去年有看了几篇domain adaptation相关的论文,这里想实现一篇最简单好用的模型,Adversarial Discriminative Domain Adaptation,作者提出了针对adversrarial adaptation 的一个通用框架,并且根据这个框架探索了一个新的实例,发现ADDA非常的有效和简单。
domain adaptation主要的意思是把一个domain训练的模型用到另一个domain,和transfer learning基本同义。通常source
domain指的是有标注的域/数据集,target domain是无标注或者小部分标注的域/数据集。这里我们用对抗的方式来训练,训练一个分类器,再让这个分类器没办法区分出是source domain还是target domain,从而用在source domain上构建的分类器去分类target domain。
这里简单的提一下整个模型的结构:
- source domain 有标注数据,target domain无标注数据
- 我们的目标是让source domain和target domain的经过若干变化之后的mapping尽可能的相似,类似于都映射到同一个空间。
- 在source domain上构建的分类器就可以用到target domain上来做分类任务。
Notations 符号含义:

label分类器
这就是一个简单的cross entropy loss,就是一个正常的分类器。输入是对source图片的mapping,输出是分类label。
(Y_t指的是把source上面label换算成target domain上的label,因为最后分类器还是要用到target domain的,如果你的source domain和target domain的label都是一样的就可以当它们是一样的)
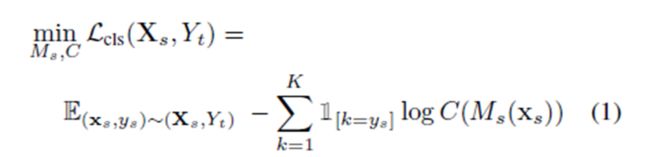
domain分类器
这个分类器主要用来区分当前的数据样本是来自source domain还是target domain的。
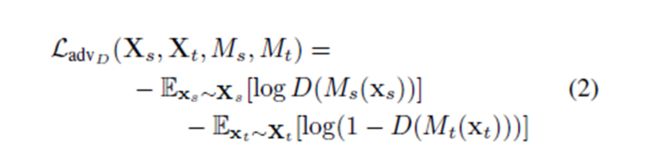
对于这个分类器一般输入的数据一部分来自source domain,一部分来自target domain。
使domain分类器混淆的loss
下图的L_advM就是这里要说的loss。前面说过如果让两个图的mapping达到了domain分类器无法区分的地步,我们就可以完成了这次的训练。所以这个loss其实是和domain classifier的一个对抗的loss,因此我们这里有几种loss可以选择。
-
Minimax objective:
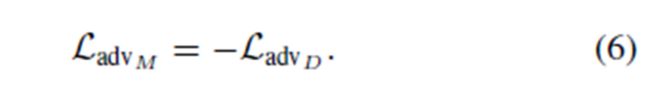 minmax_loss.png
minmax_loss.png -
标准的loss+把label反过来
下面这个也是我们常常在GAN中用的loss函数,只是这里我们把label反过来了一下,比如本来我们的source domain的label是1,这次我们认为target domain的label为1,注意这里的loss只作用于target domain
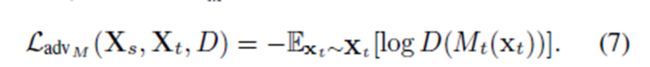 GAN loss function.png
GAN loss function.png -
Domain confusion objective:
在source domain和target domain的分布都在改变的时候,对于前面的GAN loss function,当mapping达到了最优,判别器简单的改变了一下符号的时候,该函数都会导致震荡。所以我们可以用下面这个损失函数,来减轻这个问题。
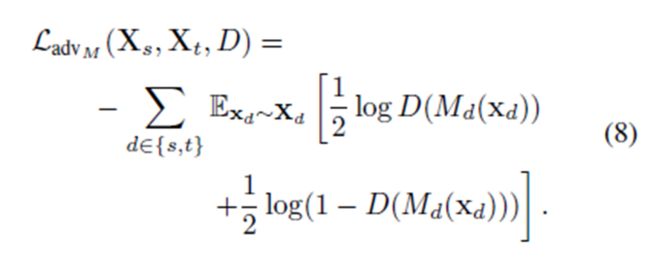 domain confusion objective.png
domain confusion objective.png
关于mapping
就是我们需要把我们的样本映射到某个空间的函数,我们可以让target domain和source domain共享同一个映射函数,或者让它们的某些层共享。

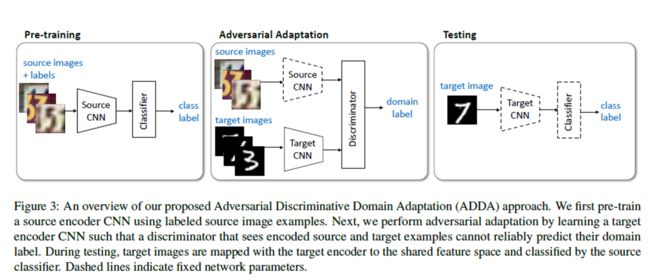
模型的整体结构
首先用有标注的source domain的图片训练一个label分类器;然后训练domain分类器和target domain的mapping(L_advD & L_advM),训练过程中需要固定source网络参数不变。在测试阶段,我们用target domain上的图片丢到target cnn上面得到mapping,放到source cnn上去predict它们的label。
动手试试吧
这里我们用keras,以及验证码数据集(楼主没钱请人标数据,所以只能伪造一批数据了),验证码数据的生成方法和之前的文章一样,从github上找一个哈。。。。
label分类器部分代码
沿用之前文章里提到过的多个输出的验证码模型:
def create_classifier(vocab_size, num_outputs_chars = 3, image_shape=(100,100,3)):
'''
num_outputs_chars: how many output should the model have; we only have one output by default, which means the sequence only has three letters
'''
image_model = Sequential()
image_model.add(Convolution2D(32, (3, 3), padding='valid', input_shape=image_shape))
image_model.add(BatchNormalization())
image_model.add(Activation('relu'))
image_model.add(Convolution2D(32, (3, 3), padding='valid'))
image_model.add(BatchNormalization())
image_model.add(Activation('relu'))
image_model.add(MaxPooling2D(pool_size=(2, 2), padding='valid'))
image_model.add(Dropout(0.25))
image_model.add(Convolution2D(64, (3, 3), padding='valid'))
image_model.add(BatchNormalization())
image_model.add(Activation('relu'))
image_model.add(Convolution2D(64, (3, 3),padding='valid'))
image_model.add(BatchNormalization())
image_model.add(Activation('relu'))
image_model.add(MaxPooling2D(pool_size=(2, 2), padding='valid'))
image_model.add(Dropout(0.25))
image_model.add(Flatten())
image_model.summary()
#for layer in image_model.layers:
# print(layer.get_output_at(0).get_shape().as_list())
# Note: Keras does automatic shape inference.
image_input = Input(shape=image_shape)
encoded_image = image_model(image_input)
outputs = []
for i in range(num_outputs_chars):
out1 = Dense(128, activation="relu")(encoded_image)
output1 = Dense(vocab_size, activation="softmax")(out1)
outputs.append(output1)
model = Model([image_input], outputs)
return (model,encoded_image, image_input)
domain分类器部分代码
def domain_classifier(encoded_image_tensor):
x = Dense(100, activation='relu')(encoded_image_tensor)
x = Dense(100, activation='relu')(x)
x = Dense(2, activation = 'sigmoid')(x)
return x
source_or_target_tensor = Input(shape=(22*22*64,))
discriminator_model = Model(inputs=source_or_target_tensor, output=domain_classifier(source_or_target_tensor), name="discriminator")
print("discriminator model summary")
discriminator_model.summary()
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
discriminator_model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
discriminator_model.trainable=False
这部分代码很简单,只需要对传进来的encode之后的image tensor进行二分类判断是否是源domain还是target domain。注意的是keras中如果下一个模型是建立在上一个模型的基础上,并且要保持上一个模型的参数在下一个模型训练的时候保持不变的话,需要compile并设置trainable参数。
那么我们的与分类器对抗的模型就是:
_,target_image_tensor,image_input = create_classifier(len(all_chars))
#print(keras.backend.shape(target_image_tensor)) # input shape should be inferred from here
target_model = Model(inputs = image_input, outputs=target_image_tensor, name="target_model")
print("target model summary")
target_model.summary()
temp = target_model(image_input)
combined_model = Model(inputs=image_input, outputs=discriminator_model(temp))
sgd = SGD(lr=0.001, decay=1e-6, momentum=0.9, nesterov=True)
combined_model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
由于在训练的过程中我们需要拿到源分类器对源图片的encoding,所以我们这里临时写了一个函数来获取源分类器的某个层的输出:
source_classifier = load_model("sourceModel/weights.01.hdf5")
for layer in source_classifier.layers:
layer.trainable = False
source_classifier.summary()
print(source_classifier.layers[1].get_output_at(1))
target_layer = 1
get_source_encode_layer_output = K.function([source_classifier.layers[0].input, K.learning_phase()],
[source_classifier.layers[1].get_output_at(1)])
联合起来
首先我们预训练一下我们的分类器,然后用k_d和k_g分别来控制分类器的训练步骤数和对抗部分的步骤数。
# begin to train alternatively
def data_generator(X_train, y_train, batch_size):
idx = 0
total = len(X_train)
while 1:
for i in range(total/batch_size):
p = np.random.permutation(len(X_train)) # shuffle each time
X_train = X_train[p]
y_train = y_train[p]
yield X_train[i*batch_size:(i+1)*batch_size], y_train[i*batch_size:(i+1)*batch_size]
source_data_generator = data_generator(source_trainX, source_trainY, 64)
target_data_generator = data_generator(target_trainX, target_trainY, 64)
loss_fake = np.zeros(shape=len(combined_model.metrics_names))
#pretrain
for i in range(4000):
sample_target_x, sample_target_y = next(target_data_generator)
target_y = to_categorical(np.ones(len(sample_target_y)),num_classes=2)
loss_fake= np.add(combined_model.train_on_batch(sample_target_x, target_y), loss_fake)
if i % 200 == 0:
print(loss_fake/200)
loss_fake = 0
print("finish pretrain")
total_training_steps = 15000/64 * 1
k_d = 1
k_g = 2
loss_fake = np.zeros(shape=len(discriminator_model.metrics_names))
loss_dis = np.zeros(shape=len(discriminator_model.metrics_names))
print(discriminator_model.metrics_names)
for t in range(total_training_steps):
for i in range(k_g):
sample_target_x, sample_target_y = next(target_data_generator)
target_y = to_categorical(np.ones(len(sample_target_y)),num_classes=2)
sample_target_x2, sample_target_y = next(target_data_generator)
target_y2 = to_categorical(np.ones(len(sample_target_y)),num_classes=2)
combine_x = np.concatenate((sample_target_x, sample_target_x2),axis = 0)
combine_y = np.concatenate((target_y, target_y2), axis = 0)
loss_fake= np.add(combined_model.train_on_batch(combine_x, combine_y), loss_fake)
for i in range(k_d):
sample_source_x, sample_source_y = next(source_data_generator)
sample_target_x, sample_target_y = next(target_data_generator)
source_y = to_categorical(np.ones(len(sample_source_y)), num_classes=2)
target_y = to_categorical(np.zeros(len(sample_target_y)), num_classes=2)
source_tensor_output = get_source_encode_layer_output([sample_source_x,0])[0]
target_tensor_output = target_model.predict(sample_target_x)
combine_source_target = np.concatenate((source_tensor_output,target_tensor_output), axis = 0)
combine_y = np.concatenate((source_y, target_y), axis = 0)
loss_dis = np.add(discriminator_model.train_on_batch(combine_source_target, combine_y),loss_dis)
if (t % 10) == 0:
print "loss fake", loss_fake/(10*k_g)
print "loss_dis", loss_dis/(10*k_d)
loss_fake = np.zeros(shape=len(discriminator_model.metrics_names))
loss_dis= np.zeros(shape=len(discriminator_model.metrics_names))
target_model.save("targetModel/target_model.hdf5")
discriminator_model.save("discriminatorModel/discriminator_model.hdf5")
最后我们把target domain上的图片经过target model encode之后的输出送到source classifier里面去分类。
结论
具体代码可以戳这里。因为木有看到作者的代码,所以如果读者如果发现我的建模过程有不对的地方,请大家指出。
在训练过程中似乎很容易就让判别器的准确率达到了1,无论与之对抗的分类器怎么努力,都没有办法让判别器的准略率下降。在最后的结果上,对于三个字符的分类效果只有少量的提升(0.040266666666666666, 0.023, 0.021933333333333332)到(0.0672,0.0601333333333,0.0176666666667),根据你停止训练的时机,结果会有略微变化。 这里我们可以发现最后一个字符的准确率并没有提高,而且即使在source domain上面最后一个字符的识别准确率也是最低的。所以,笔者觉得会不会在训练GAN的时候,这个错误被进一步的加大了,因此在单个字符上的训练结果理论上来说应该会更加好,而在序列的字符串上如果某一个字符没有学习充分,这个错误会被进一步的加大。
结语
以后还是用tensorflow吧,可能更加省心一点,唉。。后面还需要多看论文,多写代码呀!另外,也欢迎大家关注“大数据文摘”最近有在更新cs231n作业的解答,其中有一些作业,笔者参与了翻译和解答,欢迎大家指正!感谢~!