动手学pytorch-机器翻译
1. 机器翻译与数据集
2. Encoder Decoder
3. Sequence to Sequence
4. 实验
1. 机器翻译与数据集
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
数据集采用 http://www.manythings.org/anki/ 的fra-eng数据集
1.1数据集预处理
#数据字典 char to index and index to char
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = collections.Counter(tokens)
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
#数据清洗, tokenize, 建立数据字典
class TextPreprocessor():
def __init__(self, text, num_lines):
self.num_lines = num_lines
text = self.clean_raw_text(text)
self.src_tokens, self.tar_tokens = self.tokenize(text)
self.src_vocab = self.build_vocab(self.src_tokens)
self.tar_vocab = self.build_vocab(self.tar_tokens)
def clean_raw_text(self, text):
text = text.replace('\u202f', ' ').replace('\xa0', ' ')
out = ''
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and i > 0 and text[i-1] != ' ':
out += ' '
out += char
return out
def tokenize(self, text):
sources, targets = [], []
for i, line in enumerate(text.split('\n')):
if i > self.num_lines:
break
parts = line.split('\t')
if len(parts) >= 2:
sources.append(parts[0].split(' '))
targets.append(parts[1].split(' '))
return sources, targets
def build_vocab(self, tokens):
tokens = [token for line in tokens for token in line]
return Vocab(tokens, min_freq=3, use_special_tokens=True)
1.2 创建dataloader
# pad, 构建数据dataset, 创建dataloader
class TextUtil():
def __init__(self, tp, max_len):
self.src_vocab, self.tar_vocab = tp.src_vocab, tp.tar_vocab
src_arr, src_valid_len = self.build_array(tp.src_tokens, tp.src_vocab, max_len = max_len, padding_token = tp.src_vocab.pad, is_source=True)
tar_arr, tar_valid_len = self.build_array(tp.tar_tokens, tp.tar_vocab, max_len = max_len, padding_token = tp.tar_vocab.pad, is_source=False)
self.dataset = torch.utils.data.TensorDataset(src_arr, src_valid_len, tar_arr, tar_valid_len)
def build_array(self,lines, vocab, max_len, padding_token, is_source):
def _pad(line):
if len(line) > max_len:
return line[:max_len]
else:
return line + (max_len - len(line)) * [padding_token]
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
arr = torch.tensor([_pad(line) for line in lines])
valid_len = (arr != vocab.pad).sum(1)
return arr, valid_len
def load_data_nmt(self, batch_size):
train_loader = torch.utils.data.DataLoader(self.dataset, batch_size, shuffle = True)
return self.src_vocab, self.tar_vocab, train_loader2. Encoder Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出

3. Sequence to Sequence
3.1 结构
训练
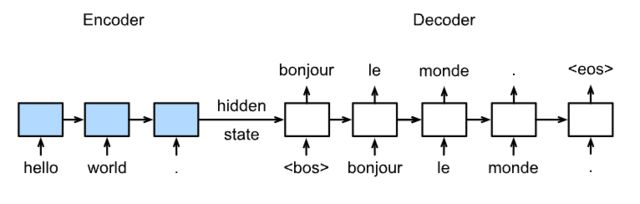
预测

具体结构:
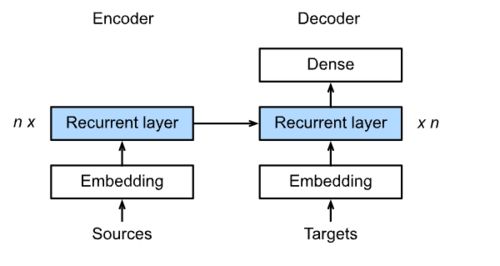
3.2 代码实现
class Encoder(nn.Module):
def __init__(self,**kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, encoded_state, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
encoded_state = self.encoder(enc_X, *args)[1]
decoded_state = self.decoder.init_state(encoded_state, *args)
return self.decoder(dec_X, decoded_state)
class Seq2SeqEncoder(Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, num_hiddens, num_layers, dropout=dropout)
def begin_state(self, batch_size, device):
H = torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)
C = torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)
return (H, C)
def forward(self, X, *args):
X = self.embedding(X)
X = X.transpose(0, 1)
out, state = self.rnn(X)
return out, state
class Seq2SeqDecoder(Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, encoded_state, *args):
return encoded_state
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
out, state = self.rnn(X, state)
out = self.dense(out).transpose(0, 1)
return out, state
def grad_clipping(params, theta, device):
"""Clip the gradient."""
norm = torch.tensor([0], dtype=torch.float32, device=device)
for param in params:
norm += (param.grad ** 2).sum()
norm = norm.sqrt().item()
if norm > theta:
for param in params:
param.grad.data.mul_(theta / norm)
def grad_clipping_nn(model, theta, device):
"""Clip the gradient for a nn model."""
grad_clipping(model.parameters(), theta, device)
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
def get_mask(self, X, valid_len, value=0):
max_len = X.size(1)
mask = torch.arange(max_len)[None, :].to(valid_len.device) < valid_len[:, None]
X[~mask] = value
return X
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = self.get_mask(weights, valid_len)
self.reduction = 'none'
output = super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output * weights).mean(dim=1)
4. 实验
#训练函数
def train(model, data_iter, lr, num_epochs, device): # Saved in d2l
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
tic = time.time()
for epoch in range(1, num_epochs+1):
l_sum, num_tokens_sum = 0.0, 0.0
for batch in data_iter:
optimizer.zero_grad()
X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch]
Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1
Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen)
l = loss(Y_hat, Y_label, Y_vlen).sum()
l.backward()
with torch.no_grad():
grad_clipping_nn(model, 5, device)
num_tokens = Y_vlen.sum().item()
optimizer.step()
l_sum += l.sum().item()
num_tokens_sum += num_tokens
if epoch % 10 == 0:
print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format(
epoch, (l_sum/num_tokens_sum), time.time()-tic))
tic = time.time()
#测试函数
def translate(model, src_sentence, src_vocab, tgt_vocab, max_len, device):
src_tokens = src_vocab[src_sentence.lower().split(' ')]
src_len = len(src_tokens)
if src_len < max_len:
src_tokens += [src_vocab.pad] * (max_len - src_len)
enc_X = torch.tensor(src_tokens, device=device)
enc_valid_length = torch.tensor([src_len], device=device)
# use expand_dim to add the batch_size dimension.
encoded_state = model.encoder(enc_X.unsqueeze(dim=0), enc_valid_length)[1]
dec_state = model.decoder.init_state(encoded_state, enc_valid_length)
dec_X = torch.tensor([tgt_vocab.bos], device=device).unsqueeze(dim=0)
predict_tokens = []
for _ in range(max_len):
Y, dec_state = model.decoder(dec_X, dec_state)
# The token with highest score is used as the next time step input.
dec_X = Y.argmax(dim=2)
py = dec_X.squeeze(dim=0).int().item()
if py == tgt_vocab.eos:
break
predict_tokens.append(py)
return ' '.join(tgt_vocab.to_tokens(predict_tokens))embed_size, num_hiddens, num_layers, dropout = 256, 256, 2, 0.3
batch_size, num_examples, max_len = 256, 5e4, 10
lr, num_epochs = 0.005, 300
tp = TextPreprocessor(raw_text, num_lines=num_examples)
tu = TextUtil(tp, max_len = max_len)
src_vocab, tar_vocab, train_loader = tu.load_data_nmt(batch_size = batch_size)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tar_vocab), embed_size, num_hiddens, num_layers, dropout)
model = EncoderDecoder(encoder, decoder)
train_ch7(model, train_loader, lr, num_epochs, device=device)for sentence in ['Go .', 'Wow !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + translate_ch7(
model, sentence, src_vocab, tgt_vocab, max_len, ctx))Go . => va !
Wow ! => !
I'm OK . => ça va .
I won ! => j'ai gagné !