
从现代编译器的角度看,解释器和编译器的边界已经相当的模糊。我们后面的讨论说到的编译器就是Python的解释器,没有特别说明的指的是CPython的实现。
内存管理(Memory Management)
在讨论编译器的具体实现之前,我们不得不了解一下在这里面内存是如何井然有序地被分配的。为了让内存分配简单一些,一般我们都会建立一个Arena(不知道用中文怎么准确的表达)来管理内存。有了Arena我们就可以把内存集中在一起更容易地进行分配和销毁。在这里面没有了真正的内存的释放,也就是说内存的释放不会显式地对应系统的free(3)调用。也正是由于编译器每部每次内存的分配对于Arena都只是一次注册,释放编译器用到的所有内存也变得非常的简单:仅仅需要一次free(3)系统调用就可以达成。
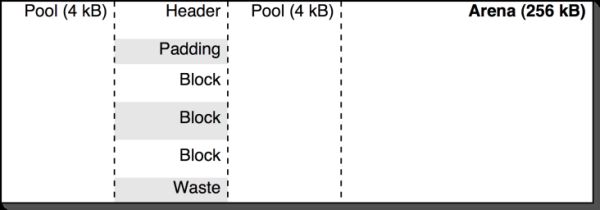
一般来说,除非你是在研究或者开发编译器最核心的部分,才需要关注内存分配的问题。Python解释器里所有内存分配相关的代码都在Include/pyarena.h (https://github.com/python/cpython/blob/master/Include/pyarena.h)和 Python/pyarena.c(https://github.com/python/cpython/blob/master/Python/pyarena.c)可以找到。
BTW,这里有一个我很久以前实现的一个定长内存池(Fixed Sized Pool)的源码,代码量很少,希望可以有助于大家了解内存池的概念:https://github.com/auxten/gkoAlloc/blob/master/memory.cpp
PyArena_New()函数会帮我们创建一个新的Arena,并返回一个PyArena 结构体,这个结构体将会保存所有分配给此Arena的内存的指针。在编译器完成工作释放内存退出之前,都是由Arena负责对所有用到的内存进行“记账”。释放内存对应的API是PyArena_Free()。基本上,每个编译器只需要在最后的“战略大撤退”时调用它一次即可。
综上所述,内存池的设计初衷就是让我们在进行编译器的各项工作的时候不用去关心内存分配的各种细节。因此,我们研究编译器的绝大多数时候也可以先跳过这部分的内容。
唯一的一个例外就是在管理PyObject的时候。由于Python使用引用计数的方式进行内存垃圾回收,所以在Arena上增加了一些机制对它进行额外的支持,以便垃圾回收的时候能正确的处理每一个PyObject。虽然这种例外是很少见的,但是如果你在编译器的代码里分配一个PyObject,你必须通过调用PyArena_AddPyObject()来通知Arena增加相应的引用计数。
从语法树到抽象语法树(AST)
通过调用Python源码中的PyAST_FromNode()函数,语法树(参见Python/ast.c(https://github.com/python/cpython/blob/master/Python/ast.c#L883))被转换成抽象语法树(AST)。
mod_ty
PyAST_FromNode(const node *n, PyCompilerFlags *flags, const char *filename_str,
PyArena *arena)
{
mod_ty mod;
PyObject *filename;
filename = PyUnicode_DecodeFSDefault(filename_str); if (filename == NULL) return NULL;
mod = PyAST_FromNodeObject(n, flags, filename, arena);
Py_DECREF(filename); return mod;
}
PyAST_FromNode()函数对语法树进行树形遍历,在遍历的过程中动态创建出各种类型的AST节点。简单来说,就是遍历每一个节点,为每一个语法节点调用相对应的AST节点的构造函数,以及相关的支持函数,按照节点的组织方式对他们进行“连接”。
为了继续下面的内容,我们要简单介绍一下yacc,简单来说,yacc就是编译器的编译器:
yacc(Yet Another Compiler Compiler),是Unix/Linux上一个用来生成编译器的编译器(编译器代码生成器)。yacc生成的编译器主要是用C语言写成的语法解析器(Parser),需要与词法解析器Lex一起使用,再把两部分产生出来的C程序一并编译。yacc本来只在Unix系统上才有,但现时已普遍移植往Windows及其他平台。
yacc的输入是巴科斯范式(BNF)表达的语法规则以及语法规约的处理代码,Yacc输出的是基于表驱动的编译器,包含输入的语法规约的处理代码部分。
yacc是开发编译器的一个有用的工具,采用LALR(1)语法分析方法。
yacc最初由AT&T的Steven C. Johnson为Unix操作系统开发,后来一些兼容的程序如Berkeley Yacc,GNU bison,MKS yacc和Abraxas yacc陆续出现。它们都在原先基础上做了少许改进或者增加,但是基本概念是相同的。
由于所产生的解析器需要词法分析器配合,因此Yacc经常和词法分析器的产生器——一般就是Lex——联合使用。IEEE POSIX P1003.2标准定义了Lex和Yacc的功能和需求。
——摘自Wikipedia
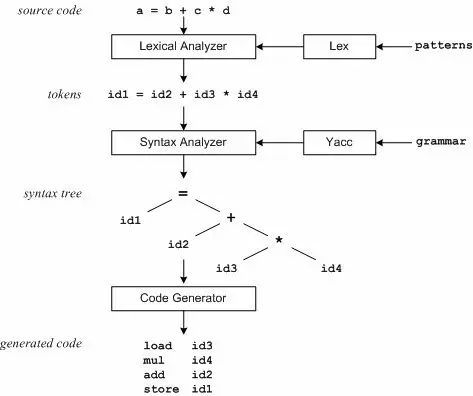
需要格外注意的是,在语法规范和解析树中的节点之间没有自动化或符号连接。这点上Python解释器和yacc不同。
例如,就像我们处理“if”这个语法结构时,必须关注“:”这个token出现的位置,来决定“if”后面的条件语句的结束位置一样。跟踪我们正在使用解析树中哪个节点是十分必要的。
调用从解析树生成AST节点的函数都被命名为ast_for_xx,其中xx是函数处理的语法规则(但是,alias_for_import_name这个函数是个例外)。这些ast_for_xx函数会依次调用由ASDL语法定义的构造函数以及包含在Python/Python-ast.c(https://github.com/python/cpython/blob/master/Python/Python-ast.c)(由Parser/asdl_c.py(https://github.com/python/cpython/blob/master/Parser/asdl_c.py)生成)的构造函数以创建AST的节点。这样下来,所有的AST节点就全部存储在asdl_seq结构体中了。
创建和使用asdl_seq *类型的函数和宏都在 Python/asdl.c(https://github.com/python/cpython/blob/master/Python/asdl.c) 和 Include/asdl.h(https://github.com/python/cpython/blob/master/Include/asdl.h)中:
- asdl_seq *_Py_asdl_seq_new(Py_ssize_t size, PyArena *arena);
- 在arena上分配size个长度的asdl_seq
- asdl_seq_GET(S, I)
- 获取S(类型是asdl_seq*)的I位置的元素
- asdl_seq_SET(S, I, V)
- 把S的指定位置I上的元素置为V
- asdl_seq_LEN(S)
返回S的长度
如果你正在处理Python的代码语句,代码语句的行号是一个绕不开的问题。目前来说,行号作为最后一个参数传递给每个stmt_ty函数的。这点在以后的Python解释器实现中可能会有改变。
相关文章推荐
浅析Python解释器的设计(一)
招生课程:
Python 实战班第 18 期
自动化运维课程第 7 期
golang 课程第 3 期
架构师班第 7 期
咨询方式:
QQ(1):979950755 小月
WeChat : 1902433859 小月