作者:hwj3747
转载请注明
简介
在看动漫追番的时候,发现每一季度的新番都是被优酷,爱奇艺,哔哩哔哩,PPTV等各大视频厂商买了版权,导致我在手机上要装各种软件,并且很多番更是直接被广电禁掉了,很烦。于是乎,我找到了一个山寨的网站:风车动漫,里面资源倒是挺多,(当然,广告弹窗什么的也很多)可惜没有APP端。刚好最近学习了爬虫技术,于是我就想,能不能用爬虫技术帮他搞一个APP端呢?说干就干,刚好好久没写代码了,就当是练练手,于是我制作了一个简易版的APP,不会设计界面,界面有点丑,并且还是有很多问题没解决就是了。
目前完成了新番展示页面,即展示周一到周日每日新番表,番剧详情页面,播放页面效果如下:
基本功能算是实现了,但是还有很多问题,能力有限,还没解决。
前期准备
- 技术准备:需要掌握Android开发技术,以及一点点的前端HTML,CSS,JS技术。
- 基本框架就是我以前写过的[Android MVP+Retrofit+dagger2+RxAndroid框架整合])(其实这么小的项目,根本不需要这么重的框架,但是拿过来练手,熟悉下框架还是不错的)
- jsoup:好像Java做爬虫都是用的这个包。
- contextmenu:就是右边周一到周日的选择菜单,看他动效还不错就拿过来用了,详细使用方法点进去GitHub就看得到了。
- glide :这个没什么好说的,就是加载图片的库了。
- 谷歌浏览器 :因为要做爬虫,所以分析前端的HTML代码的工具也要有,这里推荐Chrome浏览器,好用!
- 注意,本文主要讲述爬虫方面如何爬数据,至于Android端的实现都只是一些基本的页面,所以就不一一赘述了。
番剧列表页面
首先进入风车动漫这个网站,找到这个地方,我们只需要获取周一到周日的番剧列表就行了。

然后用谷歌浏览器F12查看源代码,得到:

我们发现它的结构是这样的:最上层一个div标签 class为tists,包含7个ul标签,每个u标签l包含若干个li标签,这个li标签里面就是每个番剧里的信息了,只包含番剧名,番剧链接以及当前第几话的信息。
知道这些后,我们就可以用爬虫来获取这些数据了。
首先我们建立一个用来存放番剧简要信息的实体类:
public class BangumiEntity {
String title;//番剧标题
String number;//当前是第几话
String url;//番剧的链接
}
然后初始化,用Jsoup获取网站连接:
String url = "http://www.fengchedm.com/";
Connection conn = Jsoup.connect(url);
// 修改http包中的header,伪装成浏览器进行抓取
conn.header("User-Agent", "Mozilla/5.0 (X11; Linux x86_64; rv:32.0) Gecko/ 20100101 Firefox/32.0");
Document doc = null;
try {
doc = conn.get();
} catch (IOException e) {
e.printStackTrace();
}
先获取最上层class为tists的这个div标签
Elements noteList = doc.select("div.tists");
然后获取其下的ul标签列表
Elements ul = noteList.select("ul");
然后用同样的方法遍历ul标签下的li标签,获取其中的数据,因为这里只有两个a标签,第一个是第几话,第二个是番剧名,所以我就用first和last获取了,没在用数组了。.而attr方法可以用来获取标签内的某个属性,比如这里的a标签里的href属性,并且加上abs:可以取得到完整的路径,因为很多网站写路径的时候都是用的相对路径,最后,用二维数组保存这个信息:
ArrayList> arrayList=new ArrayList>();
for (Element ulElement : ul) {
Elements li=ulElement.select("li");
ArrayList bangumiEntities=new ArrayList();
for (Element liElement : li) {
BangumiEntity bangumiEntity=new BangumiEntity();
bangumiEntity.setNumber(liElement.select("a").first().text());
bangumiEntity.setTitle(liElement.select("a").last().text());
bangumiEntity.setUrl(liElement.select("a").last().attr("abs:href"));
bangumiEntities.add(bangumiEntity);
}
arrayList.add(bangumiEntities);
}
接下来要做的就是把这个arrayList的数据展示到页面上了,页面我是用的RecycleView+CarView实现,具体见源码。
番剧详情页面(1)
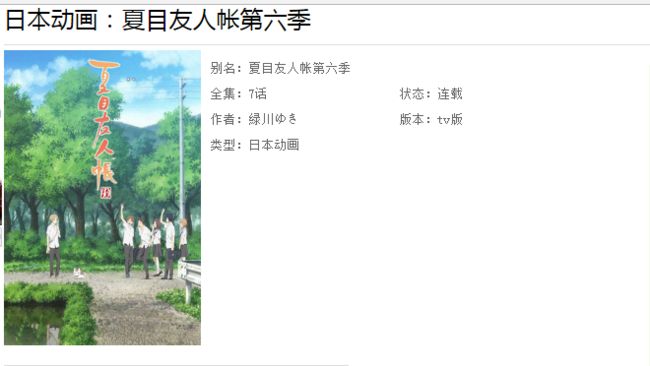
在前面的页面上,我们点击某一番剧进入页面,如下:
用F12查看源代码,得到这一部分的HTML代码:
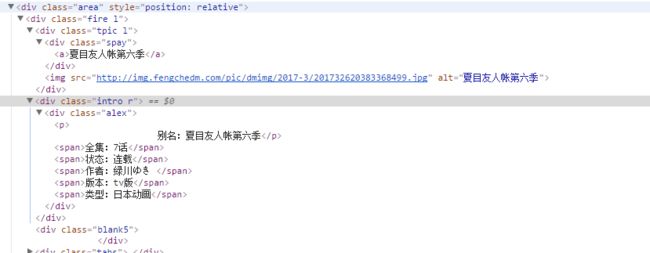
接下来分析一下,这段HTML的结构是这样的:
- 番剧名:class为spay的div标签,里面的a标签
- 封面链接:class为tpic l的div标签下的img标签
- 作者,状态等详细信息: class为alex的div标签下的span标签数组
同样先新建一个实体对象用来保存这些信息:
public class BangumiInfoEntity {
String name;//名字
String cover;//封面
String all;//全集
String autor;//作者
String type;//类型
String state;//状态
String version;//版本
}
用前面得到的URL访问这个页面:
getItemInfo(String url){
Connection conn = Jsoup.connect(url);
// 修改http包中的header,伪装成浏览器进行抓取
conn.header("User-Agent", "Mozilla/5.0 (X11; Linux x86_64; rv:32.0) Gecko/ 20100101 Firefox/32.0");
Document doc = null;
try {
doc = conn.get();
} catch (IOException e) {
e.printStackTrace();
}
}
然后就可以用爬虫来解析的这段代码了,还是和上面一样,先是获取spay div下的a标签得到番剧名,然后获取tpic l div(注意:这里两个class用.链接)下的img标签用attr方法获取src属性得到封面图片链接最后获取alex div 下的span数组,遍历得到番剧的详情信息。
BangumiInfoEntity bangumiInfoEntity =new BangumiInfoEntity();
bangumiInfoEntity.setName(doc.select("div.spay").select("a").text());
bangumiInfoEntity.setCover(doc.select("div.tpic.l").select("img").attr("src"));
Elements noteList = doc.select("div.alex").select("span");
bangumiInfoEntity.setAll(noteList.get(0).text());
bangumiInfoEntity.setState(noteList.get(1).text());
bangumiInfoEntity.setAutor(noteList.get(2).text());
bangumiInfoEntity.setVersion(noteList.get(3).text());
bangumiInfoEntity.setType(noteList.get(4).text());
番剧详情页面(2)
我们已经获取到了番剧的详细信息,接下来,我们要获取的就是番剧下的资源信息了,页面如下:

用F12查看源代码,得到这一部分的HTML代码:

接下来分析一下,这段HTML的结构是这样的:所有的资源都是在tabs的div下,在其下面,资源来源在menu0的ul标签下,资源的集数在main0的div标签下,一一对应。并且,main0的div下用若干的li标签,每个li标签用a标签包裹每集的集数以及链接。
新建一个实体类,用来保存集数以及链接的信息:
public class BangumiEpisodeEntity {
String num;//第几话
String url;//地址
}
同样的,用番剧列表页面得到的链接访问这个页面:
getItemList(String url){
Connection conn = Jsoup.connect(url);
// 修改http包中的header,伪装成浏览器进行抓取
conn.header("User-Agent", "Mozilla/5.0 (X11; Linux x86_64; rv:32.0) Gecko/ 20100101 Firefox/32.0");
Document doc = null;
try {
doc = conn.get();
} catch (IOException e) {
e.printStackTrace();
}
}
最后,用一个title的一维数组保存资源来源信息,用一个child的二维数组保存资源每一集的信息。先获取class为menu0下的ul标签数组,遍历将里面class为on的li标签存入title数组。然后获取class为main0下的div数组,再遍历下面的li标签,分别获取li标签下的a标签的text以及href属性,得到剧集名,以及剧集链接。
ArrayList title=new ArrayList();
ArrayList> child=new ArrayList>();
Elements noteList = doc.select("div.tabs");
Elements ul = noteList.select("ul.menu0");
Elements div = noteList.select("div.main0");
for (Element ulElement : ul) {
title.add(ulElement.select("li.on").text());
}
for(Element divElement:div){
Elements li=divElement.select("li");
ArrayList bangumiEpisodeEntities=new ArrayList();
for (Element liElement : li) {
BangumiEpisodeEntity bangumiEpisodeEntity=new BangumiEpisodeEntity();
bangumiEpisodeEntity.setNum(liElement.select("a").text());
bangumiEpisodeEntity.setUrl(liElement.select("a").attr("abs:href"));
bangumiEpisodeEntities.add(bangumiEpisodeEntity);
}
child.add(bangumiEpisodeEntities);
}
番剧详情页面的UI部分,上半部分用的是glide加载图片,下半部分用的是ExpandableListView展示各个资源来源下的番剧信息。
播放页面
这个部分就比较头大了,我原本的想法是获取视频的真实地址,然后直接用播放器播放,岂不是美滋滋。然而,我仔细研究了一下他的html页面,发现他视频播放时这样做的:
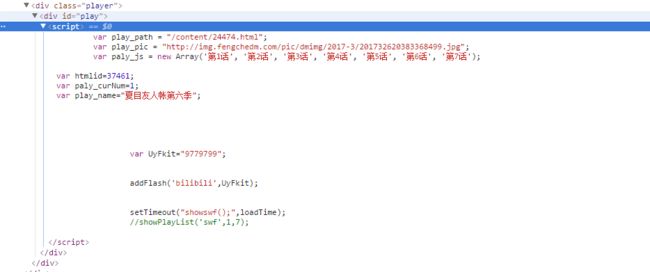
就是说他的视频播放使用js代码动态注入的,然后用flash播放的,对于我这个对JS只了解皮毛的来说研究不透。对于如何获取视频的真实地址,希望有大佬能讲一下这方面的思路。
最后我就只能用webview直接加载视频播放页面了,但是新的问题就又来了,用webview倒是能加载,但是因为是山寨网站,网站下面一堆广告,看起来很不爽。我就又研究了一下,他的广告加载方式。。结果广告也是用js动态注入的,看不明白。于是我就用了一个很挫的方法解决了这个广告问题,因为广告都是在页面的上方,所以我只保留播放器上面的div不就得了。具体实现是这样的
WebView wv;
wv.setWebViewClient(new WebViewClient() {
@Override
public void onPageFinished(WebView view, String url) {
view.loadUrl("javascript:function setTop(){var x=document.getElementsByTagName(\"div\");" +
"for (var i=8;i在webview加载过程和加载完成后注入js代码,查找所有div标签,然后把播放器一下所有的div标签都屏蔽掉。
最后附上项目github地址:github