面试core java,HashMap的结构差不多是必问题了。字面意思,真的真的是必问题了。
我遇到的问题有:
1. HashMap, ConcurrentHashMap,HashTable 的结构,在JDK 1.7 和1.8 中有什么不同(最基础)
2. put时,是加到链表头还是链表尾
3. get的时间复杂度(对链表,对红黑树)
然后,在一次糟心的面试中,面试官问问题1 ,我回答了,提到了loadfactor = 0.75, 对方来了句“这个都记,背得挺熟的嘛” , 我:???(黑人问号脸)。
他问,那你说,为什么是0.75 , 不是0.5或者1?
这个好回答。 如果是0.5 , 那么每次达到容量的一半就进行扩容,默认容量是16, 达到8就扩容成32,达到16就扩容成64, 最终使用空间和未使用空间的差值会逐渐增加,空间利用率低下。 如果是1,那意味着每次空间使用完毕才扩容,在一定程度上会增加put时候的时间。
接着,他问我为什么是0.75,不是0.6或者0.8?
我:……
========================
面试只是检测知识的一个经历。 回头再想想:那为什么是0.75呢? 0.75是 0.5 ~ 1的中间值? (写到这里,突然想这样解释也可以哎,取中间值)
然后我去查看了API...
JDK 1.7中:
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
翻译过来就是:
作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。
JDK 1.8中也有上述内容,并且还有一段如下(现在头脑清醒了,觉得下面这段与“为什么是0.75”关系不大,不过是百度中能找到的关于这个问题的别人的文章中有着一段):
Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) pow(0.5, k) / factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
简单翻译一下,就是 :
理想状态下,在随机哈希值的情况,对于loadfactor = 0.75 ,虽然由于粒度调整会产生较大的方差,桶中的Node的分布频率服从参数为0.5的泊松分布。
(泊松分布算是我在这个没什么意思的探讨中学到的新的知识点吧,比较通俗易懂的解释在这里 )
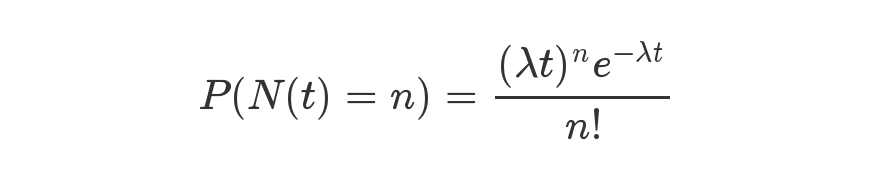
在上面给出的结果中,t=1,λ=0.5,推算得各种结果。这个我自己写程序实现了一下,没错。但这个地方跟0.75没关系,实际上是在JDK1.8中,如果链表的长度大于8,那么链表转为红黑树 这个操作得来的。
那么,回到问题,0.75是怎么得来的呢?StackOverFlow上有这么一个回答我觉得可以给我结案了:
原链接如下:What is the significance of load factor in HashMap?
这个回答的释义是: 一个bucket空和非空的概率为0.5,通过牛顿二项式等数学计算,得到这个loadfactor的值为log(2),约等于0.693. 同回答者所说,可能小于0.75 大于等于log(2)的factor都能提供更好的性能,0.75这个数说不定是 pulled out of a hat。
==========================
昨天和我学金融的着重号朋友讨论这个问题,最后她说
其实我就是不喜欢面试官阴阳怪气地说一句“这都背下来了”,你说你考我问题,又觉得我是背的,那你期待我怎么表现??回答不上来?哎,过去就过去了。
总结一下:
为什么是0.75? 这个我没找到一个肯定完整的答案,这个问题比较偏,问到的几率很小。但经过探讨,你可以回答
1. 取 0.5和1 的缺点是什么, 同时说一下上面第一段引用的JDK API,就说API中也没有说为什么取0.75.
2. 对方如果是个杠精,你可以深入理解一下stackoverflow中的这个计算,然后告诉他。 如果对方考你高数……我也没办法了,记得来我这里领一个爱的抱抱。
============================
学到了什么:
1. 泊松分布和指数分布,顺便回想一下正态分布
2. 气场不和的面试官要用正确的心态去面对。