2.1 数据集的概念
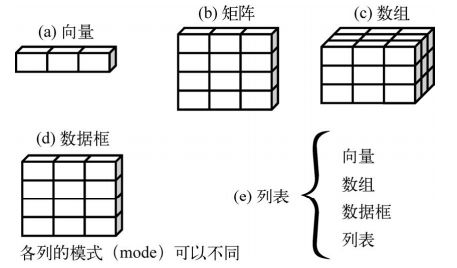
2.2 数据结构
2.2.1 向量
-
通过在方括号中给定元素所处位置的数值,访问向量中的元素
a <- c("k", "j", "h", "a", "c", "m")
a[3]
## [1] "h"
a[c(1, 3, 5)]
## [1] "k" "h" "c"
2.2.2 矩阵
- matrix creates a matrix from the given set of values.
- as.matrix attempts to turn its argument into a matrix.
- is.matrix tests if its argument is a (strict) matrix.
matrix(data = NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = list(char_vector_rownames, char_vector_colnames))
nrow: the desired number of rows.
ncol: the desired number of columns.
byrow: logical. If FALSE (the default) the matrix is filled by columns, otherwise the matrix is filled by rows.
dimnames:A dimnames attribute for the matrix: NULL or a list of length 2 giving the row and column names respectively. An empty list is treated as NULL, and a list of length one as row names. The list can be named, and the list names will be used as names for the dimensions.
- as.matrix(x, rownames.force = NA, ...)
rownames.force:logical indicating if the resulting matrix should have character (rather than NULL) rownames. The default, NA, uses NULL rownames if the data frame has ‘automatic’ row.names or for a zero-row data frame.
- is.matrix(x)
is.matrix returns TRUE if x is a vector and has a "dim" attribute of length 2 and FALSE otherwise. Note that a data.frame is not a matrix by this test.
rnames <- c("R1", "R2")
cnames <- c("C1", "C2")
y <- matrix(1:4, nrow=2, ncol=2, byrow=TRUE,dimnames=list(rnames, cnames))
y
## C1 C2
## R1 1 2
## R2 3 4
is.matrix(y)
## [1] TRUE
as.matrix is a generic function. The method for data frames will return a character matrix if there is only atomic columns and any non-(numeric/logical/complex) column, applying as.vector to factors and format to other non-character columns. Otherwise, the usual coercion hierarchy (logical < integer < double < complex) will be used, e.g., all-logical data frames will be coerced to a logical matrix, mixed logical-integer will give a integer matrix, etc.
da <- data.frame(
lot1 = c(1,2),
lot2 = c("a","b"))
ma<-as.matrix(da)
da
## lot1 lot2
## 1 1 a
## 2 2 b
ma
## lot1 lot2
## [1,] "1" "a"
## [2,] "2" "b"
str(da[1,1])
## num 1
str(ma[1,1])
## Named chr "1"
## - attr(*, "names")= chr "lot1"
如上例所示,数值型被转换为了字符型。
If you just want to convert a vector to a matrix, something like
- dim(x) <- c(nx, ny)
- dimnames(x) <- list(row_names, col_names)
x<-1:6
dim(x)<-c(2,3)
dimnames(x)<-list(c("a","b"),c("c","d","e"))
x
## c d e
## a 1 3 5
## b 2 4 6
-
使用下标和方括号来选择矩阵中的行、列或元素
如x[2,]或者x[1,4],不需要像MATLAB用冒号表示整行或整列。
2.2.3 数组
- myarray <- array(vector, dimensions, dimnames)
2.2.4 数据框
- mydata <- data.frame(col1, col2, col3,...)
patientID <- c(1, 2, 3, 4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
patientdata <- data.frame(patientID, age, diabetes, status)
patientdata
## patientID age diabetes status
## 1 1 25 Type1 Poor
## 2 2 34 Type2 Improved
## 3 3 28 Type1 Excellent
## 4 4 52 Type1 Poor
table(patientdata$diabetes, patientdata$status)
##
## Excellent Improved Poor
## Type1 1 0 2
## Type2 0 1 0
引用方法可以用列号patientdata[1:2],也可以用列名patientdata[c("diabetes", "status")],可以用$符号patientdata$age。
table用来生成列联表。
attach()
例如:
attach(mtcars)
summary(mpg)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.40 15.43 19.20 20.09 22.80 33.90
plot(mpg, disp)
detach(mtcars)
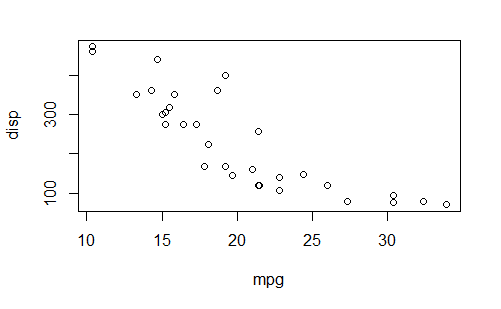
datach()(将数据框从搜索路径中移除。
注意这样可能出现同名对象之间的屏蔽(mask)。
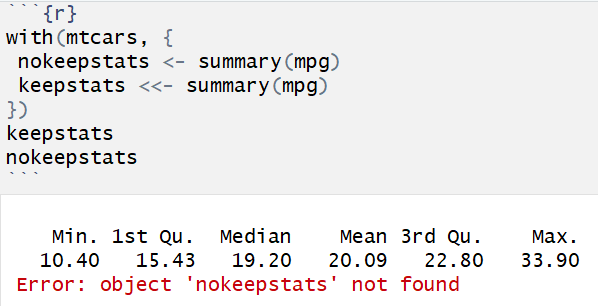
with()
with(mtcars, {
print(summary(mpg))
plot(mpg, disp)
})
花括号{ }之间的语句都针对数据框mtcars执行,无需担心名称冲突。
实例标识符
patientdata <- data.frame(patientID, age, diabetes, status, row.names=patientID)
2.2.5 因子
-
名义型变量是没有顺序之分的类别变量。
-
有序型变量表示一种顺序关系,而非数量关系。
-
连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量。
-
factor() 以一个整数向量的形式存储类别值,由字符串(原始值)组成的内部向量将映射到这些整数上
-
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE
factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA)
levels: an optional vector of the unique values (as character strings) that x might have taken. The default is the unique set of values taken by as.character(x), sorted into increasing order of x. Note that this set can be specified as smaller than sort(unique(x)).
labels: either an optional character vector of labels for the levels (in the same order as levels after removing those in exclude), or a character string of length 1. Duplicated values in labels can be used to map different values of x to the same factor level.
exclude: a vector of values to be excluded when forming the set of levels. This may be factor with the same level set as x or should be a character.
ordered: logical flag to determine if the levels should be regarded as ordered (in the order given), TRUE or FALSE.
nmax: an upper bound on the number of levels.
diabetes <- c("Type1", "Type2", "Type1", "Type1")
x<-factor(diabetes)
x
## [1] Type1 Type2 Type1 Type1
## Levels: Type1 Type2
str(x)
## Factor w/ 2 levels "Type1","Type2": 1 2 1 1
is.factor(x)
## [1] TRUE
as.integer(x)
## [1] 1 2 1 1
y<-factor(diabetes,levels=c("Type2","Type1"))
y
## [1] Type1 Type2 Type1 Type1
## Levels: Type2 Type1
z<-factor(diabetes,labels=c(2,1))
z
## [1] 2 1 2 2
## Levels: 2 1
ex<-factor(diabetes,exclude=c("Type1"))
ex
## [1] Type2
## Levels: Type2