卡顿检测是个相当大的话题,检测场景小到本机测试、自动化测试、本地监控,大到线上抽样采集上报。卡顿原因也千差万别,跟CPU、内存、I/O可能都有关。本系列文章旨在通过一些常用的本地卡顿检测工具来定位卡顿原因,并分析其底层实现原理。如果想自研一些APM工具这些原理必须掌握。
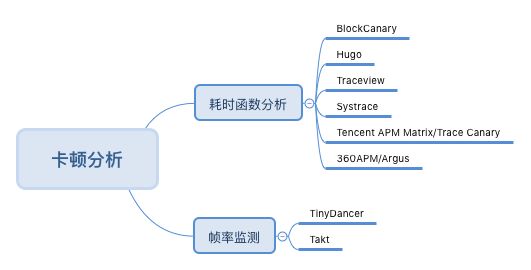
谈到卡顿首先想到的就是BlockCanary,它以其简单易用的特点被广泛用于检测全局的卡顿情况,我们有必要首先了解一下它内部的原理。本篇先来看看BlockCanary项目传送门戳这里。
最新版本
com.github.markzhai:blockcanary-android:1.5.0
BlockCanary原理解析
我们知道Android Framework 很多业务都是通过消息机制完成的,包括UI绘制更新、四大组件生命周期、ANR检查等等。
消息机制给我们一个启发,我们可以监测主线程消息处理的情况来追踪卡顿问题。以UI渲染为例,主线程Choreographer(Android 4.1及以后)每16ms请求一个vsync信号,当信号到来时触发doFrame操作,它内部又依次进行了input、Animation、Traversal过程(具体流程分析参考好文Android Choreographer 源码分析),而这些都是通过消息机制驱动的。
BlockCanary检测的原理也是基于主线程消息的处理流程。既然要检测主线程消息处理情况,那先要清楚主线程Looper对象的创建。
# -> ActivityThread
public static void main(String[] args) {
...
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
if (false) {
Looper.myLooper().setMessageLogging(new
LogPrinter(Log.DEBUG, "ActivityThread"));
}
...
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
ActivityThread的main函数是Android程序的入口,它并不是一个线程类,它运行在主线程中。可以看到通过prepareMainLooper和loop函数使主线程的looper跑起来了。
再看loop方法
# -> Looper.java
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
...
for (;;) {
//从消息队列中取出一条消息,没有消息则休眠
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
msg.recycleUnchecked();
}
}
这里先留一个问题loop函数内部使用了死循环,主线程为什么不会卡死?为什么不会触发ANR?文末有参考文章。
dispatchMessage函数会对消息进行分发,并交由对应的runnable或handler处理,所以监控主线程的卡顿问题实际上就是监控dispatchMessage函数的耗时情况。
可以看到在dispatchMessage前后各有一次logging的打印,并且调用println方法的logging对象还可以通过setMessageLogging方法设置,也就是说Looper内部本身就提供了hook点。
# -> Looper.java
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
我们可以自定义一个Printer并复写其println函数来实现卡顿的监控。事实上,BlockCanary就是这么做的。监控到卡顿点后,dump函数调用堆栈并获取CPU运行情况,便可综合分析卡顿的原因。
BlockCanary源码分析
来看看BlockCanary初始化的方法install和start。
# -> BlockCanary.java
/**
* Install {@link BlockCanary}
*
* @param context Application context
* @param blockCanaryContext BlockCanary context
* @return {@link BlockCanary}
*/
public static BlockCanary install(Context context, BlockCanaryContext blockCanaryContext) {
BlockCanaryContext.init(context, blockCanaryContext);
setEnabled(context, DisplayActivity.class, BlockCanaryContext.get().displayNotification());
return get();
}
# -> BlockCanary.java
public void start() {
if (!mMonitorStarted) {
mMonitorStarted = true;
//设置自定义printer
Looper.getMainLooper().setMessageLogging(mBlockCanaryCore.monitor);
}
}
这里的mBlockCanaryCore.monitor就是LooperMonitor对象,它实现了Printer接口。
我们重点看一下它的println方法。
# -> LooperMonitor.java
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
//dispatchMessage前一次打印进入这里
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
//开始dump信息
startDump();
} else {
//dispatchMessage后一次打印进入这里
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
//判断是否发生卡顿
if (isBlock(endTime)) {
//存储dump下来的信息并通知
notifyBlockEvent(endTime);
}
//停止dump
stopDump();
}
}
主线已经清楚,我们先大致看一下BlockCanary运行的核心流程把握全局。
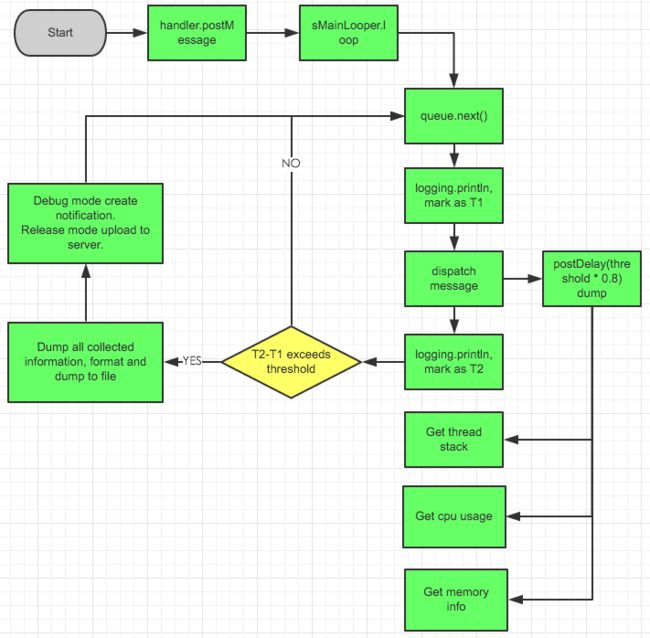
再来看startDump和stopDump
# -> LooperMonitor.java
private void startDump() {
if (null != BlockCanaryInternals.getInstance().stackSampler) {
BlockCanaryInternals.getInstance().stackSampler.start();
}
if (null != BlockCanaryInternals.getInstance().cpuSampler) {
BlockCanaryInternals.getInstance().cpuSampler.start();
}
}
private void stopDump() {
if (null != BlockCanaryInternals.getInstance().stackSampler) {
BlockCanaryInternals.getInstance().stackSampler.stop();
}
if (null != BlockCanaryInternals.getInstance().cpuSampler) {
BlockCanaryInternals.getInstance().cpuSampler.stop();
}
}
可见内部有一个调用堆栈采样器和cpu采样器。
这里有一点需要注意:采样开始的时间点为0.8*卡顿阈值。为什么不在卡顿阈值那个点采样呢?这里其实是一种容错处理。
假设当前函数调用及实际耗时情况如下,卡顿阈值设置为220。
fun foo () {
a()//函数耗时200
b()//函数耗时20
c()//函数耗时10
}
可见导致卡顿的罪魁祸首应该是函数a,但如果在卡顿阈值220才开始dump调用堆栈,有可能捕获到的卡顿堆栈为foo() -> b()或c(),设置0.8倍的预采样点就是为了降低这种情况出现的几率。我们悲观的认为当前已超过80%卡顿阈值的函数就是导致卡顿的主因。
回到采样流程来,首先看stackSampler是如何采样的。
# -> StackSampler.java
protected void doSample() {
StringBuilder stringBuilder = new StringBuilder();
for (StackTraceElement stackTraceElement : mCurrentThread.getStackTrace()) {
stringBuilder
.append(stackTraceElement.toString())
.append(BlockInfo.SEPARATOR);
}
synchronized (sStackMap) {
if (sStackMap.size() == mMaxEntryCount && mMaxEntryCount > 0) {
sStackMap.remove(sStackMap.keySet().iterator().next());
}
sStackMap.put(System.currentTimeMillis(), stringBuilder.toString());
}
}
很简单,就是获取当前线程的堆栈信息,并保存在一个LinkedHashMap对象sStackMap中。
再来看cpuSampler的处理
# -> CpuSampler
@Override
protected void doSample() {
BufferedReader cpuReader = null;
BufferedReader pidReader = null;
try {
cpuReader = new BufferedReader(new InputStreamReader(
new FileInputStream("/proc/stat")), BUFFER_SIZE);
String cpuRate = cpuReader.readLine();
if (cpuRate == null) {
cpuRate = "";
}
if (mPid == 0) {
mPid = android.os.Process.myPid();
}
pidReader = new BufferedReader(new InputStreamReader(
new FileInputStream("/proc/" + mPid + "/stat")), BUFFER_SIZE);
String pidCpuRate = pidReader.readLine();
if (pidCpuRate == null) {
pidCpuRate = "";
}
parse(cpuRate, pidCpuRate);
} catch (Throwable throwable) {
Log.e(TAG, "doSample: ", throwable);
} finally {
//release resource
...
}
}
这里是依据Linux系统cpu的统计方式,Linux系统会将cpu信息和当前进程信息分别存放在/proc/stat和/proc/pid/stat文件中,具体统计原理参看Linux平台Cpu使用率的计算。
通过CPU的使用情况可以大致了解系统的运行情况,CPU如果处于高负载状态,可能是在做CPU密集型计算。如果CPU负载正常,可能处于IO密集状态。
当信息都采集完成后我们回到主线代码。
# -> LooperMonitor
@Override
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
//判断是否发生了卡顿
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
private void notifyBlockEvent(final long endTime) {
final long startTime = mStartTimestamp;
final long startThreadTime = mStartThreadTimestamp;
final long endThreadTime = SystemClock.currentThreadTimeMillis();
//通知写日志线程记录日志
HandlerThreadFactory.getWriteLogThreadHandler().post(new Runnable() {
@Override
public void run() {
mBlockListener.onBlockEvent(startTime, endTime, startThreadTime, endThreadTime);
}
});
}
这里需要注意的是对于threadTime的统计,它通过函数SystemClock.currentThreadTimeMillis()获取,它反映的是线程处于running状态下的时间,这里需要一张Thread运行状态图。
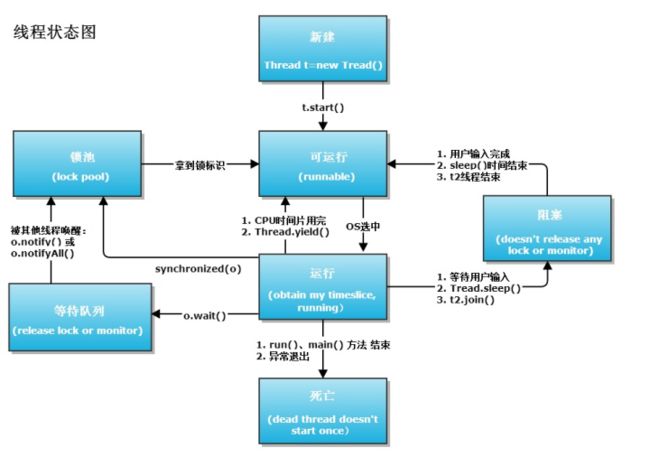
所以比如通过调用thread.sleep方式导致卡顿时并不会统计到threadTime中的。也就是说threadTime反映的是线程真正运行的时间,中间比如锁的获取、cpu的调度及其他非running状态等情况不计算在内。
onBlockEvent的实现在BlockCanary创建之初。
public BlockCanaryInternals() {
stackSampler = new StackSampler(
Looper.getMainLooper().getThread(),
sContext.provideDumpInterval());
cpuSampler = new CpuSampler(sContext.provideDumpInterval());
setMonitor(new LooperMonitor(new LooperMonitor.BlockListener() {
@Override
public void onBlockEvent(long realTimeStart, long realTimeEnd,
long threadTimeStart, long threadTimeEnd) {
// Get recent thread-stack entries and cpu usage
ArrayList threadStackEntries = stackSampler
.getThreadStackEntries(realTimeStart, realTimeEnd);
if (!threadStackEntries.isEmpty()) {
BlockInfo blockInfo = BlockInfo.newInstance()
.setMainThreadTimeCost(realTimeStart, realTimeEnd, threadTimeStart, threadTimeEnd)
.setCpuBusyFlag(cpuSampler.isCpuBusy(realTimeStart, realTimeEnd))
.setRecentCpuRate(cpuSampler.getCpuRateInfo())
.setThreadStackEntries(threadStackEntries)
.flushString();
//写入文件系统
LogWriter.save(blockInfo.toString());
if (mInterceptorChain.size() != 0) {
for (BlockInterceptor interceptor : mInterceptorChain) {
//回调观察者,发送通知
interceptor.onBlock(getContext().provideContext(), blockInfo);
}
}
}
}
}, getContext().provideBlockThreshold(), getContext().stopWhenDebugging()));
LogWriter.cleanObsolete();
}
mInterceptorChain目前注册了两个回调,一个是DisplayService,它收到block消息会发送通知。另一个是BlockCanaryContext,我们可以通过自定义BlockCanaryContext并复写onBlock方法做额外的处理,比如上报网络。
# -> BlockCanaryContext
/**
* Block interceptor, developer may provide their own actions.
*/
@Override
public void onBlock(Context context, BlockInfo blockInfo) {
}
BlockCanary的不足
- 全局性,只能在初始化之后使用,初始化之前的卡顿问题无法分析,比如Application的attachBaseContext函数。这一点只能通过系统统计工具(Traceview/Systrace)或手动插桩。
- 准确性,由于其使用0.8倍的卡顿阈值作为采样点,仍可能出现不能准确识别卡顿函数的情况。
- 卡顿阈值把控,手动设置的卡顿阈值是全局的,但对于某个重要场景我们的要求可能更为严苛,这样就需要在不同的业务场景设置不同的卡顿阈值。
- 细粒度的函数耗时评估,BlockCanary只能告诉我们当前的卡顿函数是哪个,但不能准确的告知到底卡顿了多久,这对于卡顿优化来说是更为精细的指标(Hugo就可以优雅的解决这个问题)。
下一篇:微信自研APM利器Matrix 卡顿分析工具之(二)Trace Canary
参考文章
- BlockCanary源码解析
- BlockCanary源码学习随笔
- 理解Android ANR的触发原理
- Android Choreographer 源码分析
- Android中为什么主线程不会因为Looper.loop()里的死循环卡死
- Linux平台Cpu使用率的计算
- 如何正确地统计函数执行时间