
2017年,阿里官方推出一套Java编程规范:《阿里巴巴Java开发手册(终极版)》,这套Java统一规范标准将有助于提高行业编码规范化水平,帮助行业人员提高开发质量和效率、大大降低代码维护成本。推出之后,在CSDN,InfoQ,知乎等网站引起广泛讨论,口碑收获颇丰。本文旨在抛砖引玉,共同学习这套阿里巴巴近万名开发同学集体智慧的结晶写出来的编程规范。
整体大纲
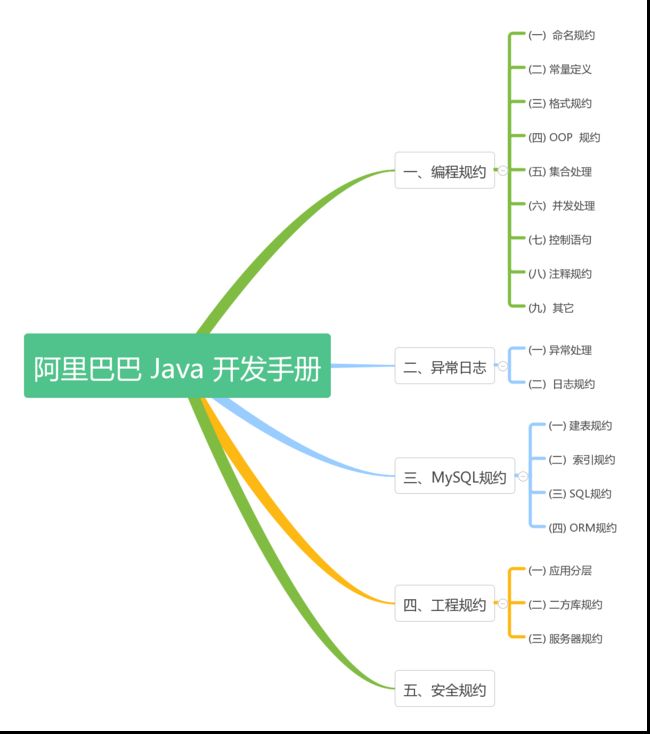
相比起多年前Google的编程规范,阿里巴巴发布的Java开发手册之所以叫做”开发手册”,而不是像Google那样叫做“Style Guide(样式风格)”,是因为它不仅仅局限于样式风格这一方面,而是以开发者为中心视角,划分为编程规约、异常日志规约、MySQL规约、工程规约、安全规约五大块,再根据内容特征,细分成若干目录。根据约束力强弱和故障敏感性,规约依次分为强制、推荐、参考三大类。
该开发手册每一条都值得学习,这里只列出其中颇有感受的几点来共同学习一下。
命名规约
【强制】 POJO 类中布尔类型的变量,都不要加 is ,否则部分框架解析会引起序列化错误。
反例:定义为基本数据类型 boolean isSuccess;的属性,它的方法也是 isSuccess() ,RPC框架在反向解析的时候,“以为”对应的属性名称是 success ,导致属性获取不到,进而抛出异常。
对于isSuccess这个布尔变量,IDE在自动生成getter,setter方法时,生成的方法名称是isSuccess和setSuccess,而不是isIsSuccess和setIsSuccess,
public class DemoPOJO{
boolean active;
boolean isSuccess;
public boolean isActive() {
return active;
}
public void setActive(boolean active) {
this.active = active;
}
public boolean isSuccess() {
return isSuccess;
}
public void setSuccess(boolean success) {
isSuccess = success;
}
}
除了RPC框架反向解析会有问题,类型情况反向解析时也会有问题:
比如SpringMVC在接收前端页面传回一个"isSuccess"布尔变量时,解析成为POJO对象时,找不到setIsSuccess方法,导致POJO的属性不能正确获取,而且比较坑的是,这种情况不容易发现异常,最终解析后的属性值是拿到布尔类型默认值false。
常量定义
【推荐】不要使用一个常量类维护所有常量,应该按常量功能进行归类,分开维护。如:缓存相关的常量放在类: CacheConsts 下 ; 系统配置相关的常量放在类: ConfigConsts 下。
说明:大而全的常量类,非得使用查找功能才能定位到修改的常量,不利于理解和维护。
在写代码的时候,从易用性和可维护性出发,不推荐一个类内容太多,大而全的类,改起来牵一发动全身,一个类只负责一类功能,不要涵盖太多方面。
OOP规约
【强制】所有的覆写方法,必须加@ Override 注解。
反例: getObject() 与 get 0 bject() 的问题。一个是字母的 O ,一个是数字的 0,加@ Override可以准确判断是否覆盖成功。另外,如果在抽象类中对方法签名进行修改,其实现类会马上编译报错。
尽量用最安全的方式写代码,尽量让问题在编译期暴露,而不是运行期暴露
【强制】 Object 的 equals 方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals 。
正例:" test " .equals(object);
反例: object.equals( " test " );
说明:推荐使用 java . util . Objects # equals (JDK 7 引入的工具类 )
类似的还有使用 "=="符号的时候,写成:if(100 == sum)比起写成:if(sum==100),前者更好,因为这样可以避免不小心写成if(sum=100)的问题,前者会编译报错
【强制】所有的相同类型的包装类对象之间值的比较,全部使用 equals 方法比较。
说明:对于 Integer var =?在-128 至 127 之间的赋值, Integer 对象是在IntegerCache.cache 产生,会复用已有对象,这个区间内的 Integer 值可以直接使用==进行判断, 但是这个区间之外的所有数据, 都会在堆上产生, 并不会复用已有对象, 这是一个大坑,推荐使用 equals 方法进行判断。
Integer integerA1 = 100;
Integer integerA2 = 100;
System.out.println(integerA1 == integerA2); //true
Integer integerB1 = 1000;
Integer integerB2 = 1000;
System.out.println(integerB1 == integerB2); //false
System.out.println(integerB1.equals(1000)); //true
【强制】关于基本数据类型与包装数据类型的使用标准如下:
1 ) 所有的 POJO 类属性必须使用包装数据类型。
2 ) RPC 方法的返回值和参数必须使用包装数据类型。
3 ) 所有的局部变量【推荐】使用基本数据类型。
说明: POJO 类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何NPE 问题,或者入库检查,都由使用者来保证。
正例:数据库的查询结果可能是 null ,因为自动拆箱,用基本数据类型接收有 NPE 风险。
反例:比如显示成交总额涨跌情况,即正负 x %, x 为基本数据类型,调用的 RPC 服务,调用不成功时,返回的是默认值,页面显示:0%,这是不合理的,应该显示成中划线-。所以包装数据类型的 null 值,能够表示额外的信息,如:远程调用失败,异常退出。
NPE问题:空指针异常(Null Pointer Exception)
【强制】定义 DO / DTO / VO 等 POJO 类时,不要设定任何属性默认值。
反例: POJO 类的 createTime 默认值为 new Date(); 但是这个属性在数据提取时并没有置入具体值,在更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间。
【强制】 POJO 类必须写 toString 方法。使用 IDE 的中工具: source > generate ,toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString 。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString() 方法打印其属性值,便于排查问题。
【推荐】 类内方法定义顺序依次是:公有方法或保护方法 > 私有方法 > getter / setter方法。
说明:公有方法是类的调用者和维护者最关心的方法,首屏展示最好;保护方法虽然只是子类关心,也可能是“模板设计模式”下的核心方法;而私有方法外部一般不需要特别关心,是一个黑盒实现;因为方法信息价值较低,所有 Service 和 DAO 的 getter / setter 方法放在类体最后。
【推荐】类成员与方法访问控制从严:
1 ) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private 。
2 ) 工具类不允许有 public 或 default 构造方法。
3 ) 类非 static 成员变量并且与子类共享,必须是 protected 。
4 ) 类非 static 成员变量并且仅在本类使用,必须是 private 。
5 ) 类 static 成员变量如果仅在本类使用,必须是 private 。
6 ) 若是 static 成员变量,必须考虑是否为 final 。
7 ) 类成员方法只供类内部调用,必须是 private 。
8 ) 类成员方法只对继承类公开,那么限制为 protected 。
说明:任何类、方法、参数、变量,严控访问范围。过宽泛的访问范围,不利于模块解耦。思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 Service 方法,或者一个 public 的成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的视线内,变量作用域太大,如果无限制的到处跑,那么你会担心的。
1)将构造方法私有化,一般在单例模式下用得比较多,这时使用getInstance()方法来获取一个实例对象。
2)工具类的话,应该暴露出来的方法是静态方法,使用者静态调用,不必实例化对象。
严格控制访问范围,也可以避免属性值被不小心乱改。
集合处理
【强制】关于 hashCode 和 equals 的处理,遵循如下规则:
1) 只要重写 equals ,就必须重写 hashCode 。
2) 因为 Set 存储的是不重复的对象,依据 hashCode 和 equals 进行判断,所以 Set 存储的对象必须重写这两个方法。
3) 如果自定义对象做为 Map 的键,那么必须重写 hashCode 和 equals 。
正例: String 重写了 hashCode 和 equals 方法,所以我们可以非常愉快地使用 String 对象作为 key 来使用。
假如类User重写了“equals”,没有重写“hashCode”方法,现在有userA和userB 2个对象,它们用equals比较时为true,2个对象存入一个Set集合中,Set调用User类默认的hashCode方法,结果在集合中就保存了2个User对象而不是我们想象中的一个 User对象
关于快速重写hashCode,有许多方法:
- Google的Guava项目里有处理hashCode()和equals()的工具类
- com.google.common.base.ObjectsApache Commons也有类似的工具类EqualsBuilder和HashCodeBuilder
- Java 7 也提供了工具类java.util.Objects
- 常用IDE都提供hashCode()和equals()的代码生成。
(来源:知乎)
【强制】 ArrayList 的 subList 结果不可强转成 ArrayList , 否则会抛出 ClassCastException异常: java . util . RandomAccessSubList cannot be cast to java . util . ArrayList ;
说明: subList 返回的是 ArrayList 的内部类 SubList ,并不是 ArrayList ,而是ArrayList 的一个视图,对于 SubList 子列表的所有操作最终会反映到原列表上。
【强制】 在 subList 场景中,高度注意对原集合元素个数的修改,会导致子列表的遍历、增加、删除均产生 ConcurrentModificationException 异常。
【强制】使用工具类 Arrays . asList() 把数组转换成集合时,不能使用其修改集合相关的方法,它的 add / remove / clear 方法会抛出UnsupportedOperationException 异常。
说明: asList 的返回对象是一个 Arrays 内部类,并没有实现集合的修改方法。 Arrays . asList体现的是适配器模式,只是转换接口,后台的数据仍是数组。
String[] str = new String[] { "a", "b" };
List list = Arrays.asList(str);
第一种情况: list.add("c"); 运行时异常。
第二种情况: str[0]= "gujin"; 那么 list.get(0) 也会随之修改
类似问题,可以使用FindBugs插件,自动扫描代码中的Bug,这类问题这个插件是可以检测出来的,类似的在对象中返回属性域的一个引用时,对该引用的修改会影响原对象的域的。
【推荐】高度注意 Map 类集合 K / V 能不能存储 null 值的情况,如下表格:
| 集合类 | Key | Value | Super | 说明 |
|:-----|:-----|:-----|:-----|:-----|
| Hashtable | 不允许为null | 不允许 null | Dictionary | 线程安全 |
| ConcurrentHashMap | 不允许为 null | 不允许为 null | AbstractMap | 分段锁技术 |
| TreeMap | 不允许为null| 允许为 null | AbstractMap| 线程不安全 |
| HashMap | 允许为 null | 允许为 null | AbstractMap | 线程不安全 |
反例: 由于 HashMap 的干扰,很多人认为 ConcurrentHashMap 是可以置入 null 值,注意存储null 值时会抛出 NPE 异常。
【参考】利用 Set 元素唯一的特性,可以快速对一个集合进行去重操作,避免使用 List的contains 方法进行遍历、对比、去重操作。
并发处理
【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:使用线程池的好处是减少在创建和销毁线程上所花的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明: Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool :
允许的请求队列长度为 Integer.MAX_VALUE ,可能会堆积大量的请求,从而导致 OOM 。
2) CachedThreadPool 和 ScheduledThreadPool :
允许的创建线程数量为 Integer.MAX_VALUE ,可能会创建大量的线程,从而导致 OOM 。
OOM - Out of Mana法力耗尽,系统资源耗尽。
《Effective java》第68条:executor和task优先于线程
尽量不直接使用线程,现在关键的抽象不在是Thread,它已可是即充当工作单元,又是执行机制。现在工作单元和执行机制是分开的。
也就是说,把任务(task)的定义和任务的通用执行机制分开,任务有2种,Runnable和Callable,执行机制通用的是executor service。这样做的好处就是下次其他地方需要执行任务就可以愉快复用了,在执行任务策略方面,也因此可以获得极大的灵活性,比如任务的取消,实现等待所有任务完成之后才执行下一步操作等策略。
【强制】 SimpleDateFormat 是线程不安全的类,一般不要定义为 static 变量,如果定义为
static ,必须加锁,或者使用 DateUtils 工具类。
正例:注意线程安全,使用 DateUtils 。亦推荐如下处理:private static final ThreadLocaldf = new ThreadLocal () {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
};
说明:如果是 JDK 8 的应用,可以使用 Instant 代替 Date, LocalDateTime 代替 Calendar,**DateTimeFormatter 代替 Simpledateformatter**,官方给出的解释: simple beautiful strong immutable thread - safe
个人推荐的话,需要做日期与字符串的转换,推荐使用joda的DataTime,主要特点是易于使用,功能完整,可以利用它把JDK Date和Calendar类完全替换掉,而且仍然能够提供很好的集成。
【强制】对多个资源、数据库表、对象同时加锁时,需要保持一致的加锁顺序,否则可能会造成死锁。
说明:线程一需要对表 A 、 B 、 C 依次全部加锁后才可以进行更新操作,那么线程二的加锁顺序也必须是 A 、 B 、 C ,否则可能出现死锁。
死锁问题也可以考虑用对象锁技术来减少。
【强制】多线程并行处理定时任务时, Timer 运行多个 TimeTask 时,只要其中之一没有捕获抛出的异常,其它任务便会自动终止运行,使用 ScheduledExecutorService 则没有这个问题。
除了要注意捕获异常之外,使用Timer还要注意不要执行需要跑运行时间过长的任务,否则在一个定时周期内任务没跑完的会,会导致定时不准,因为一个Timer内部是单线程在跑所有的TimeTask。
【参考】 volatile 解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。如果是 count ++操作,使用如下类实现:
AtomicInteger count = new AtomicInteger(); count.addAndGet( 1 );
如果是 JDK 8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好 ( 减少乐观锁的重试次数 )
多个线程操作同一个对象就会有数据可见性问题,当A线程修改了变量number,修改完成之后,B线程读这个number变量,读到的变量不一定是A线程修改后的变量,什么时候B线程能读到A线程修改后的变量值?有可能永远都读不到,这种现象称为“重排序(Recordering)”
要避免数据可见性的问题,最简单的方法是使用内置锁(synchronized)来保护变量,内置锁可以用于确保某个线程以一种可预测的方法来查看另一个线程的执行结果。也就是说,刚刚的number变量如果使用内置锁保护的话,可以保证多线程可见性。
【参考】 HashMap 在容量不够进行 resize 时由于高并发可能出现死链,导致 CPU 飙升,在开发过程中注意规避此风险。
HashMap容量不足内部会有一个扩容的操作,比较耗CPU,规避此问题可以在初始化HashMap的时候指定容器大小。
控制语句
【强制】在一个 switch 块内,每个 case 要么通过 break / return 等来终止,要么注释说明程序将继续执行到哪一个 case 为止 ; 在一个 switch 块内,都必须包含一个 default 语句并且放在最后,即使它什么代码也没有。
同样如果不小心忘记写break,FindBugs插件可以检测出来。
【推荐】推荐尽量少用 else , if - else 的方式可以改写成:
if(condition){
...
return obj;
}
// 接着写 else 的业务逻辑代码;
说明:如果非得使用 if()...else if()...else... 方式表达逻辑,【强制】请勿超过 3 层,
超过请使用状态设计模式。
正例:逻辑上超过 3 层的 if-else 代码可以使用卫语句,或者状态模式来实现。
很多时候,例如做参数校验的时候,尽量避免不要用一堆 else if,那样导致读代码的人要把整个方法的代码都读完才能理解好代码,建议使用:
if(conditionA){
...
return ;
}
if(conditionB){
...
return ;
}
这样的单独检查就是卫语句(guard clauses).卫语句可以把我们的视线从异常处理中解放出来,集中精力到正常处理的代码中。
【推荐】除常用方法(如 getXxx/isXxx)等外,不要在条件判断中执行其它复杂的语句,将复杂逻辑判断的结果赋值给一个有意义的布尔变量名,以提高可读性。
说明:很多 if 语句内的逻辑相当复杂,阅读者需要分析条件表达式的最终结果,才能明确什么样的条件执行什么样的语句,那么,如果阅读者分析逻辑表达式错误呢?
正例:
//伪代码如下
boolean existed = (file.open(fileName, "w") != null) && (...) || (...);
if (existed) {
...
}
反例:
if ((file.open(fileName, "w") != null) && (...) || (...)) {
...
}
用一个有意义的布尔变量名,替代复杂逻辑判断的结果,这个变量名可以起到一个注释的作用。如果一个方法过长也是不优雅的,可以考虑重构拆分出几个短一点的私有方法来被调用,方法的名称就是一个很好的注释,即时方法只被调用一次这种重构也是有意义的。
【推荐】循环体中的语句要考量性能,以下操作尽量移至循环体外处理,如定义对象、变量、获取数据库连接,进行不必要的 try - catch 操作(这个try - catch是否可以移至循环体外 )。
循环里面不要做耗时过长时间的事情,如果耗时过长,应该扔进去队列里面异步处理。
异常处理
【强制】不要捕获 Java 类库中定义的继承自 RuntimeException 的运行时异常类,如:
IndexOutOfBoundsException / NullPointerException,这类异常由程序员预检查
来规避,保证程序健壮性。
正例: if(obj != null) {...}
反例: try { obj.method() } catch(NullPointerException e){...}
【推荐】定义时区分 unchecked / checked 异常,避免直接使用 RuntimeException 抛出,更不允许抛出 Exception 或者 Throwable ,应使用有业务含义的自定义异常。推荐业界已定义过的自定义异常,如: DAOException / ServiceException 等。
对可恢复的情况使用受检异常,对编程错误使用运行时异常,建议优先使用标准的异常。
【强制】异常不要用来做流程控制,条件控制,因为异常的处理效率比条件分支低。
只针对异常的情况才使用异常
【强制】对大段代码进行 try - catch ,这是不负责任的表现。 catch 时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分异常类型,再做对应的异常处理。
把try块的范围限制到最小
结尾
[图片上传失败...(image-6100e-1522248360126)]
还有Mysql规约值得探究,篇幅所限制,这里就不展开了。
有位架构师曾经在知乎网分享了这样的故事:
2013年stackoverflow第一次公布了部分数据和架构,当时stackoverflow日UV 300W+,PV 2Y+,他们使用了8台物理服务器,而这个架构师的公司使用了近500台物理服务器,换算到性能上,硬件资源对比是125:4,****性能差异是反比,8:250。
公司的架构上没有大问题,各项参数调优,缓存做了,db分布了,nginx mysql redis的各项参数,也做了性能测试和db test经过n轮调整,那为什么性能差异还是这么大?最后他总结出来:
主要的业务逻辑开销更多性能是其次,主要的,是应用层面的程序员造成的:他们处理过许多典型的性能坑:
- db查询没用到索引
- 联表查询太复杂性能奇差
- 循环里写查询一次连接变几十次
- 打开文件句柄 socket连接没有释放
- 300k文本直接存到redis里
- curl请求没有加超时
- 不同的进程争抢同一个文件资源写日志
- get_image_size()获取图片尺寸(会把图片文件整个读取到内存里,每个连接都会!)
- 写的扩展内存溢出
- 直接读取整个巨大文本文件(应该逐行方式读取)
- 在代码逻辑循环里直接发短信发邮件(应该扔到队列异步处理)
- ip黑名单和关键词过滤直接用文本查找比对(**应该做成hash表 **)
更多精彩,欢迎关注公众号 分布式系统架构
