
GitHub是一个面向开源及私有软件项目的托管平台、也是项目版本管理工具,会使用它是程序员入门的必备技能。PaddlePaddle也不例外,所有的源码及项目进展都在GitHub上开源公布。但对于刚入门写程序的同学来说,一打开GitHub看起来云里雾里,会有种无从下手的感觉,本文给同学介绍PaddlePaddle在GitHub仓库上的快速上手指南。
PaddlePaddle项目介绍
登录GitHub账号后,会进入到你的主页。在左上角的搜索处搜索PaddlePaddle即可进入PaddlePaddle项目主页面:

在仓库选项卡上方,已经置顶了4个最常用的仓库(Repositories,以下简称Repo):
Paddle:这个Repo中,存放了PaddlePaddle框架的所有代码。由于在Python调用时的包名叫Paddle,仓库遂起名叫Paddle。
Paddle Mobile: Paddle Mobile是移动端及嵌入式设备的深度学习框架。他与PaddlePaddle框架紧密结合,减少中间翻译造成的性能损失,使得运行PaddlePaddle模型时运行性能极高,兼容设备非常广泛,支持安卓、iOS、ARM开发板、麒麟芯片、Mali GPU、骁龙GPU、树莓派等,并且支持FPGA开发板。如果您在进行深度学习移动端开发,强烈建议使用Paddle Mobile框架。
Models:是PaddlePaddle官方的模型库,里面提供了深度学习诸多领域的经典模型复现。在每次PaddlePaddle版本更新后,我们的测试及研发人员都会对其中每一个模型在20种模拟开发环境下进行测试,以确保用户在学习使用中避免出现问题。目前对于仓库内大部分经典模型都应配备了相应的预训练模型,欢迎大家来体验。
Book:Book是Jupyter notebook的简称,是目前主流的机器学习案例教学方案,具有免安装PaddlePaddle、免配置环境、提供交互式web编程页面的优势。PaddlePaddle团队为初学者提供的八个典型的实验案例,包含深度学习主流的几个方向。Book使用Docker+jupyter的打包方案,使初学者即装即用。
后面的部分是PaddlePaddle生态中所有的项目(repo),例如PARL是PaddlePaddle强化学习框架,FluidDoc包含了所有PaddlePaddle相关的文档,这里就不一一列举了。
四大置顶项目介绍
一、GitHub Repo的功能介绍:
进入到Paddle仓库之后(每一个Repo皆是如此)
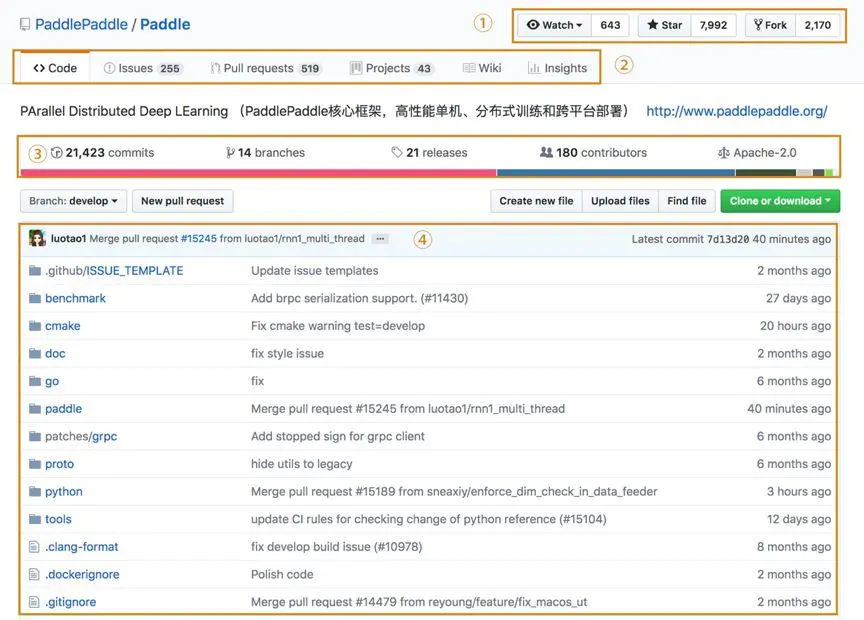
区域①: 右上角有三个按钮:

Watch是对Paddle仓库保持关注,如果此仓库有更新的动态就会推到你的个人主页上。
Star是点赞加收藏的结合体,用户可以通过一个repo的star数来判断公众对他的认可度。您Star过的repo都可以通过点击头像,下拉框中的your star中找到:

Fork是将仓库的代码全部拷贝至你的账户中,除了备份功能外,将来还可以对Paddle项目提交Pull request。
区域②: 在接下来的选项卡中:

Code就是访问这个repo时默认打开的页面,展示了这个repo的代码结构
Issues是向Paddle研发人员提问的小社区,在Paddle的issues中有研发同学24小时值班,大家有问题随时提问哟。
Pull requests里面给大家公示了所有贡献者给Paddle核心分支提交代码的审核进度、审核失败的原因以及那些代码通过了审核。
Projects是GitHub中的项目管理方式,里面展示的是一个一个项目看板,看板上每一个待办的项目的进展进度。
Wiki中是Paddle项目及开发层面上的一些知识文档和规范文档
Insights显示Paddle仓库最近的活动信息、仓库信息和该仓库的各项指标,让用户轻松了解该仓库的活动倾向。
区域③: 再下面一栏中:
![]()
表示此项目有过21423次代码更新,有14条项目分支,公开发布过21个版本,有180个代码贡献者以及遵循Apache-2.0协议规范。下面的彩虹条表示各语言的代码在项目中所占的比例。
二、Paddle Repo介绍:
区域④:占页面的最主要部分是文件内容及代码的目录结构:
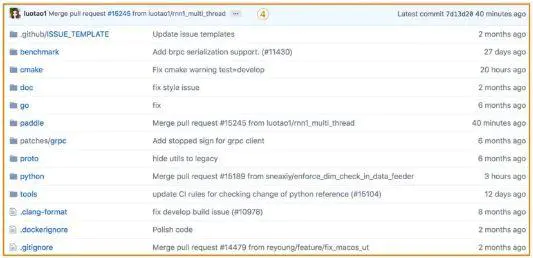
Benchmark目录里存放了性能评测对比的结果、代码以及数据
Cmake目录里存放的是源码编译之间的链式结构
doc目录里存放的是文档文件,但此目录已经不再维护,已迁移至FluidDoc Repo
Go目录里存放的是使用go语言编写具备高性能通信分布式代码。
Paddle目录里存放的是Paddle底层C++以及CUDA的实现代码
Python目录里存放的是Python接口的实现以及调用方式
Tool目录里存放的是一些工程检测和代码调试的工具
在实际开发过程中,看的最多的就是Python目录,在下图目录中展示了Python各种函数接口的实现方法:
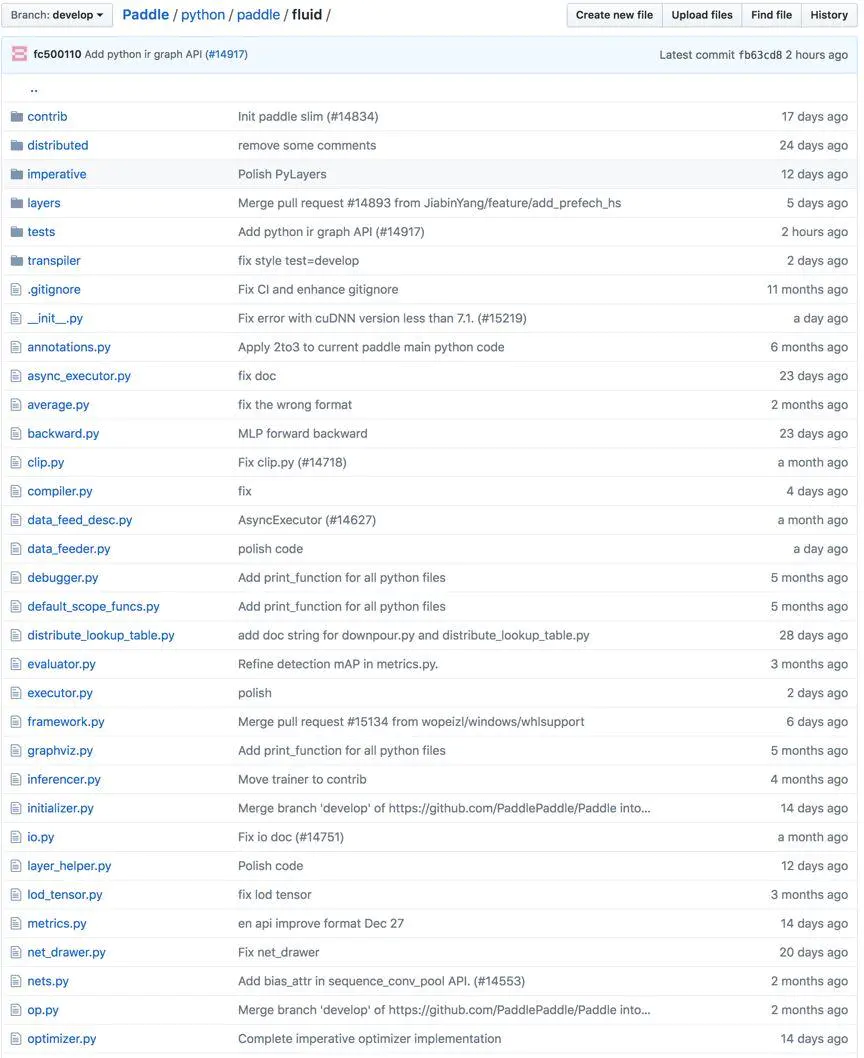
这里有在使用Paddle时用到的各种函数包,例如在Paddle中常见的data_feeder、executor、io、optimizer。如果在开发过程中对某个函数、算子的实现、使用方式比较疑惑,可以在这里直接查看Python接口的源码来弄明白问题。
三、Paddle Mobile Repo介绍:
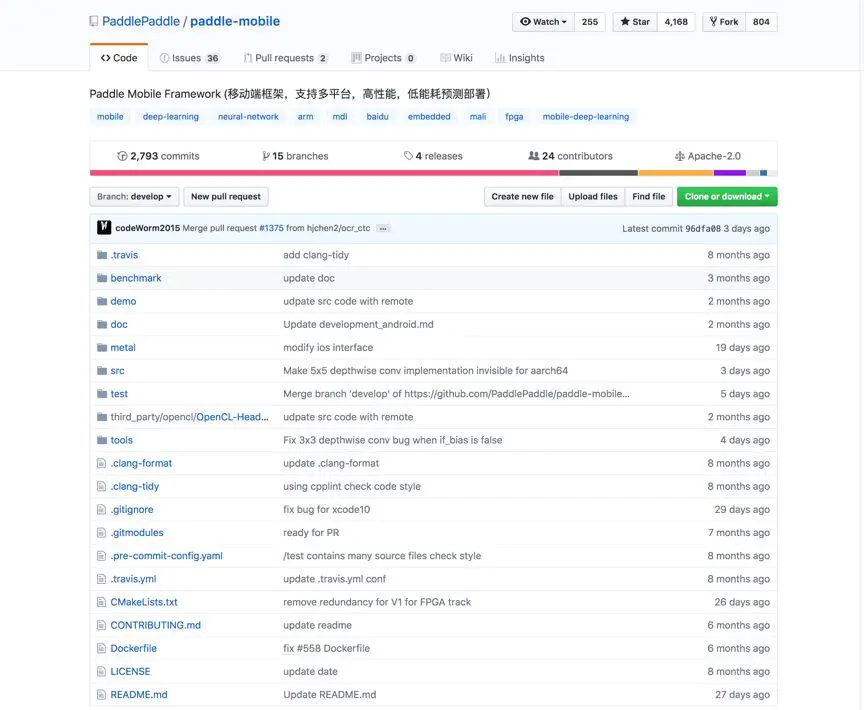
Benchmark是Paddle Mobile框架在各个硬件平台,用各个经典算法的运行效率测试结果。
Demo是官方提供的Paddle Mobile测试demo程序下载脚本,有安卓版和iOS版
Doc里存放着给开发者提供的Paddle Mobile在各个硬件平台的开发指南
Metal是iOS的一个图形渲染框架,里面提供了Paddle Mobile在此框架下的结合代码
Src是source的缩写,里面存放的是Paddle Mobile的实现代码
Test目录里放的是研发人员用来测试模型、op用的工程代码,可以用 CMake编译成二进制执行文件。
Tools里存放的大多是在移动端所需要的调试程序,比如iOS编译程序、安卓调试脚本、中断监视程序。
四、Models Repo:
Models是PaddlePaddle的模型仓库,在此repo中,展示了如何用 PaddlePaddle 来解决常见的机器学习任务,提供若干种不同的易学易用的神经网络模型。
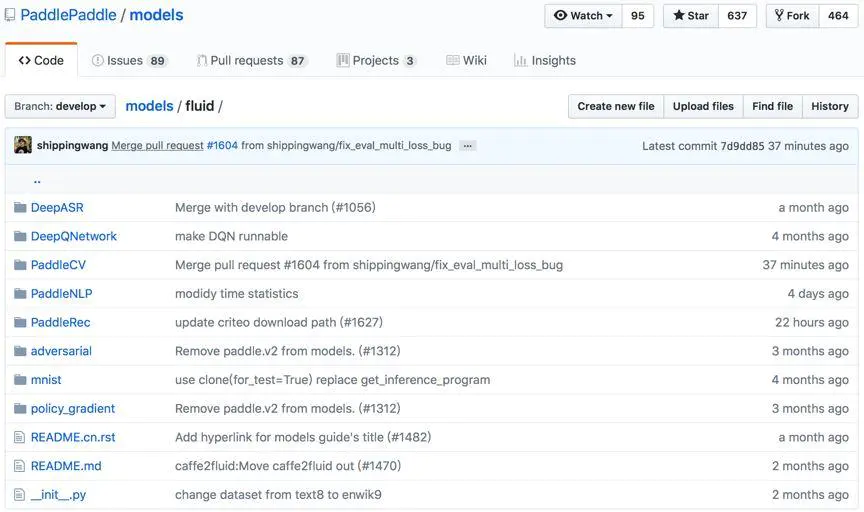
Models下fluid是PaddlePaddle最新版本的模型实现代码,在这里按照深度学习的应用方向(语音合成、图像、自然语言处理、语音转录等)进行分类。
预训练权重地址存放在每个细分项目的readme.md文档里,打开细分项目的文档,拉至最下方,例如image_classification:
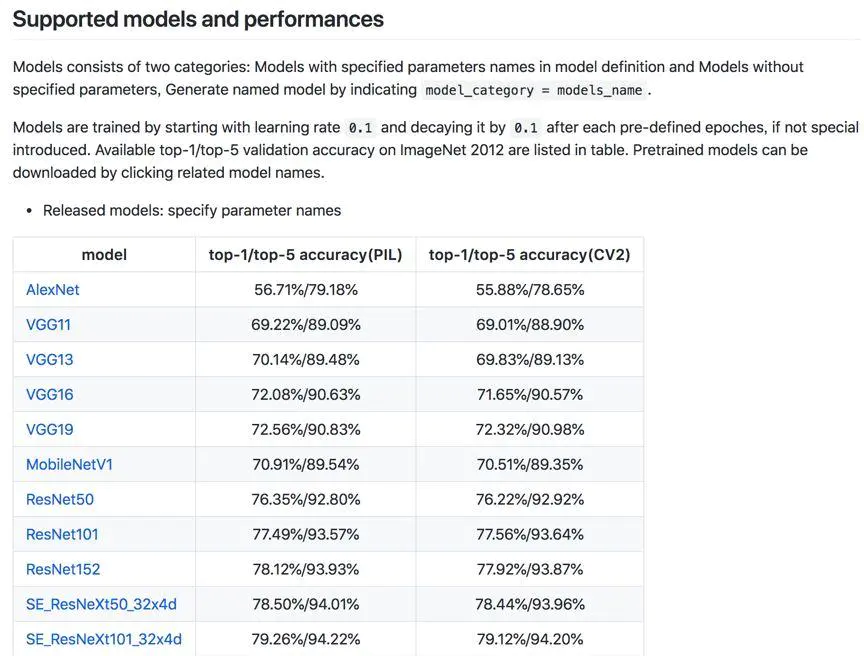
可以看到一个Released models的表格。在表格的model列是模型的名称,这个名称是一个超链接,链接对应的是这个模型的预训练权重下载地址,点击模型名称即可下载相应的预训练模型。
预训练模型使用攻略可参考文章:
《PaddlePaddle预训练模型大合集,还有官方使用说明书》
五、Book Repo:
Book是PaddlePaddle针对初学者的一个特色教程,它是一本“交互式”电子书 —— 每一章都可以运行在一个Jupyter Notebook里。
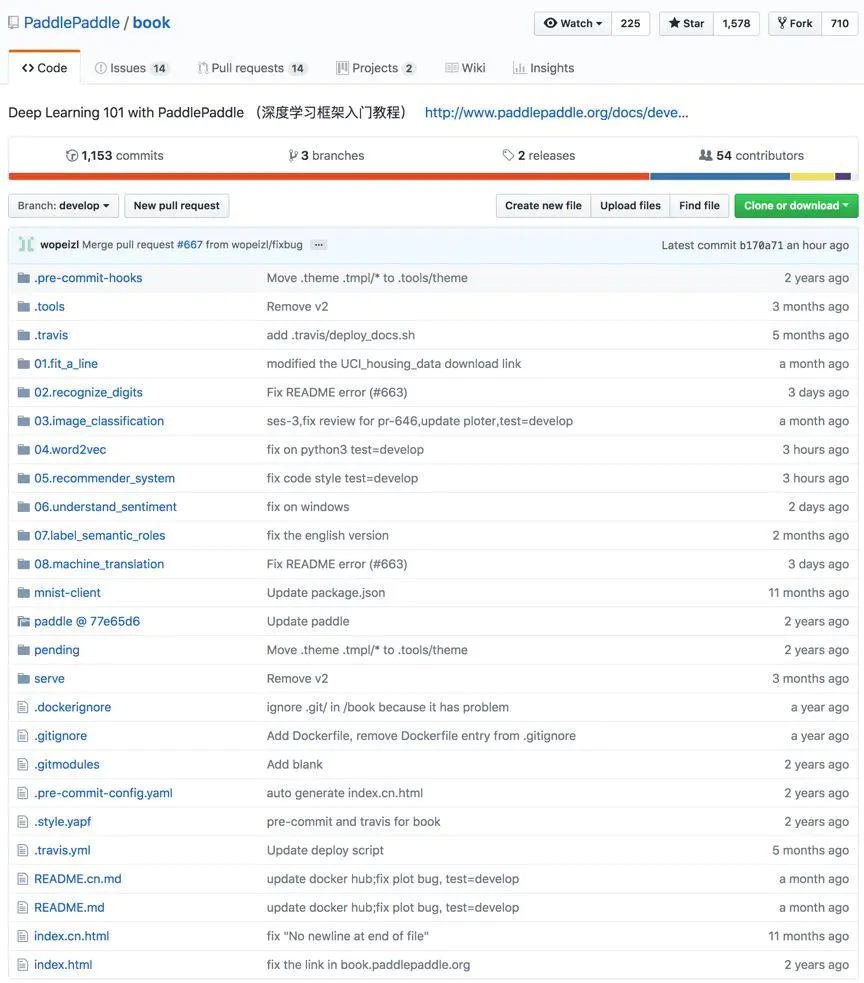
由项目截图可以看出,一共提供了8个学习项目。学习项目安排得不仅循序渐进,而且包含了多个目前深度学习的主流方向:图像分类、抽象数据处理、推荐系统、文本序列化、角色语义标注、情感分析系统、机器翻译系统。
Paddle-book将Jupyter、PaddlePaddle、以及各种被依赖的软件都打包进一个Docker image了。所以您不需要自己来安装各种软件以及PaddlePaddle,只需要安装Docker即可。
安装Docker后,只需要在命令行窗口里运行一步,就会从DockerHub.com下载和运行本书的Docker image:
docker run -d -p 8888:8888 paddlepaddle/book
下载完成后,在本地浏览器中访问 http://localhost:8888,即可阅读和在线编辑本书。由于Jupyter的特性,您甚至可以直接在上面运行代码。
Paddle-book漫游指南就到这里结束了,想了解更多的小伙伴可以登录PaddlePaddle的GitHub体验一下:https://github.com/PaddlePaddle/。
您也可以登录PaddlePaddle的官网:www.paddlepaddle.org,通过右上方的链接进入:

新年就要到啦,祝大家在新的一年里PaddlePaddle学的愉快,用的舒心。