前景提要
- 请求网站: urllib/requests/selenium/scrapy
- 解析源码: lxml/bs4/re/scrapy(xpath)
- 存储: MySQL, mongo
- 反爬: woff、user-agent、ip、ajax、cookie、referer
- 反反爬: 大众点评(字体woff)、猫眼、fake_useragent、ip代理池、分析js、验证码
框架scrapy
- 框架scrapy == >>twisted(异步)
1. 安装scrapy
- pip install scrapy --- 报错 安装twisted
- easy_install pywin32-221.win-amd64-py3.6.exe
- twisted安装:pip install Twisted-19.2.1-cp37-cp37m-win_amd64.whl
- 在安装scrapy - pip install scrapy
2. 初建项目
- scrapy startproject TestSpider - 创建项目
- cd TestSpider
- scrapy genspider qidian www.qidian.com - 创建爬虫文件文件名是qidian.py, 爬取的网站是www.qidian.com
- scrapy crawl qidian - 启动爬虫
3. 爬取豆瓣电影
-
scrapy执行过程
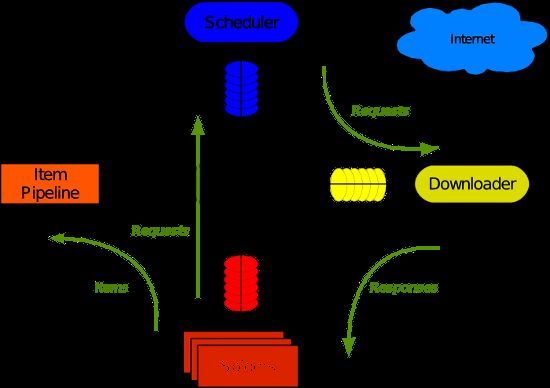 spider_scrapy_zhujian.png
spider_scrapy_zhujian.png
"""__author__= 雍新有"""
from scrapy import Selector, Spider, Request
class DouBanSpider(Spider):
# 爬虫名
name = 'douban'
# 爬取地址, 爬虫默认从start_urls列表中取地址进行爬取,
# 写一个parse不指定该解析哪个response,所有分开写
# start_urls = ['正在上映url', '即将上映url', '即将上映全部电影url']
# 正在上映url
nowplaying_url = 'https://movie.douban.com/cinema/nowplaying/chengdu/'
# 即将上映url
later_url = 'https://movie.douban.com/cinema/later/chengdu/'
# 即将上映全部电影url
coming_url = 'https://movie.douban.com/coming'
def start_requests(self):
# 自定义发送的请求,请求地址的响应通过callback参数来指定
yield Request(url=self.nowplaying_url,
callback=self.parse_nowplaying)
yield Request(url=self.coming_url,
callback=self.parse_coming)
yield Request(url=self.later_url,
callback=self.parse_later)
def parse_nowplaying(self, response):
sel = Selector(response)
# 拿到电影列表
nowplaying_movies = sel.xpath('//*[@id="nowplaying"]/div[2]/ul/li')
for movie in nowplaying_movies:
# 第一个a标签,电影链接
href = movie.xpath('./ul/li/a/@href').extract_first()
yield Request(url=href, callback=self.parse_detail)
def parse_coming(self, response):
sel = Selector(response)
# 即将上映的电影列表
coming_movies = sel.xpath('//*[@id="content"]/div/div[1]/table/tbody/tr')
for movie in coming_movies:
href = movie.xpath('./td[2]/a/@href').extract_first()
yield Request(url=href, callback=self.parse_detail)
def parse_later(self, response):
sel = Selector(response)
later_movies = sel.xpath('//*[@id="showing-soon"]/div')
for movie in later_movies:
href = movie.xpath('./a/@href').extract_first('')
yield Request(url=href, callback=self.parse_detail)
def parse_detail(self, response):
# 回调用于解析电影详情内容
sel = Selector(response)
# 电影名称
name = sel.xpath('//*[@id="content"]/h1/span[1]/text()').extract_first()
# 上映时间
coming_time = sel.xpath('//*[@property="v:initialReleaseDate"]/text()').extract_first()
print(f'{name}上映时间为{coming_time}')
item = TestspiderItem()
item['name'] = name
item['coming_time'] = coming_time
# 这里的yield是把数据返回给通道然后存在数据库
yield item
- 爬取多页的网站
name = 'jobs'
boss_url = 'https://www.zhipin.com/c101270100/?query=python&page=%s&ka=page-%s'
def start_requests(self):
for i in range(1, 6):
print(self.boss_url % (i, i))
yield Request(url=self.boss_url % (i, i),
callback=self.parse_boss)
name = 'guazi'
guazi_urls = 'https://www.guazi.com/cd/buy/o{page}/#bread'
def start_requests(self):
for i in range(1, 51):
print(self.guazi_urls.format(page=i))
yield Request(url=self.guazi_urls.format(page=i),
callback=self.parse_guazi)
1.3.1 要改的settings参数
- 19行
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
为了改ip
- 改settings
- 55行
DOWNLOADER_MIDDLEWARES = {
# 'TestSpider.middlewares.TestspiderDownloaderMiddleware': 543,
'TestSpider.middlewares.ProxyMiddleware': 543,
}
- 改middlewares
class ProxyMiddleware():
def process_request(self, request, spider):
request.meta['proxy'] = 'http://213.178.38.246:51967'
# res = request.get('127.0.0.1:500/get')
# request.meta['proxy'] = 'http://' + res
# 返回None,表示继续执行请求
return None
4. item实体的定义和json格式数据的导出
- item就相当于模型model
items中
import scrapy
class TestspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
coming_time = scrapy.Field()
- 在douabn文件的最后添加
item = TestspiderItem()
item['name'] = name
item['coming_time'] = coming_time
# 这里的yield是把数据返回给通道然后存在数据库
yield item
后台运行 -- 导入json数据
- cd TestSpider
- scrapy crawl douban -o douban.json
- settings最后添加下列代码 - 设置存储中文到json文件中的格式
FEED_EXPORT_ENCODING='utf-8'