本次笔记内容:
- data frame的行/列selection, index使用方法
- 对data frame中元素进行批量操作(删除行/列,基于其他列添加新列等)
首先需要将表格数据(.csv, .txt, .tab, .xls, 等)导入pandas进行处理,导入时指定的参数不同,则其行列的index定义不同,会对后续的行列selection造成影响。
以路径/home/username/data/下的file.csv为例,
import pandas as pd
df = pd.read_csv('/home/username/data/file.csv',sep='\t')
df.head(5)
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', index_col = 0, header = 0)
使用默认参数得到的data frame为列名作为列的index, 行数作为行的index, 使用col_index = 0则规定行名为第一列,header = 0则规定列名为第一行。以及header = None指定没有列名。output如下所示:
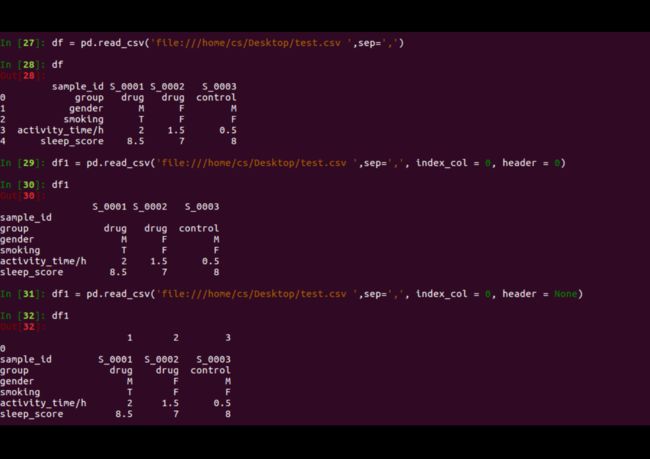
根据数据类型来选择相应的打开方式,一般在数据分析之前,对数据进行预处理,行为各样本(sample)信息,列为各特征信息(feature)。
在使用df['']这样默认方式选择时,需要注意:
df[' '] 是默认选择列
df['':'']是默认选择行的slicing
import pandas as pd
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', col_index = 0, header = 0)
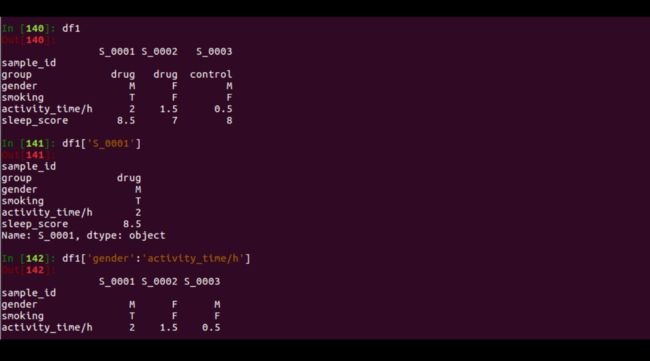
df1['S_0001']
df1['gender':'activity_time/h']
output如下所示。
data frame的行/列selection, index使用方法
- 使用
df.iloc: 使用integer数字选择行列 - 使用
df.loc: 使用index/label行列名称选择 - 使用
df.ix: 可以使用integer也可以使用index/label
1. 使用df.iloc
需要知道想要选择的行列位置,如第几列第几行。
import pandas as pd
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', col_index = 0, header = 0)
## 选择规则: df.iloc[[用于选择行的integer],[用于选择列的integer]]
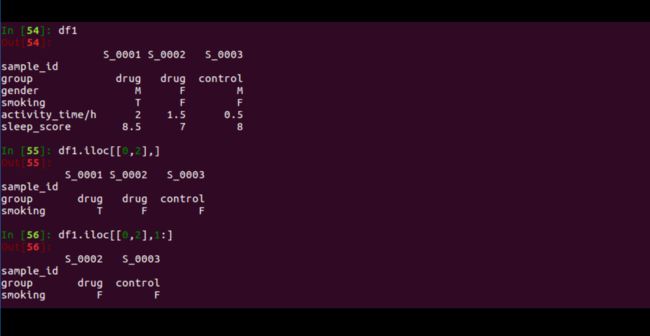
df1 = df1.iloc[[0,2],] # 选择df1中的0、2两行
df1 = df1.iloc[[0,2],1:] # 选择df1中的0、2两行,从第1列开始的后面所有列。注意使用:这样的slicing则不用括在[]中
output如下所示:
2. 使用df.loc
data frame需要有index存在,因为它基于index来进行选择行列。如果没有,需要用.set_index来设置index
df.set_index('col_name', inplace=True)
使用df.loc来选择行列,可以指定需要的行列名称(index)来选择,也可以籍此设置一些选择条件(逻辑语句:Boolean / Logical indexing ),用于初步筛选数据。例如选择gender这个feature为M的所有数据,选择某个feature大于某个数字的所有数据等。
import pandas as pd
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', col_index = 0, header = 0)
## 选择规则: df.loc[[用于选择行的index],[用于选择列的label]]
df1 = df1.T # 处理成sample-行, feature--列的形式
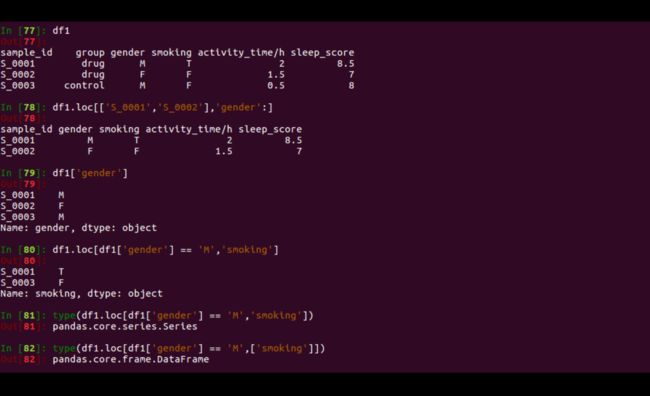
df1 = df1.loc[['S_0001','S_0002'],'gender':] # 选择df1中的S_0001,S_0002两行(sample), 选择gender及其后所有的列(feature)
print df1['gender']
df1.loc[df1['gender'] == 'M', 'smoking'] # 选择feature为gender的samples, 查看feature中smoking的情况: 男性sample中吸烟状况如何?
df1.loc[:,'S_0002':] # 选择S_0002及其后所有的columns,注意冒号的使用
df[['S_0001','S_0002']] # 如果选择多个不连续的column, 可以这样选择
list = ['S_0001','S_0002']
df[list] # 同上是一样的结果
## 需要注意的是,如果在column的选择中没有使用list, 即str: 'smoking', 则得到的数据形式为Series.
## 如果使用list, ['smoking'], 则得到单列的data frame
output如下所示

3. 使用df.ix
只有当data frame的index不是Integer的时候才可以使用,且其行列的指定可以为integer和index混合的。但是目前0.20.1版本之后的pandas都不再使用.ix的用法了,integer和index还是各用各的选择方法比较保险。
import pandas as pd
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', col_index = 0, header = 0)
## 选择规则: df.ix[[用于选择行的integer/index],[用于选择列的integer/index]]
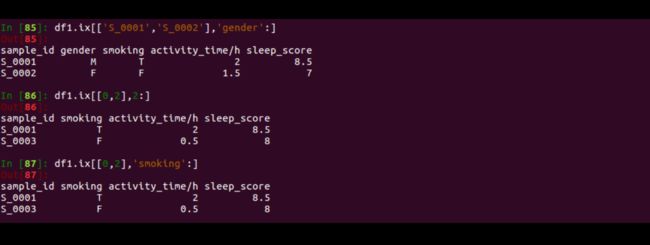
df1.ix[['S_0001','S_0002'],'gender':]
df1.ix[[0,2],2:]
df1.ix[[0,2],'smoking':]
output如下所示
对data frame中元素进行批量操作(加和,基于其他列添加新列等)
获取行名(index),列名(columns),并且查看Index的情况,如有无重复
删除行/列
插入行/列
import pandas as pd
df1 = pd.read_csv('/home/username/data/file.csv', sep='\t', col_index = 0, header = 0)
df1.columns.tolist() # 获取列名,转化为List
df1.index.values # 获取行名,转化为numpy中的arrary
df1.index.has_duplicates # 行名是否有重复。返回True/False
###删除行/列###
df1.drop(['group','gender'], axis=0) # 按照row_name删除行, 不加axis参数则默认删除行
df1.drop(['S_0001','S_0002'],axis=1) # 按照col_name删除列
df1.drop(df1.index[[0,2]], axis=0) # 按照"第几行?"删除行,其row的index必须非0
df1.drop(df1.columns[[0,2]], axis=1) # 按照"第几列?"删除列,其column的index必须非0
###更改行/列名###
df1.rename(index = {'sleep_score': 'sleep_hour', 'smoking': 'smoking_status'}, inplace= True)
# 更改行名: df.reanme(index = {'old_name':'new_name'},inplace= True)
df1.rename(columns = {'S_0001': 's_0001'}, inplace = True)
# 更改列名: 将index换为columns
###插入新的行/列###
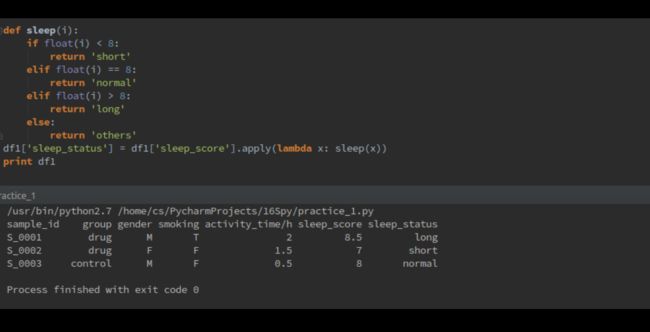
## 比如要生成新的一列,根据sleep_score的数值,生成新的一列sleep_status. 规定低于8小时为short, 8小时为normal, 8小时以上为long.
#这里使用行为sample_id, 列为feature的df1
def sleep(i):
if float(i) < 8:
return 'short'
elif float(i) == 8:
return 'normal'
elif float(i) > 8:
return 'long'
else:
return 'others'
df1['sleep_status'] = df1['sleep_score'].apply(lambda x: sleep(x))
print df1
# df1['sleep_score'].apply(lambda x: sleep(x))基于df1['sleep_score'],apply sleep()函数,生成一个新的列
# (lambda x: sleep(x)) 即输入参数为x, 返回sleep(x)值
output如下所示。(只是写函数不想用ipython而已)
根据某一列数值来slicing dataframe
# 比方说p这个dataframe有一个column叫object, 现在要slicing出object在object_in这个List中的行
object_in = ["a" , "b" , "c", "d"]
p_selected = p.loc[p['object'].isin(object_in),:]
p_selected = p.loc[~p['object'].isin(object_in),:]
# 就是除了object_in之外的