title: 经典推荐算法之 Slope one
date: 2017/5/16 15:29:24
tags:
- 推荐系统
- Machine Learning
categories: 推荐系统
Slope One 是一系列应用于协同过滤的算法的统称。由 Daniel Lemire和Anna Maclachlan于2005年发表的论文中提出。 有争议的是,该算法堪称基于项目评价的non-trivial 协同过滤算法最简洁的形式。该系列算法的简洁特性使它们的实现简单而高效,而且其精确度与其它复杂费时的算法相比也不相上下。 该系列算法也被用来改进其它算法。
协同过滤简介及其主要优缺点
协同过滤推荐(Collaborative Filtering recommendation)在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。 与传统文本过滤相比,协同过滤有下列优点:
- 能够过滤难以进行机器自动基于内容分析的信息。如艺术品、音乐。
- 能够基于一些复杂的,难以表达的概念(信息质量、品位)进行过滤。
- 推荐的新颖性。
尽管协同过滤技术在个性化推荐系统中获得了极大的成功,但随着站点结构、内容的复杂度和用户人数的不断增加,协同过滤技术的一些缺点逐渐暴露出来。 主要有以下三点: - 稀疏性(sparsity):在许多推荐系统中,每个用户涉及的信息量相当有限,在一些大的系统如亚马逊网站中,用户最多不过就评估了上百万本书的1%~2%。造成评估矩阵数据相当稀疏,难以找到相似用户集,导致推荐效果大大降低。
- 扩展性(scalability):“最近邻居”算法的计算量随着用户和项的增加而大大增加,对于上百万之巨的数目,通常的算法将遭遇到严重的扩展性问题。
- 精确性(accuracy):通过寻找相近用户来产生推荐集,在数量较大的情况下,推荐的可信度随之降低。
Item-based协同过滤 和 过拟合
当可以对一些项目评分的时候,比如人们可以对一些东西给出1到5星的评价的时候,协同过滤意图基于一个个体过去对某些项目的评分和(庞大的)由其他用户的评价构成的数据库,来预测该用户对未评价项目的评分。 例如: 如果一个人给披头士的评分为5(总分5)的话,我们能否预测他对席琳狄翁新专辑的评分呢?
这种情形下, item-based 协同过滤系统根据其它项目的评分来预测某项目的分值,一般方法为 线性回归 (
另外一种更好的方法是使用更简单一些的式子,比如
实验证明当使用一半的回归量的时候,该式子(称为Slope One)的表现有时优于线性回归方程。该简化方法也不需要那么多存储空间和延迟。
Item-based 协同过滤只是协同过滤的一种形式.其它还有像 user-based 协同过滤一样研究用户间的联系的过滤系统。但是,考虑到其他用户数量庞大,item-based协同过滤更可行一些。
电子商务中的Item-based协同过滤
人们并不总是能给出评分,当用户只提供二进制数据(购买与否)的时候,就无法应用Slope One 和其它基于评分的算法。 二进制 item-based协同过滤应用的例子之一就是Amazon的 item-to-item 专利算法,该算法中用二进制向量表示用户-项目购买关系的矩阵,并计算二进制向量间的cosine相关系数。
有人认为Item-to-Item 算法甚至比Slope One 还简单,例如:

在本例当中,项目1和项目2间的cosine相关系数为:
项目1和项目3间的cosine相关系数为:
而项目2和项目3的cosine相关系数为:
于是,浏览项目1的顾客会被推荐买项目3(两者相关系数最大),而浏览项目2的顾客会被推荐买项目3,浏览了项目3的会首先被推荐买项目1(再然后是项目2,因为2和3的相关系数小于1和3)。该模型只使用了每对项目间的一个参数(cosine相关系数)来产生推荐。因此,如果有n个项目,则需要计算和存储 n(n-1)/2 个cosine相关系数。
Slope One 协同过滤
为了大大减少过适(过拟合)的发生,提升算法简化实现, Slope One 系列易实现的Item-based协同过滤算法被提了出来。本质上,该方法运用更简单形式的回归表达式
例:
- User A 对 Item I 评分为1 对Item J.评分为1.5
- User B 对 Item I 评分为2.
- 你认为 User B 会给 Item J 打几分?
- Slope One 的答案是:2.5 (1.5-1+2=2.5).
举个更实际的例子,考虑下表:

在本例中,项目2和1之间的平均评分差值为 (2+(-1))/2=0.5. 因此,item1的评分平均比item2高0.5。同样的,项目3和1之间的平均评分差值为3。因此,如果我们试图根据Lucy 对项目2的评分来预测她对项目1的评分的时候,我们可以得到 2+0.5 = 2.5。同样,如果我们想要根据她对项目3的评分来预测她对项目1的评分的话,我们得到 5+3=8.
如果一个用户已经评价了一些项目,可以这样做出预测:简单地把各个项目的预测通过加权平均值结合起来。当用户两个项目都评价过的时候,权值就高。在上面的例子中,项目1和项目2都评价了的用户数为2,项目1和项目3 都评价了的用户数为1,因此权重分别为2和1. 我们可以这样预测Lucy对项目1的评价:
于是,对“n”个项目,想要实现 Slope One,只需要计算并存储“n”对评分间的平均差值和评价数目即可。
步骤
计算物品之间的评分差的均值,记为物品间的评分偏差(两物品同时被评分)

根据物品间的评分偏差和用户的历史评分,预测用户对未评分的物品的评分。
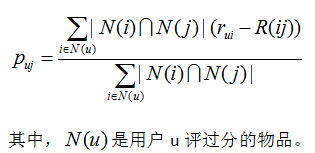
将预测评分排序,取topN对应的物品推荐给用户。
举例
假设有100个人对物品A和物品B打分了,R(AB)表示这100个人对A和B打分的平均偏差;有1000个人对物品B和物品C打分了, R(CB)表示这1000个人对C和B打分的平均偏差;

应用Slope One的推荐系统
● hitflip DVD推荐系统
● How Happy
● inDiscover MP3推荐系统
● RACOFI Composer
● Value Investing News 股票新闻网站
● AllTheBests 购物推荐引擎
Python 实现
def loadData():
items={'A':{1:5,2:3},
'B':{1:3,2:4,3:2},
'C':{1:2,3:5}}
users={1:{'A':5,'B':3,'C':2},
2:{'A':3,'B':4},
3:{'B':2,'C':5}}
return items,users
#***计算物品之间的评分差
#items:从物品角度,考虑评分
#users:从用户角度,考虑评分
def buildAverageDiffs(items,users,averages):
#遍历每条物品-用户评分数据
for itemId in items:
for otherItemId in items:
average=0.0 #物品间的评分偏差均值
userRatingPairCount=0 #两件物品均评过分的用户数
if itemId!=otherItemId: #若无不同的物品项
for userId in users: #遍历用户-物品评分数
userRatings=users[userId] #每条数据为用户对物品的评分
#当前物品项在用户的评分数据中,且用户也对其他物品由评分
if itemId in userRatings and otherItemId in userRatings:
#两件物品均评过分的用户数加1
userRatingPairCount+=1
#评分偏差为每项当前物品评分-其他物品评分求和
average+=(userRatings[otherItemId]-userRatings[itemId])
averages[(itemId,otherItemId)]=average/userRatingPairCount
#***预测评分
#users:用户对物品的评分数据
#items:物品由哪些用户评分的数据
#averages:计算的评分偏差
#targetUserId:被推荐的用户
#targetItemId:被推荐的物品
def suggestedRating(users,items,averages,targetUserId,targetItemId):
runningRatingCount=0 #预测评分的分母
weightedRatingTotal=0.0 #分子
for i in users[targetUserId]:
#物品i和物品targetItemId共同评分的用户数
ratingCount=userWhoRatedBoth(users,i,targetItemId)
#分子
weightedRatingTotal+=(users[targetUserId][i]-averages[(targetItemId,i)])\
*ratingCount
#分母
runningRatingCount+=ratingCount
#返回预测评分
return weightedRatingTotal/runningRatingCount
# 物品itemId1与itemId2共同有多少用户评分
def userWhoRatedBoth(users,itemId1,itemId2):
count=0
#用户-物品评分数据
for userId in users:
#用户对物品itemId1与itemId2都评过分则计数加1
if itemId1 in users[userId] and itemId2 in users[userId]:
count+=1
return count
if __name__=='__main__':
items,users=loadData()
averages={}
#计算物品之间的评分差
buildAverageDiffs(items,users,averages)
#预测评分:用户2对物品C的评分
predictRating=suggestedRating(users,items,averages,2,'C')
print 'Guess the user will rate the score :',predictRating
结果:用户2对物品C的预测分值为
Guess the user will rate the score : 3.33333333333
Slop one 增量更新
主要方法在于根据新的评分项,更新偏差表与共同评分项个数


维基百科
推荐算法之 slope one 算法
黄明波. 基于Slope One算法的增量音乐推荐系统的设计与实现[D].重庆大学,2016