calculatePodResourceRequest(pod)
// 2. 比较 nodeInfo 上的可用资源 vs. podRequest,如果不足,就返回失败
insufficientRes := fitsRequest(podRequest, nodeInfo, ...)
if len(insufficientRes) > 0 {
// 代表某些资源不足
return framework.NewStatus(framework.Unschedulable, "...")
}
return nil
}
func fitsRequest(podRequest *preFilterState, nodeInfo *framework.NodeInfo, ...) []InsufficientResource {
...
for rName, rQuant := range podRequest.ScalarResources {
if rQuant > (nodeInfo.Allocatable.ScalarResources[rName] - nodeInfo.Requested.ScalarResources[rName]) {
// 资源不足
insufficientResources = append(insufficientResources, InsufficientResource{ ResourceName: rName, ... })
}
}
...
}
- 当
rName是"nvidia.com/gpu"时,这里就去比对 “Node 上 GPU 的 Allocatable - 已分配量” 是否够。 - 若够,就留在候选节点里。调度器然后可能再用其它 Plugin(如 优先级、亲和性 等)来选择最优节点。
由此可见,在调度阶段,插件对接 的 GPU 资源会跟 CPU/Memory 一样被当作“资源”来 Filter,没有特殊专门的 GPU 调度逻辑。
4.3 调度成功后 kubelet 的 Allocate 调用
当调度器最终确定 某节点 能满足 Pod 需求,Pod 就被 绑定 到该节点上。
然后,该节点上的 kubelet 启动容器前,会在 “Device Manager → Plugin” 调用 Allocate(),让 plugin 返回如何设置容器。NVIDIA plugin 这里,就会返回 NVIDIA_VISIBLE_DEVICES 环境变量,或 /dev/nvidia* 等特定挂载,让最终的容器只看到被分配到的 GPU。
简化示意(对照前文):
- Scheduler:判断 “nvidia.com/gpu” 是否够用 → 选中节点X;
- kubelet(节点X):接收到调度结果 → 创建容器 → 调用 Device Manager → 进而调用插件的
Allocate(); - plugin 返回 GPU ID 对应的挂载配置/环境变量 → kubelet 设置到容器 → 容器启动后就能使用那几块 GPU。
4.4 小结:Device Manager 的基本逻辑
- kubelet 启动时 会初始化一个
DeviceManager(在/var/lib/kubelet/device-plugins/kubelet.sock开启一个 gRPC server),等着外部的 Device Plugin 来 “Register()”。 - 插件注册后:kubelet 使用一个内部的
endpointImpl去拨号插件的 socket(例如nvidia.sock),调用ListAndWatch(),拿到 GPU 列表。 - 更新 Node 状态:kubelet 把 GPU 数量更新到 Node Status 中,比如
nvidia.com/gpu = 4。 - 容器创建时:kubelet 要检查 Pod 的资源需求,调用
Allocate()获取容器启动参数(环境变量 / 设备挂载 / …),最终把这些注入到容器 runtime。
5. NVIDIA 设备插件关键点与常见问题
- 必须要把 Docker 的默认 runtime 设置为 nvidia
- 在
/etc/docker/daemon.json里,"default-runtime": "nvidia", 并配置好 nvidia-container-runtime,这样容器启动时才可以识别并正确加载 GPU 驱动;
- 在
- 如果容器加了特权(privileged: true),可能导致
NVIDIA_VISIBLE_DEVICES失效,容器会看到所有 GPU,这就违背了 Kubernetes “整卡分配” 的隔离逻辑; - NVIDIA 版本兼容
- 官方推荐
NVIDIA drivers >= 384.81,nvidia-docker >= 2.0,并且 Kubernetes 版本 >= 1.10 等;
- 官方推荐
- 虚拟化 GPU
- 如果只想 “假装” 有更多 GPU 给调度用(但实际上共享同一张卡),就需要在
ListAndWatch()阶段把一张 GPU 虚拟成多张 ID,然后在Allocate()里做对应的合并映射。业界也有更复杂的 GPU 虚拟化方案(比如 vGPU);
- 如果只想 “假装” 有更多 GPU 给调度用(但实际上共享同一张卡),就需要在
- PodResources 接口
- 对于监控 GPU 使用,你可以访问 kubelet 提供的
/var/lib/kubelet/pod-resources/kubelet.sock的ListgRPC 来查询哪些 Pod 正在使用哪些 GPU 设备,这个属于 “PodResources API”。
- 对于监控 GPU 使用,你可以访问 kubelet 提供的
6. 结语
通过以上分析过程,我们可以看到 GPU Device Plugin 的总体原理相对清晰:
- 插件负责:
- 获取真实硬件信息(如调用 NVML 取 GPU UUID)
- 在本机开一个 gRPC 服务,提供
ListAndWatch,Allocate等接口 - 向 kubelet 注册自己
- 持续检测硬件健康,并向 kubelet 实时汇报
- kubelet 负责:
- 接收注册请求、与插件建立长连
- 把设备信息更新到 Node Status
- 在容器启动时调用
Allocate()让插件告诉它怎么配置容器 - 确保集群调度、资源分配符合“整卡”模型(或厂商自定义模型)
因为 Device Plugin 框架将 “硬件逻辑” 和 “kubelet 核心” 解耦,厂商可以各自实现插件,大大降低了 Kubernetes 自身的复杂度。NVIDIA/k8s-device-plugin 即是其中的一个典型实现,也是目前使用最广泛的 GPU Plugin。
参考链接
- NVIDIA/k8s-device-plugin 源码仓库
- Kubernetes 官方文档: Device Plugins
- NVIDIA 容器文档(nvidia-container-runtime)
- NVML API 文档