本文由巨杉数据库北美实验室资深数据库架构师撰写,主要介绍巨杉数据库的并发malloc实现与架构设计。原文为英文撰写,我们提供了中文译本在英文之后。
SequoiaDB Concurrent malloc Implementation
Introduction
In a C/C++ application, the dynamic memory allocation function malloc(3) can have a significant impact on the application’s performance. For multi-threaded applications such as a database engine, a sub-optimal memory allocator can also limit the scalability of the application. In this paper, we will discuss several popular dynamic memory allocator, and how SequoiaDB addresses the dynamic memory allocation problem in its database engine.
dlmalloc/ptmalloc
The GNU C library (glibc) uses ptmalloc, which is an allocator forked from dlmalloc with thread-related improvement. Memories are allocated as chunks, which is 8-byte aligned data structure containing a header and usable memory. This means there is at least an 8 or 16 byte overhead for memory chunk management. Unallocated memory is grouped by similar sizes and maintained by a double-linked list of chunks.
jemalloc
Originally developed by Jason Evans in 2005, jemalloc has since been adopted by FreeBSD, Facebook, Mozilla Firefox, MariaDB, Android and etc. jemalloc is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support. In order to avoid lock contention, jemalloc uses separate memory pool “arenas” for each CPU, and threads are assigned to an arena to handle malloc requests.
tcmalloc
TCMalloc is a malloc developed by Google. It reduces lock contention for multi-threaded programs by utilizing thread-local storage for small allocations. For large allocations, mmap or sbrk can be used along with fine grained and efficient spinlocks. It also has garbage-collection for local storage of dead threads. For small objects allocation, TCMalloc requires just one-percent space overhead for 8-byte objects, which is very space-efficient.
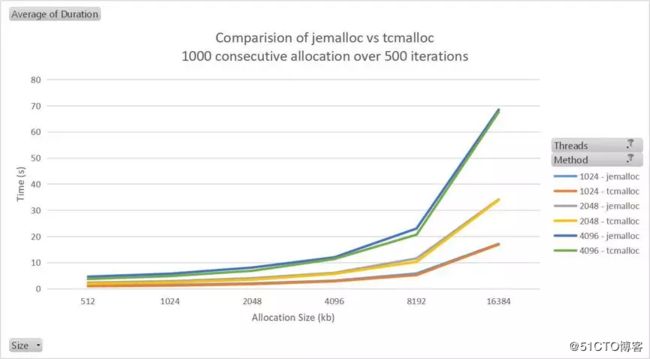
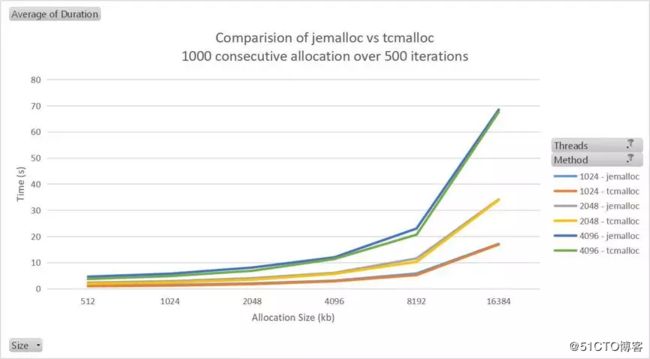
Here is a test done to compare the performance of jemalloc and tcmalloc. The test involves 500 iterations of performing 1000 memory allocation, then free these 1000 memory. As seen both of them have very similar performance.
SequoiaDB Implementation
In SequoiaDB 3.4, it implements its own proprietary memory allocator, which is highly efficient and tailored for the memory usage within the SequoiaDB database engine. While jemalloc and tcmalloc are both excellent general purpose memory allocator, they cannot address all the challenges that are encountered within SequoiaDB. For example, the ability to trace memory requests is an important requirement in SequoiaDB engine, and this feature is lacking in existing third-party memory allocators. Figure 2 shows the architecture of the SequoiaDB memory model. There are three layers - thread, pool and OSS (Operating System Services).
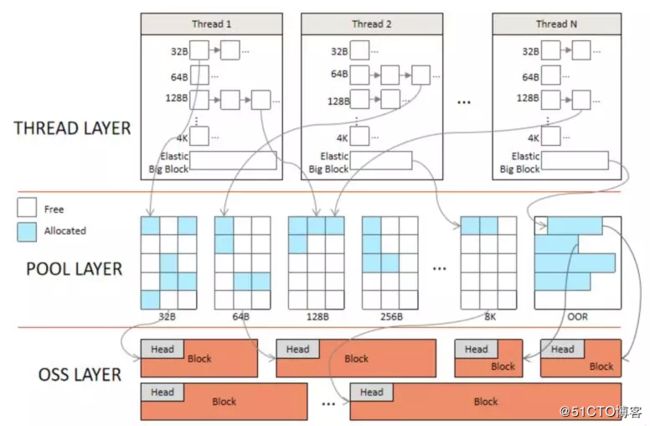
OSS Layer
The OSS layer provides malloc API which requests memory from the underlying operating system. This is also where the pool layer gets the memory from.
Pool Layer
The pool layer is a global memory pool which contains segments of different size. A segment is a contiguous memory block that is allocated from the OSS Layer. Each segment is divided into fixed-size chunks. By default there are 32-byte, 64, 128…8092-byte chunk-size. Requests above the 8092-byte max chunk-size threshold will be serviced by the OSS layer.
Thread Layer
The thread layer is a thread-local cache, with each thread having its own private cache, therefore memory allocation can be done in a lock-free manner. Memory chunks are grouped together by their chunk size, implemented using a linked-list. Memory chunks are requested and cached from the pool layer up to a configured threshold. For memories exceeding this threshold, they are released back to the pool layer, and can be reused by other threads. This design helps limit the overall memory footprint. In addition, each thread has a single elastic-big-block, which is used to service requests above max chunk-size threshold. Therefore, in most cases requests can be fulfilled in the thread layer, which is efficient and fast.
In addition, the SequoiaDB memory model also has built-in memory-debugging capability to detect memory corruption. It also has a trace feature which can track down where memories are being requested from. On top of that, it is fully configurable, and allow deployment to be customized according to customers workload and environment.
以下为中文译本
介绍
在 C / C ++ 应用程序中,动态内存分配函数 malloc(3) 会对应用程序的性能产生重大影响。对于诸如数据库引擎之类的多线程应用程序,优化不足的内存分配器也会限制应用程序的可伸缩性。在本文中,我们将讨论几种流行的动态内存分配器,以及 SequoiaDB 如何解决其数据库引擎中的动态内存分配问题。
dlmalloc/ptmalloc
GNU C 库 (glibc) 使用 ptmalloc,它是从 dlmalloc 派生的具有线程相关改进的分配器。内存被分配为块,这是 8byte 对齐的数据结构,其中包含标头和可用内存。这意味着内存块管理至少有 8 或 16byte 的开销。未分配的内存按相似的大小分组,并由块的双向链接列表维护。
jemalloc
jemalloc 最初由 Jason Evans 于2005年开发,此后已被 FreeBSD,Facebook,Mozilla Firefox,MariaDB,Android 等采用。jemalloc 是通用的 malloc(3) 实现,主要特点是避免碎片化和可扩展的并发支持。为了避免锁竞争,jemalloc 为每个 CPU 使用单独的内存池“区域”,并且将线程分配给区域以处理 malloc 请求。
tcmalloc
TCMalloc 是 Google 开发的 malloc。通过利用线程本地存储进行小的分配,它减少了多线程程序的锁争用。对于较大的分配,可以将 mmap 或 sbrk 与细粒度且高效的自旋锁一起使用。它还具有垃圾收集功能,用于死线程的本地存储。对于小对象分配,TCMalloc 仅需要8个字节对象的百分之一的空间开销,这非常节省空间。
这是一个测试,用于比较 jemalloc 和 tcmalloc 的性能。该测试涉及500次迭代以执行1000个内存分配,然后释放这1000个内存。如图所示,它们两者的性能十分接近。
SequoiaDB的实现
在 SequoiaDB 中(以 SequoiaDB v3.4 作为例子),它实现了自己专有的内存分配器,该分配器高效且针对 SequoiaDB 数据库引擎中的内存使用量身定制。尽管 jemalloc 和 tcmalloc 都是出色的通用内存分配器,但它们无法解决 SequoiaDB 内部遇到的所有挑战。例如,跟踪内存请求的能力是 SequoiaDB 引擎的一项重要要求,而现有的第三方内存分配器缺少此功能。图2显示了 SequoiaDB 内存模型的体系结构。共有三层-线程,池和 OSS(操作系统服务)。
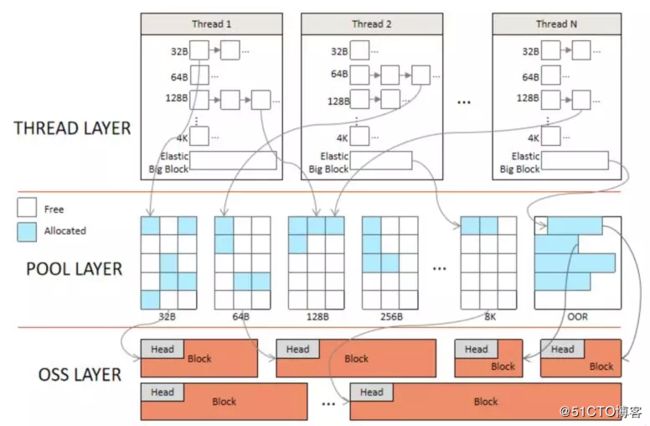
OSS Layer
OSS 层提供了 malloc API,该 API 向底层操作系统请求内存。这也是 PoolLayer 从中获取内存的位置。
Pool Layer
Pool Layer 是全局内存池,其中包含不同大小的段。段是从 OSS 层分配的连续内存块。每个段分为固定大小的块。默认情况下,有32字节,64、128…8092字节的块大小。超过8092字节最大块大小阈值的请求将由 OSS 层处理。
Thread Layer
线程层是线程本地缓存,每个线程都有其自己的专用缓存,因此可以无锁方式完成内存分配。内存块按其块大小分组在一起,使用链接列表实现。从 Pool Layer 请求内存块并将其缓存到配置的阈值。对于超过此阈值的内存,它们将释放回 Pool Layer 并可以由其他线程重用。
此设计有助于限制整体内存占用。此外,每个线程都有一个弹性大块,用于服务超过最大块大小阈值的请求。因此,在大多数情况下,可以在线程层中满足请求,这既高效又快速。
此外,SequoiaDB 内存模型还具有内置的内存调试功能,可以检测内存损坏。它还具有跟踪功能,可以跟踪从哪里请求内存。最重要的是,它是完全可配置的,并允许根据客户的工作量和环境自定义部署。