前言
最近帮师弟做了一个数据挖掘的大作业,觉得多少还是有点心得,乘兴记录一下( -з)
问题陈述
Over 40,000 instances, mix of continuous and discrete
数据集网址:http://archive.ics.uci.edu/ml/machine-learning-databases/adult/
目标
determine whether a person makes over 50K a year
Class: >50K, <=50K
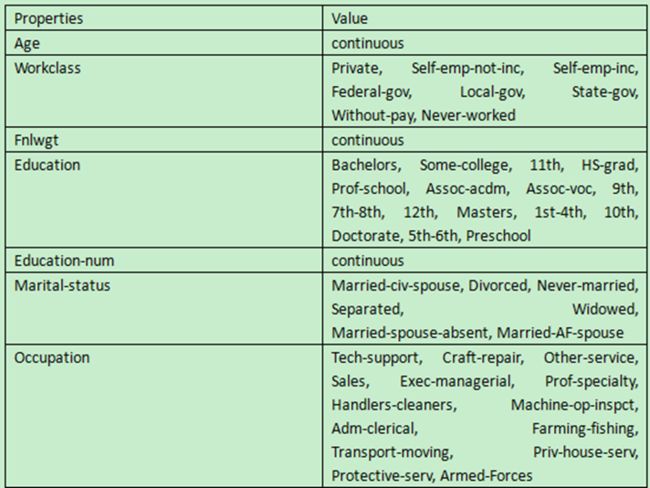
字段说明:

实验过程
1.数据预处理
源数据中,测试集和训练集数据中都有包含缺省值的行('?')
比如:
25, ?, 200681, Some-college, 10, Never-married, ?, Own-child, White, Male, 0, 0, 40, United-States, <=50K
在这里,将这些行去除掉
数据预处理程序:
# -*- coding: UTF-8 -*-
rs = open('./data/new_adult.csv', 'w')
with open('./data/adult.csv') as file:
for line in file:
if '?' in line:
continue
else:
rs.write(line)
rs.close()
2.用决策树 和 随机森林 分别预测收入情况
本过程前期包含数据预处理
主要工作有:
1.读取数据
2.忽略不必要的列
3.将文本项转成数字
4.主成成分分析(PCA)
5.决策树算法、随机森林 进行收入预测
6.决策树可视化
python(使用了sklearn包)代码以及备注如下:
# -*- coding: UTF-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import sys
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
__author__ = 'Su'
"""
算法一:决策树算法(gini系数/entropy信息熵增益)
算法二:随机森林算法(a.10个决策树分支 b.100个决策树分支)
"""
names = ("age, workclass, education, education-num, "
"marital-status, occupation, relationship, race, sex, "
"capital-gain, capital-loss, hours-per-week, "
"native-country, income").split(', ')
data = pd.read_csv('./data/new_adult.csv',names = names,usecols=[0,1,3,4,5,6,7,8,9,10,11,12,13,14])
#读取数据预处理后的训练集数据(省略了第二行数据。原因:第二行为编号,不构成数据筛选条件)
data_test = pd.read_csv('./data/new_test.csv',names = names,usecols=[0,1,3,4,5,6,7,8,9,10,11,12,13,14])
#读取数据预处理后的测试集数据(省略了第二行数据。原因同上)
# print data.head()
# print data.count()
# print data.describe()
for name in ["workclass","education", "marital-status", "occupation", "relationship", "race", "sex", "native-country", "income"]:
col = pd.Categorical.from_array(data[name])
data[name]=col.codes
#文本属性转数组
for name in ["workclass","education", "marital-status", "occupation", "relationship", "race", "sex", "native-country", "income"]:
col1 = pd.Categorical.from_array(data_test[name])
data_test[name]=col1.codes
#文本属性转数组
# print data
X_train = data[['age','workclass','education','education-num','marital-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country']]
#训练集X
y_train = data[['income']]
#训练集y
X_test = data_test[['age','workclass','education','education-num','marital-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country']]
#测试集X
y_test = data_test[['income']]
#测试集y
# print X_test.head()
# print y_test.head()
# print X_train.head()
# print y_train.head()
from sklearn import preprocessing
#sklearn数据标准化函数
"""
公式为:(X-mean)/std 计算时对每个属性/每列分别进行。
将数据按期属性(按列进行)减去其均值,并处以其方差。得到的结果是,对于每个属性/每列来说所有数据都聚集在0附近,方差为1。
"""
# X = np.array(data)
# X_scaled = preprocessing.scale(X)
X_train = preprocessing.scale(np.array(X_train))
y_train = np.array(y_train)
X_test = preprocessing.scale(np.array(X_test))
y_test = np.array(y_test)
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='gini')
clf = clf.fit(X_train,y_train)
#entropy
clf_entropy = tree.DecisionTreeClassifier(criterion='entropy')
clf_entropy = clf_entropy.fit(X_train,y_train)
print clf.score(X_test,y_test)
#准确率 0.805976095618 gini系数
print clf_entropy.score(X_test,y_test)
#准确率 0.808100929615 信息熵增益
X_train_cov = np.cov(X_train.T)
X_train_eig = np.linalg.eig(X_train_cov)
# print X_train_eig
#上面三行是主成成分分析(PCA),各项特征值(下面的特征值矩阵)均未达到可以忽略不计的地步,故保留所有属性
"""
array([ 2.08371954, 0.38413677, 1.40465934, 0.60817972, 0.69172145,
1.12767226, 0.83234406, 0.85438115, 1.09623844, 0.91510361,
0.96803332, 0.99929443, 1.03494693])
"""
from sklearn.ensemble import RandomForestClassifier
clf2 = RandomForestClassifier(n_estimators=10)
clf3 = RandomForestClassifier(n_estimators=100)
clf2 = clf2.fit(X_train,y_train)
clf3 = clf3.fit(X_train,y_train)
print clf2.score(X_test,y_test)
#准确率 0.836387782205 10个决策树
print clf3.score(X_test,y_test)
#准确率 0.840571049137 100个决策树
# with open("./graph/clf.dot",'w') as f:
# f = tree.export_graphviz(clf, out_file=f)
#
# import pydotplus
# dot_data = tree.export_graphviz(clf, out_file=None)
# graph = pydotplus.graph_from_dot_data(dot_data)
# graph.write_pdf("clf.pdf")
#决策树可视化代码
Ps:关于sklearn决策树可视化的一些说明
1.环境搭建
scikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
第一步是安装graphviz。下载地址在:http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH
第二步是安装python插件graphviz: pip install graphviz
第三步是安装python插件pydotplus。这个没有什么好说的: pip install pydotplus
这样环境就搭好了,有时候python会很笨,仍然找不到graphviz,这时,可以在代码里面加入这一行:
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
注意后面的路径是你自己的graphviz的bin目录。
2.决策树可视化的三种方法
首先载入类库:
from sklearn.datasets import load_iris
from sklearn import tree
import sys
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
接着载入sciki-learn的自带数据,有决策树拟合,得到模型:
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
现在可以将模型存入dot文件iris.dot。
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
这时候我们有3种可视化方法,第一种是用graphviz的dot命令生成决策树的可视化文件,敲完这个命令后当前目录就可以看到决策树的可视化文件iris.pdf.打开可以看到决策树的模型图。
1.
#注意,这个命令在命令行执行
dot -Tpdf iris.dot -o iris.pdf
2.
第二种方法是用pydotplus生成iris.pdf。这样就不用再命令行去专门生成pdf文件了。(此方法好用的)
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
3.
第三种办法,直接把图产生在ipython的notebook。代码如下:
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())