
(一) 初识 Spring
Spring框架是 Java 平台的一个 开源的全栈(Full-stack)应用程序框架和 控制反转容器实现,一般被直接称为 Spring。该框架的一些核心功能理论上 可用于任何 Java 应用,但 Spring 还为基于Java企业版平台构建的 Web 应用提供了大量的拓展支持。虽然 Spring 没有直接实现任何的编程模型,但它已经在 Java 社区中广为流行,基本上完全代替了企业级JavaBeans(EJB)模型—— 维基百科
上面的一段引言,基本阐述了这个Spring框架,而一门框架的流行,自然有其必然之处,怎么理解框架这个词呢?
(1) 简单说说啥是框架
不扯什么太专业的名词,咱们就讲点大白话,大家应该都听过 “框架是一个半成品” ,这句话没毛病,框架就是封装了很多很多的代码,然后你只需要直接调用它提供给你的 API 就能直接使用它的功能,省了咱们很多功夫。最近闲在家,给大家整个比较通俗的例子——鸡蛋灌饼的制作
- 全手工模式:准备300g面粉加少量盐,一分为半,两侧分别加冷、热水,和成絮状,加20ml食用油,揉成偏软的面团,盖盖子醒10-20分钟,找一个碗加两大勺面粉,浇上热油,搅拌均匀,制成油酥,醒好的面,切块,擀成饼状,包入油酥,用包包子的方式收口,松弛5分钟,擀面成薄饼,放入加好适量油的平底锅或者电饼铛,翻第二面的时候,面团会像半个气球一样膨胀起来,筷子挑开一个口,倒入搅拌好加了葱和盐的鸡蛋,然后顺便煎一些喜欢的东西,就可以等面饼熟了(可以自己整点辣椒酱,孜然粉涂上)
- 半成品模式:打开某宝,某东,购买鸡蛋灌饼的现成面皮,直接开火煎,倒入鸡蛋,裹入食材就可以了
使用这个提供好的面饼,就可以省去我们很多功夫,只需要在面饼上进行加工就可以了,这和使用框架是一个道理,框架就是一个半成品,即节省了我们开发的成本,又可以让我们在这个框架的基础上进行自定义的加工
希望大家能看完我的文章,别光记住了鸡蛋灌饼怎么做(捂脸),毕竟我感觉这是一个技术贴
捞一下,贴一个弟弟我全手工做的灌饼(狗头保命)

我好像说的有点多了,赶紧拉回来,框架的最初意愿当然都是为了简化开发,帮助开发者快速的完成项目需求,说的确切一点,就是框架中结合了很多的设计模式,可以让你 “动态” 的开发,将代码实现了通用性,一般自己写的简单的代码,都涉及太多的 “硬编码” 问题了 ,而如果自己去写这些设计模式又太复杂了
所以,做不了巨人,不如我们就学习站在巨人的肩膀上! Let's go!
(2) 什么是耦合?(高/低)
作为一篇新手都能看懂的文章,开始就一堆 IOC AOP等专业名词扔出去,好像是不太礼貌,我得把需要铺垫的知识给大家尽量说一说,如果对这块比较明白的大佬,直接略过就OK了
耦合,就是模块间关联的程度,每个模块之间的联系越多,也就是其耦合性越强,那么独立性也就越差了,所以我们在软件设计中,应该尽量做到低耦合,高内聚
生活中的例子:家里有一条串灯,上面有很多灯泡,如果灯坏了,你需要将整个灯带都换掉,这就是高耦合的表现,因为灯和灯带之间是紧密相连,不可分割的,但是如果灯泡可以随意拆卸,并不影响整个灯带,那么这就叫做低耦合
代码中的例子:来看一个多态的调用,前提是 B 继承 A,引用了很多次
A a = new B();
a.method();如果你想要把B变成C,就需要修改所有new B() 的地方为 new C() 这也就是高耦合
如果如果使用我们今天要说的 spring框架 就可以大大的降低耦合
A a = BeanFactory().getBean(B名称);
a.method();这个时候,我们只需要将B名称改为C,同时将配置文件中的B改为C就可以了
常见的耦合有这些分类:
A: 内容耦合
当一个模块直接修改或操作另一个模块的数据,或者直接转入另一个模块时,就发生了内容耦合。此时,被修改的模块完全依赖于修改它的模块。 这种耦合性是很高的,最好避免

public class A {
public int numA = 1;
}
public class B {
public static A a = new A();
public static void method(){
a.numA += 1;
}
public static void main(String[] args) {
method();
System.out.println(a.numA);
}
}B: 公共耦合
两个以上的模块共同引用一个全局数据项就称为公共耦合。大量的公共耦合结构中,会让你很难确定是哪个模块给全局变量赋了一个特定的值

C: 外部耦合
一组模块都访问同一全局简单变量,而且不通过参数表传递该全局变量的信息,则称之为外部耦合 从定义和图中也可以看出,公共耦合和外部耦合的区别就在于前者是全局数据结构,后者是全局简单变量

D: 控制耦合
控制耦合 。一个模块通过接口向另一个模块传递一个控制信号,接受信号的模块根据信号值而进行适当的动作,这种耦合被称为控制耦合,也就是说,模块之间传递的不是数据,而是一些标志,开关量等等

E: 标记耦合
标记耦合指两个模块之间传递的是数据机构,如高级语言的数组名、记录名、文件名等这些名字即为标记,其实传递的是这个数据结构的地址

F: 数据耦合
模块之间通过参数来传递数据,那么被称为数据耦合。数据耦合是最低的一种耦合形 式,系统中一般都存在这种类型的耦合,因为为了完成一些有意义的功能,往往需要将某些模块的输出数据作为另 一些模块的输入数据

G: 非直接耦合
两个模块之间没有直接关系,它们之间的联系完全是通过主模块的控制和调用来实现的

(3) Spring框架好在哪 ?
- ① 降低耦合度:Spring神奇的 IoC 容器,可以控制对象间的依赖关系,解决了硬编码问题,让你的程序变得 “动态且高效”
- ② AOP 编程支持:Spring 提供了面向切面编程,可以非常方便的实现一些权限拦截或运行监控等的功能
- ③ 方便集成各种优秀框架:Spring 不排斥各种优秀的开源框架,其内部提供了很多优秀框架(Struts、Hibernate、MyBatis、Hessian、Quartz)的直接支持
- ④ 方便程序测试:Spring 支持 junit4 ,可以通过注解方便的测试程序
- ⑤ 声明式事务的支持:Spring 帮助我们从普通的事物管理代码中解放出来,通过配置就可以完成对事物的管理
- ⑥ 降低 JavaEE API 的使用难度:Spring 将 JavaEE 中一些比较难用的 API (JDBC、JavaMail、远程调用等) 进行了封装,使得它们的使用难度大大降低
(4) Spring 框架的结构
讲完了Spring框架的一些优点,现在我们来看一下,Spring框架的结构,来对我们要学习的框架有一个整体的认识,下面是一张官方的结构图
显而易见,Spring框架是一个分层的架构,根据不同的功能,分成了多个模块,而这些模块都是可以单独或者组合使用的,下面我们来简单的介绍一下每一个部分
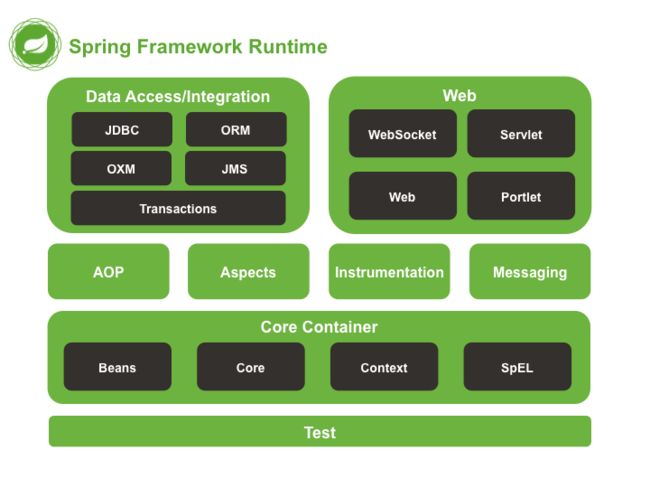
首先将目光放到 CoreContainer 上,它是 Spring 框架最基本也是最核心的部分,其他部分的模块,都是基于这一部分建立的
① 核心容器(CoreContainer)
提供 Spring框架的基本功能,分为图中四个模块,核心容器中重要的组件就是 BeanFactory ,本质就是实现了工厂模式,且它使用了 IoC(控制反转)模式,将程序的配置以及依赖性规范与实际程序的代码分开
- Beans:提供了 BeanFactory,Spring中将管理对象称作 Bean
- Core:提供 Spring 框架的基本组成部分,包括我们首先要学习的 IoC 和 DI
- Context:访问定义和配置任何对象的媒介,以前两者为基础,ApplicationContext 接口是这部分的重点
- spEL (Spring Expression Language):一个比较强大的运行时查询和操作数据的表达式语言
② 数据访问/集成(Data Access/Integration)
- JDBC:提供了一个JDBC抽象层,减少了一些重复无聊的JDBC代码,提升了开发效率
- ORM:提供了对流行对象关系映射API的集成层 (JPA、JDO、Hibernate、 mybatis )
- OXM:提供了一个支持对象/XML映射实现的抽象层( JAXB、Castor、XMLBeans、JiBX 、XStrea )
- JMS:Java消息服务, 包含用于生产和消费消息的功能
- Transactions:事务模块,用于支持实现特殊接口和所有的POJO的类的编程和声明式事物管理
③ Web 模块
- Web:提供了基本的 Web 的集成功能,例如多部分文件上传功能,以及初始化了一个使用了Servlet监听器和面向Web应用程序上下文的 IoC 容器,它还包含一个HTTP客户端和Spring远程支持的相关部分
- Servelt:包含 Spring 模型—视图—控制器 (MVC) ,用来实现Web应用
- WebSocket:Spring4.0以后新增的模块,它提供了WebSocket和SocketJS的实现
- Portlet:就好像是Servlet一般,它提供了Portlet环境下的MVC实现
④ 其余模块
- AOP:提供了面向切面编程的能力,允许定义方法拦截器和切入点,按功能分离代码,降低耦合性,可以实现一些面向对象编程中不太好实现的功能
- Aspects:提供与 AspectJ 的继承,是一个功能强大且成熟的面向切面编程的框架
- Instrumentation:提供了类工具的支持和类加载器的实现,可以在特定的应用服务器中使用
- Messaging: 它提供了对消息传递体系结构和协议的支持
- Test:其支持使用 JUnit 或者 TestNG,可以实现单元测试,集合测试等测试流程
(二) 分析耦合及改进
首先,我们简单的模拟一个对账户进行添加的操作,我们先采用我们以前常常使用的方式进行模拟,然后再给出改进方案,再引出今天要将的 Spring 框架,能帮助更好的理解这个框架
(1) 以前的程序
首先,按照我们常规的方式先模拟,我们先将一套基本流程走下来
A:Service 层
/**
* 账户业务层接口
*/
public interface AccountService {
void addAccount();
}
/**
* 账户业务层实现类
*/
public class AccountServiceImpl implements AccountService {
private AccountDao accountDao = new AccountDaoImpl();
public void addAccount() {
accountDao.addAccount();
}
}B:Dao 层
/**
* 账户持久层接口
*/
public interface AccountDao {
void addAccount();
}
/**
* 账户持久层实现类
*/
public class AccountDaoImpl implements AccountDao {
public void addAccount() {
System.out.println("添加用户成功!");
}
}C:调用
由于,我们创建的Maven工程并不是一个web工程,我们也只是为了简单模拟,所以在这里,创建了一个 Client 类,作为客户端,来测试我们的方法
public class Client {
public static void main(String[] args) {
AccountService as = new AccountServiceImpl();
as.addAccount();
}
}运行的结果,就是在屏幕上输出一个添加用户成功的字样
D:分析:new 的问题
上面的这段代码,应该是比较简单也容易想到的一种实现方式了,但是它的耦合性却是很高的,其中这两句代码,就是造成耦合性高的根由,因为业务层(service)调用持久层(dao),这个时候业务层将很大的依赖于持久层的接口(AccountDao)和实现类(AccountDaoImpl)
private AccountDao accountDao = new AccountDaoImpl();
AccountService as = new AccountServiceImpl();这种通过 new 对象的方式,使得不同类之间的依赖性大大增强,其中一个类的问题,就会直接导致出现全局的问题,如果我们将被调用的方法进行错误的修改,或者说删掉某一个类,执行的结果就是:

在编译期就出现了错误,而我们作为一个开发者,我们应该努力让程序在编译期不依赖,而运行时才可以有一些必要的依赖(依赖是不可能完全消除的)
所以,我们应该想办法进行解耦,要解耦就要使调用者和被调用者之间没有什么直接的联系,那么工厂模式就可以帮助我们很好的解决这个问题
应该大家在 JavaWeb 或者 JavaSE的学习中,或多或少是有接触过工厂这个设计模式的,而工厂模式,我们简单提一下,工厂就是在调用者和被调用者之间起一个连接枢纽的作用,调用者和被调用者都只与工厂进行联系,从而减少了两者之间直接的依赖(如果有一些迷茫的朋友,可以了解一下这种设计模式)
传统模式:

工厂模式:

(2) 工厂模式改进
A:BeanFactory
具体怎么实现呢?在这里可以将 serivice 和 dao 均配置到配置文件中去(xml/properties),通过一个类读取配置文件中的内容,并使用反射技术创建对象,然后存起来,完成这个操作的类就是我们的工厂
注:在这里我们使用了 properties ,主要是为了实现方便,xml还涉及到解析的一些代码,相对麻烦一些,不过我们下面要说的 Spring 就是使用了 xml做配置文件
- bean.properties:先写好配置文件,将 service 和 dao 以 key=value 的格式配置好
accountService=cn.ideal.service.impl.AccountServiceImpl
accountDao=cn.ideal.dao.impl.AccountDaoImpl- BeanFactory
public class BeanFactory {
//定义一个Properties对象
private static Properties properties;
//使用静态代码块为Properties对象赋值
static {
try{
//实例化对象
properties = new Properties();
//获取properties文件的流对象
InputStream in = BeanFactory.class.getClassLoader().getResourceAsStream("bean.properties");
properties.load(in);
}catch (Exception e){
throw new ExceptionInInitializerError("初始化properties失败");
}
}
}简单的解释一下这部分代码(当然还没写完):首先就是要将配置文件中的内容读入,这里通过类加载器的方式操作,读入一个流文件,然后从中读取键值对,由于只需要执一次,所以放在静态代码块中,又因为 properties 对象在后面的方法中还要用,所以写在成员的位置
接着在 BeanFactory 中继续编写一个 getBean 方法其中有两句核心代码的意义就是:
- 通过方法参数中传入的字符串,找到对应的全类名路径,实际上也就是通过刚才获取到的配置内容,通过key 找到 value值

- 下一句就是通过 Class 的加载方法加载这个类,实例化后返回
public static Object getBean(String beanName){
Object bean = null;
try {
//根据key获取value
String beanPath = properties.getProperty(beanName);
bean = Class.forName(beanPath).newInstance();
}catch (Exception e){
e.printStackTrace();
}
return bean;
}B:测试代码:
public class Client {
public static void main(String[] args) {
AccountService as = (AccountService)BeanFactory.getBean("accountService");
as.addAccount();
}
}C:执行效果:
当我们按照同样的操作,删除掉被调用的 dao 的实现类,可以看到,这时候编译期错误已经消失了,而报出来的只是一个运行时异常,这样就解决了前面所思考的问题
我们应该努力让程序在编译期不依赖,而运行时才可以有一些必要的依赖(依赖是不可能完全消除的)

C:小总结:
为什么使用工厂模式替代了 new 的方式?
打个比方,在你的程序中,如果一段时间后,你发现在你 new 的这个对象中存在着bug或者不合理的地方,或者说你甚至想换一个持久层的框架,这种情况下,没办法,只能修改源码了,然后重新编译,部署,但是如果你使用工厂模式,你只需要重新将想修改的类,单独写好,编译后放到文件中去,只需要修改一下配置文件就可以了
我分享下我个人精简下的理解就是:
【new 对象依赖的是具体事物,而不 new 则是依赖抽象事物】
Break it down:
- 依赖具体事物,这个很好理解,你依赖的是一个具体的,实实在在内容,它与你系相关,所以有什么问题,都是连环的,可能为了某个点,我们需要修改 N 个地方,绝望
- 依赖抽象事物,你所调用的并不是一个直接就可以触手可及的东西,是一个抽象的概念,所以不存在上面那种情况下的连环反应
D:再分析:
到这里,似乎还不错,不过我们的程序还能够继续优化! 来分析一下:
首先在测试中,多打印几次,工厂所创建出的对象,我们写个for循环打印下
for(int i = 0; i < 4; i++){
AccountService as = (AccountService)BeanFactory.getBean("accountService");
System.out.println(as);
}看下结果:特别显眼的四次输出,我们的问题也就出来了,我所创建的4个对象是不同的,也就是说,每一次调用,都会实例化一个新的对象,这也叫做多例

这有什么问题吗?
- ①:多次创建对象的代价就是消耗性能,导致效率会低一些
- ②:相比较单例,jvm会回收较多的垃圾
- ③:获取速度比单例慢,因为单例除了第一次,其后都是从缓存中获取
所以,我们要试着将它改成单例的,单例从表现上来看,我们查询到的对象都应该是一个
(3) 多例->单例之再改进
A:分析:
前面我们每一次调用都要将类进行 newInstance(),也就是实例化,想要不再创建新的对象,只需要将我们第一次创建的对象,在创建后就存到一个集合(容器)中,由于我们有查询的需求所以在 Map 和 List 中选择了 Map
B:代码:
简单解读一下:
- 首先在成员位置定义一个 Map,称作beans,至于实例化就不说了
- 通过 keys 方法,取出所有的 配置中所有的key,然后进行遍历出每一个key
- 通过每个 key 从配置中取出对应的 value 在这里就是对应类的全类名
- 将每个取出的 value,使用反射创建出对象 obj
- 将 key 与 obj 存入Map容器
- 在 getBean 方法中只需要从 Map中取就可以了
public class BeanFactory {
//定义一个Properties对象
private static Properties properties;
//定义Map,作为存放对象的容器
private static Map beans;
//使用静态代码块为Properties对象赋值
static {
try {
//实例化对象
properties = new Properties();
//获取properties文件的流对象
InputStream in = BeanFactory.class.getClassLoader().getResourceAsStream("bean.properties");
properties.load(in);
//实例化容器
beans = new HashMap();
//取出所有key
Enumeration keys = properties.keys();
//遍历枚举
while (keys.hasMoreElements()) {
String key = keys.nextElement().toString();
//根据获取到的key获取对应value
String beanPath = properties.getProperty(key);
//反射创对象
Object obj = Class.forName(beanPath).newInstance();
beans.put(key, obj);
}
} catch (Exception e) {
throw new ExceptionInInitializerError("初始化properties失败");
}
}
public static Object getBean(String beanName) {
return beans.get(beanName);
}
} C:执行效果:
测试结果已经变成了单例的

D:单例的劣势:
单例一个很明显的问题,就是在并发情况下,可能会出现线程安全问题
因为由于单例情况下,对象只会被实例化一次,这也就说,所有请求都会共享一个 bean 实例,若一个请求改变了对象的状态,同时对象又处理别的请求,之前的请求造成的对象状态改变,可能会影响在操作时,对别的请求做了错误的处理
举个简单的例子帮助理解:
修改一下 dao 的实现类
public class AccountDaoImpl implements AccountDao {
//定义一个类成员
private int i = 1;
public void addAccount() {
System.out.println("添加用户成功!");
System.out.println(i);
i++;
}
}测试中依旧是哪个循环,不过这次执行一下 addAccount() 方法

通过测试可以看到,单例的情况下,我在dao实现类中 添加了一个类成员 i,然后在方法中对其进行累加并输出操作,每一个值都会被修改,这就出现了我们担心的问题
但是回顾我们从前的编程习惯,似乎我们从未在 service 或 dao 中书写过 类成员,并在方法中对其进行操作,我们一般都是在方法内定义,而这种习惯,也保证了我们现在不会出现这样的问题
将变量定义到方法内
public class AccountDaoImpl implements AccountDao {
public void addAccount() {
int i = 1;
System.out.println("添加用户成功!");
System.out.println(i);
i++;
}
}测试一下

好了这样就没有问题了!
讲这么多,就是为了配合 Spring 的学习,前面我们使用工厂模式对传统的程序进行了改造,程序不再与众多资源等直接联系,而是通过工厂进行提供分配,这种被动接受获取对象的方式就是控制反转,也是它的核心之一,现在就可以开始进入正题了:
(三) 控制反转 -IOC
现在我们就正式开始进入到 Spring 框架的学习中去,而在这部分,并不是说做增删改查,而是通过 Spring 解决依赖的问题,这也就是我们上面众多铺垫内容的原因
由于我们使用的是 maven 创建出一个普通的 java 工程就可以了,不需要创建 java web工程,当然如果不是使用 maven的朋友可以去官网下载jar包 将需要的 bean context core spel log4j 等放到lib中
(1) 第一个入门程序
还是使用前面这个账户的案例,具体的一些接口等等还是用前面的 将第二大点的时候,我已经贴出来了
首先在 maven 中导入需要内容的坐标
A:Maven 导入坐标
- pom.xml
4.0.0
cn.ideal
spring_02_ioc
1.0-SNAPSHOT
jar
org.springframework
spring-context
5.0.2.RELEASE
B:添加配置文件
-
bean.xml
- 引入头部文件
-
bean.xml
- 使用spring管理对象创建 (在beans标签中添加 bean标签)
-
也就是说在配置文件中,对service和dao进行配置
- id:对象的唯一标识
- class:指定要创建的对象的全限定类名
C:测试代码
为什么用这些,等运行后说,先让程序跑起来
public class Client {
public static void main(String[] args) {
//获取核心容器
ApplicationContext ac = new ClassPathXmlApplicationContext("bean.xml");
//根据id后去Bean对象,下面两种方式都可以
AccountService as = (AccountService)ac.getBean("accountService");
AccountDao ad = ac.getBean("accountDao", AccountDao.class);
System.out.println(as);
System.out.println(ad);
}
}D:执行效果
程序运行起来是没有问题的,到这里一个入门例程就跑起来了

(2) ApplicationContext
首先我们来分析一下在调用时的一些内容,测试时,第一个内容,就是获取核心容器,通过了一个 ApplicationContext 进行接收,那么它是什么呢
A:与 BeanFactory 的区别
首先看一下这个图
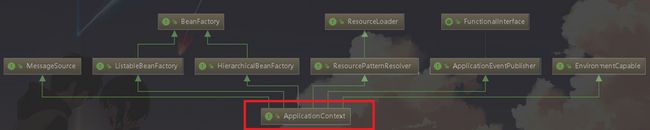
可以看到 BeanFactory 才是 Spring 管理 Bean 的顶级接口,它提供了实例化对象和取出对象的功能,但是由于BeanFactory的简单与一些局限性,有时候并不是很适合于大型企业级的开发,因此,Spring提供了一个新的内容也就是 ApplicationContext:它是一个更加高级的容器,并且功能更加分丰富
在使用时最明显的一个区别就是:两者创建对象的时间点不一样
-
ApplicationContext:单例对象适用采用此接口
- 构建核心容器时,创建对象时采用立即加载的方式。即:只要一读取完配置文件马上就创建配置文件中配置的对象
-
BeanFactory:多例对象适合
- 构建核心容器时,创建对象时采用延迟加载的方式。即:什么时候根据id获取对象,什么时候才真正的创建对象
下面是使用 BeanFactory 进行测试的代码,不过有一些方法已经过时了,给大家参考使用,可以使用打断点的方式进行测试
Resource resource = new ClassPathResource("bean.xml");
BeanFactory factory = new XmlBeanFactory(resource);
AccountService as = (AccountService)factory.getBean("accountService");
System.out.println(as);B:三个实现类
查看 ApplicationContext 的实现类我们要说的就是红框中的几个

style="zoom:80%">- ClassPathXmlApplicationContext:可以加载类路径下的配置文件,当然配置文件必须在类路径下(用的更多)
- FileSystemXmlApplicationContext:可以加载磁盘任意路径下的配置文件(有磁盘访问权限)
- AnnotationConfigApplicationContext:读取注解创建容器
我们由于这篇文章中并没有说注解的问题,所以我们先只看前两个
ApplicationContext ac = new ClassPathXmlApplicationContext("bean.xml");ApplicationContext ac = new FileSystemXmlApplicationContext("D:\\bean.xml");(3) bean标签 以及一些小细节
配置文件中的bean标签,它的作用是配置对象,方便 spring进行创建,介绍一下其中的常用属性
- id:对象的唯一标识
- class:指定要创建的对象的全限定类名
- scope:指定对象的作用范围
- singleton:单例的(默认)
- prototype:多例的
- request:WEB 项目中,Spring 创建 Bean 对象,将对象存入到 request 域中
- session:WEB 项目中,Spring 创建 Bean 的对象,将对象存入到 session 域中
global session:WEB 项目中, Portlet 环境使用,若没有 Portlet 环境那么globalSession 相当于 session
- init-method:指定类中的初始化方法名称
- destroy-method:指定类中销毁方法名称
在Spring 中默认是单例的,这也就是我们在前面的自定义工厂过程中所做的,在Spring中还需要说明,补充一下:
作用范围:
- 单例对象:在一个应用中只会有一个对象的实例,它的作用范围就是整个引用
- 多例对象:每一次访问调用对象,会重新创建对象的实例
生命周期:
- 单例对象:创建容器时出生,容器在则活着,销毁容器时死亡
- 多例对象:使用对象时出生,堆在在则或者,当对象长时间不使用,被垃圾回收回收时死亡
(4) 实例化 Bean 的三种方式
-
①:使用默认无参构造函数
- 根据默认无参构造函数来创建类对象,若没有无参构造函数,则会创建失败
在某些情况下,例如我们想要使用一些别人封装好的方法,很有可能存在于jar包中,并且都是 一些字节码文件,我们是没有修改的权利了,那这时候我们想要使用还可以使用下面两种方法
-
②:Spring 实例工厂
-
使用普通工厂中的方法创建对象,存入Spring
- id:指定实例工厂中 bean 的 id
- class:实例工厂的全限定类名
- factory-method:指定实例工厂中创建对象的方法
-
模拟一个实例工厂,创建业务层实现类,这种情况下,必须先有工厂实例对象,才能调用方法
public class InstanceFactory {
public AccountService createAccountService(){
return new AccountServiceImpl();
}
}-
③:Spring 静态工厂
-
使用工厂中的静态方法创建对象
- id:指定 bean id
- class:静态工厂的全限定类名
- factory-method:指定生产对象的静态方法、
-
public class StaticFactory {
public static IAccountService createAccountService(){
return new AccountServiceImpl();
}
}(四) 依赖注入
控制反转(IoC)是一种思想,而依赖注入(Dependency Injection)则是实现这种思想的方法
其实泛概念上两者是接近的,可以简单的理解为一个概念的不同角度描述
我们前面写程序的时候,通过控制反转,使得 Spring 可以创建对象,这样减低了耦合性,但是每个类或模块之间的依赖是不可能完全消失的,而这种依赖关系,我们可以完全交给 spring 来维护
这种注入方式有三种,先来看第一种
(1) 构造函数注入
这一种的前提就是:类中必须提供一个和参数列表相对应的构造函数
看个例子就清楚了
我们就在 service 中创建几个成员,然后给出其对应的带参构造,以及添加一个方法
/**
* 账户业务层实现类
*/
public class AccountServiceImpl implements AccountService {
private String username;
private Integer age;
private Date birthday;
public AccountServiceImpl(String username, Integer phone, Date birthday) {
this.username = username;
this.age = phone;
this.birthday = birthday;
}
public void addAccount() {
System.out.println("username: " + username
+ ", phone: " + age
+ ", birthday: " + birthday);
}
}添加配置,这里先运行,再解释
测试后,成功的获取到了这些值,并且根据方法内的格式,打印到了屏幕上
username: 汤姆, phone: 21, birthday: Sat Feb 15 16:09:00 CST 2020
看完这个例子,好像有点明白了,上面所做的不就是,使用类的构造函数给成员变量进行赋值,但特别的是,这里是通过配置,使用 Spring 框架进行注入
来说一下所涉及到的标签:
-
constructor-arg(放在 bean 标签内) 再说一说其中的属性值
-
给谁赋值:
- index:指定参数在构造函数参数列表的索引位置
- type:指定参数在构造函数中的数据类型
- name:指定参数在构造函数中的名称(更常用)
-
赋什么值:
- value:这里可以写基本数据类型和 String
- ref:这里可以引入另一个bean,帮助我们给其他类型赋值(例如文中 birthday )
-
(2) set 注入(常用)
顾名思义,我们将前面的构造函数先注释掉,然后补充成员变量的 set 方法
在配置的时候,需要修改
-
property
- name:与成员变量名无关,与set方法后的名称有关,例如 setUsername() 获取到的就是username,并且已经小写了开头
- value:这里可以写基本数据类型和 String
- ref:这里可以引入另一个bean,帮助我们给其他类型赋值(例如文中 birthday )
在这里,还有一种方式就是使用 p名称空间注入数据 (本质还是set)
头部中需要修改引入这一句
xmlns:p="http://www.springframework.org/schema/p"
(3) 注入集合属性
为了演示这些方式,我们在成员中将常见的一些集合都写出来,然后补充其 set 方法
private String[] strs;
private List list;
private Set set;
private Map map;
private Properties props; 在配置中也是很简单的,只需要按照下列格式写标签就可以了,可以自己测试一下
张三
李四
王五
张三
李四
王五
张三
李四
王五
张三
21
(五) 总结
写到这里,这部分Spring框架的入门内容就结束了,先简单提了下 Spring 框架的基本知识,一个是由于为了能让大家详细的理解 Spring 为我们带来的好处,二呢是我写文章的出发点,是想让所有刚接触 Spring 框架的人都可以看得懂,所以首先,先从耦合的一些概念,然后分析到我们传统程序中存在的耦合问题,接着用单例改进这个程序,实际上这都是为了向 Spring 靠近,接下来就是真正的上手,使用Spring框架,了解了其 控制反转(IoC)和依赖注入(DI)技术 ,不是很复杂,主要是想用一种循序渐进的方式,一步一步入门,不知不觉写了都快1w字了
非常希望能给大家提供一些帮助!
或许你掉进了黑暗,我唯一能做的,就是走进黑暗,陪你慢慢走出来
(六) 结尾
如果文章中有什么不足,欢迎大家留言交流,感谢朋友们的支持!
如果能帮到你的话,那就来关注我吧!如果您更喜欢微信文章的阅读方式,可以关注我的公众号
在这里的我们素不相识,却都在为了自己的梦而努力 ❤一个坚持推送原创开发技术文章的公众号:理想二旬不止
