注:本文摘自《流畅的Python》一书,目的是为了个人学习使用
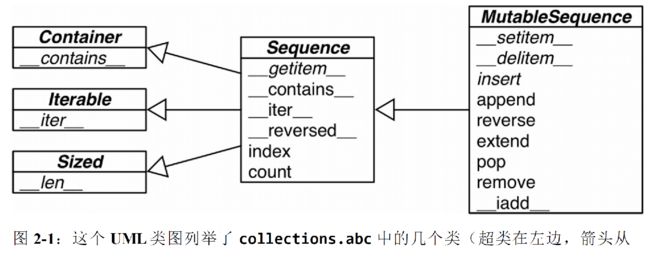
1.容器类型
list,tuple,collections.deque
这些序列能存放不同类型的数据。容器序列存放的死它们所包含的任意类型的对象的引用。
2.扁平序列
str,bytes,bytearray,memoryview和array.array.
这类序列只能容纳一种类型。扁平序列存放的是值而不是引用。换句话说,扁平序列其实是一段连续的内存空间。
由此可见,扁平序列其实更加紧凑,但是它里面只能存放诸如字符,字节和数值这种基础类型。
序列类型还能根据能否被修改来分类
3.可变序列
list, bytearray, array.array,collections.deque,memeoryview
4.不可变序列
tuple,str,bytes
最重要也最基础的序列类型应该就是列表(list)了.
5.列表推导式和生成器推导式
列表推导式和生成器推导式都有自己的局部作用域就像函数一样。后面接触的集合推导和字典推导也是一样。
colors = ['red', 'blue']
sizers = ['L', 'LX', 'LLX']
tshirts = [(color, size) for color in colors for size in sizers]
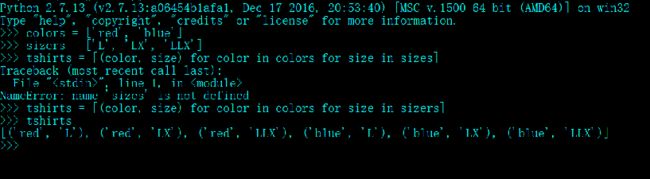
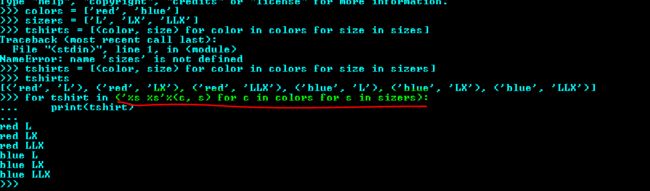
列表推导的作用只有一个:生成列表,如果想生产其他类型的序列,可以使用生成器推导式。生成器表达式背后遵守了迭代器协议,可以逐个的产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。
生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已
6.对序列使用+和*
通常 + 号两侧的序列由相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被修改,Python 会新建一个包含同样
类型数据的序列来作为拼接的结果。
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'
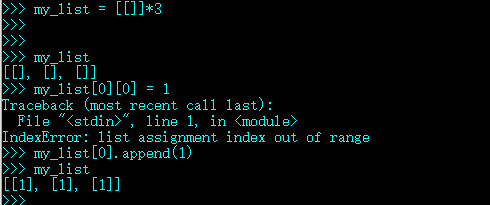
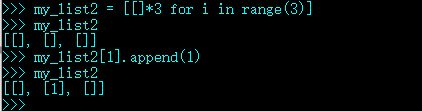
如果在 a * n 这个语句中,序列 a 里的元素是对其他可变对象的引用的话,你就需要格外注意了,因为这个式子的结果可能会出乎意料。比如,你想用my_list = [[]] * 3 来初始化一个由列表组成的列表,但是你得到的列表里包含的 3 个元素其实是 3 个引用,而且这 3 个引用指向的都是同一个列表。这可能不是你想要的效果。
7.序列的增量赋值
+= 背后的特殊方法是 iadd (用于“就地加法”)。但是如果一个类没有实现这个方法的话,Python 会退一步调用 add。
变量名会不会被关联到新的对象,完全取决于这个类型有没有实现 iadd 这个方法。对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素。str 是一个例外,因为对字符串做 += 实在是太普遍了,所以 CPython 对它做了优化。为 str 初始化内存的时候,程序会为它留出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置这类操。
8.list.sort方法和内置函数sorted
list.sort 方法会就地排序列表,也就是说不会把原列表复制一份。返回None,不会创建新的列表。这是一个惯例:
如果一个函数或者方法对对象进行的是就地改动,那它就应该返回 None,好让调用者知道传入的参数发生了变动,而且并未产生新的对象。random.shuffle()就是这样,该方法将序列的所有元素随机排序。

与 list.sort 相反的是内置函数 sorted,它会新建一个列表作为返回值。这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器。而不管 sorted 接受的是怎样的参数,它最后都会返回一个列表。不管是 list.sort 方法还是 sorted 函数,都有两个可选的关键字参数:
- reverse : 如果被设定为 True,被排序的序列里的元素会以降序输出。这个参数的默认值是 False。
- key:一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字。比如说,在对一些字符串排序时,可以用key=str.lower 来实现忽略大小写的排序,或者是用 key=len 进行基于字符串长度的排序。这个参数的默认值是恒等函数(identity function),也就是默认用元素自己的值来排序。
8.用bisect来管理已排序的序列
bisect 模块包含两个主要函数,bisect 和 insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素。
bisect(haystack, needle) 在 haystack(干草垛)里搜索 needle(针)的位置,该位置满足的条件是,把 needle 插入这个位置之后,haystack 还能保持升序。也就是在说这个函数返回的位置前面的值,都小于或等于 needle 的值。其中 haystack 必须是一
个有序的序列。你可以先用 bisect(haystack, needle) 查找位置 index,再用haystack.insert(index, needle) 来插入新值。但你也可用 insort 来一步到位,并且后者的速度更快一些。insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。下面这个例子很优雅:
>>> def grade(score, breakpoints=[60, 70, 80, 90], grades='FDCBA'):
... i = bisect.bisect(breakpoints, score)
... return grades[i]
...
>>> [grade(score) for score in [33, 99, 77, 70, 89, 90, 100]]
['F', 'A', 'C', 'C', 'B', 'A', 'A']
bisect 函数其实是 bisect_right 函数的别名,后者还有个姊妹函数叫bisect_left。它们的区别在于,bisect_left 返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被放置于它相等的元素的前面,而 bisect_right返回的则是跟它相等的元素之后的位置。insort 跟 bisect 一样,有 lo 和 hi 两个可选参数用来控制查找的范围。它也有个变体叫 insort_left,这个变体在背后用的是 bisect_left。
9.数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。
>>> from array import array
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7)))
>>> floats[-1]
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp)
>>> fp.close()
>>> floats2 = array('d')
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7)
>>> fp.close()
>>> floats2[-1]
0.07802343889111107
>>> floats2 == floats
10.双向队列和其他形式的队列
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存放“最近用到的几个元素”,deque 也是一个很好的选择。这是因为在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素.

append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。