本文参考从机器学习谈起, 麦子学院机器学习
简单来说,机器学习相当于人类的学习的归纳演绎,利用已有的数据进行学习归纳,最终达到预测的目的。
基本概念
训练集(training set/data)/训练样例(training examples): 用来进行训练,也就是产生模型或者算法的数据集.
测试集(testing set/data)/测试样例 (testing examples):用来专门进行测试已经学习好的模型或者算法的数据集.
特征向量(features/feature vector):属性的集合,通常用一个向量来表示,附属于一个实例.
标记(label): c(x), 实例类别的标记,也即目标的类别。
回归算法有两个重要的子类:线性回归和逻辑回归。
简单来讲,线性回归就是找出各个自变量(特征向量)与因变量(标记)相关关系的算法,线性回归处理的大都是数值问题,目标标记为连续性数值 (continuous numeric value),也就是最后预测出的结果是数字,例如房价。而逻辑回归属于分类算法,目标标记为类别型数据(category), 也就是说,逻辑回归预测结果是离散的分类,例如判断这封邮件是否是垃圾邮件。
从训练集有无标记可将算法分为监督学习,半监督学习以及无监督学习:
- 有监督学习(supervised learning): 训练集有类别标记(class label)
- 无监督学习(unsupervised learning): 无类别标记(class label)
- 半监督学习(semi-supervised learning):有类别标记的训练集 + 无标记的训练集
机器学习方法
1.线性回归(Linear Regression)
线性回归属于回归算法,其可分为两个次类:简单线性回归(Simple Linear Regression)和多元线性回归。
简单线性回归及只含一个自变量和一个因变量,利用一条直线来模拟两者之间的关系。当自变量升级为多个时便称为多元线性回归(multiple regression)。

2. 决策树(decision tree)
决策树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。应用:银行信用自动评估系统。
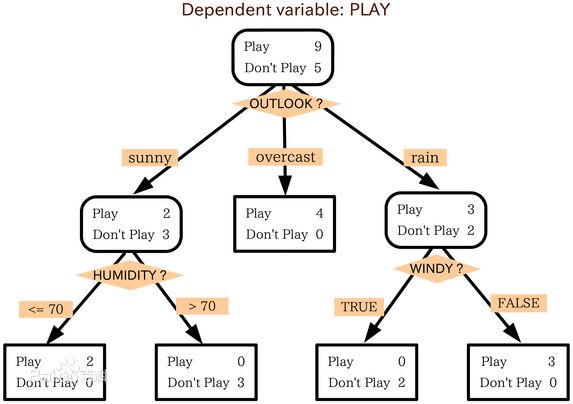
算法:
(1)树以代表训练样本的单个结点开始。
(2)如果样本都在同一个类,则该结点成为树叶,并用该类标号。否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性。该属性成为该结点的“测试”或“判定”属性。在算法的该版本中,所有的属性都是分类的,即离散值。连续属性必须离散化。
(3)对测试属性的每个已知的值,创建一个分枝,并据此划分样本。
(4)算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它。递归划分步骤仅当下列条件之一成立停止:
(a) 给定结点的所有样本属于同一类。
(b) 没有剩余属性可以用来进一步划分样本。在此情况下,使用多数表决。这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结点样本的类分布。
(c) 分枝test_attribute =ai没有样本。在这种情况下,以samples中的多数类创建一个树叶。
决策树的优点:直观,便于理解,小规模数据集有效
决策树的缺点:处理连续变量不好;类别较多时,错误增加的比较快;可规模性一般。
3. 临近取样(k-Nearest Neighbor)
临近取样即以所有已知类别的实例作为参照,判断未知实例的类别。
算法步骤:为了判断未知实例的类别,需选择K个距离此未知实例最近的实例(点),根据少数服从多数的投票法则(majority-voting),未知实例与这K个最邻近实例中个数较多的类别属于同一类。因此参数K最好选择奇数。
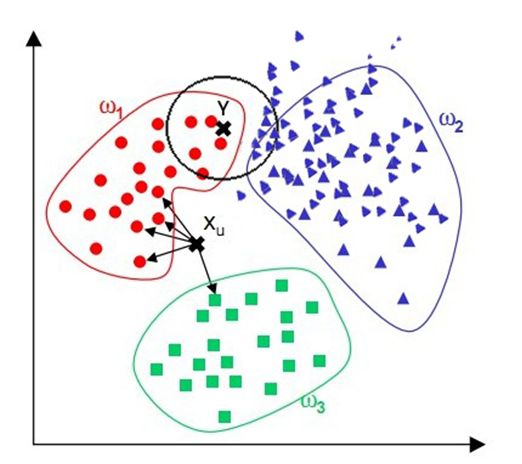
算法优点:简单;易于理解;容易实现;通过对K的选择可具备对抗噪音数据的健壮性。
算法缺点:需要大量空间储存所有已知实例;算法复杂度高(需要比较所有已知实例与要分类的实例);当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本。
改进版本:考虑距离,根据距离加上权重;比如: 1/d (d: 距离)。
4. 支持向量机(SVM)
支持向量机算法是诞生于统计学习界,同时在机器学习界大放光彩的经典算法。
支持向量机算法从某种意义上来说是逻辑回归算法的强化:通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。但是如果没有某类函数技术,则支持向量机算法最多算是一种更好的线性分类技术。
但是,通过跟高斯“核”的结合,支持向量机可以表达出非常复杂的分类界线,从而达成很好的的分类效果。“核”事实上就是一种特殊的函数,最典型的特征就是可以将低维的空间映射到高维的空间。
算法原理:找出离两个(或多个)分类中实例的距离最小的线,当数据集在平面或和低维空间中难以区分时,常常需要将其映射到高维空间中来寻找用以区分各个实例类的平面。
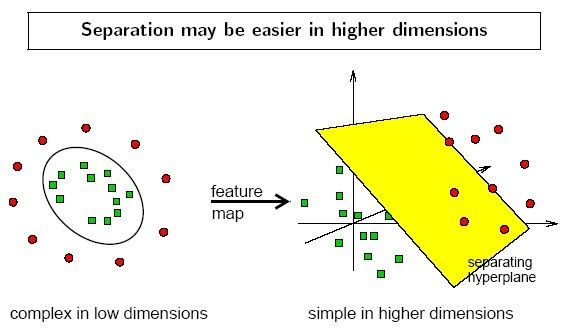
SVM扩展可解决多个类别分类问题,对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)。
5. 神经网络(Nerual Network)
神经网络(也称之为人工神经网络,ANN)算法是80年代机器学习界非常流行的算法,不过在90年代中途衰落。现在,携着“深度学习”之势,神经网络重装归来,重新成为最强大的机器学习算法之一。
神经网络的诞生起源于对大脑工作机理的研究。早期生物界学者们使用神经网络来模拟大脑。机器学习的学者们使用神经网络进行机器学习的实验,发现在视觉与语音的识别上效果都相当好。在BP算法(加速神经网络训练过程的数值算法)诞生以后,神经网络的发展进入了一个热潮。BP算法的发明人之一是机器学习大牛Geoffrey Hinton。
具体说来,神经网络的学习机理是什么?简单来说,就是分解与整合。在著名的Hubel-Wiesel试验中,学者们研究猫的视觉分析机理是这样的。
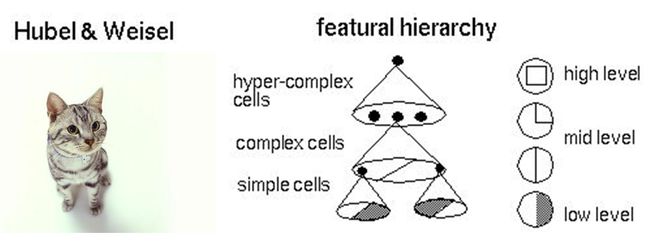
比方说,一个正方形,分解为四个折线进入视觉处理的下一层中。四个神经元分别处理一个折线。每个折线再继续被分解为两条直线,每条直线再被分解为黑白两个面。于是,一个复杂的图像变成了大量的细节进入神经元,神经元处理以后再进行整合,最后得出了看到的是正方形的结论。这就是大脑视觉识别的机理,也是神经网络工作的机理。 让我们看一个简单的神经网络的逻辑架构。在这个网络中,分成输入层,隐藏层,和输出层。输入层负责接收信号,隐藏层负责对数据的分解与处理,最后的结果被整合到输出层。每层中的一个圆代表一个处理单元,可以认为是模拟了一个神经元,若干个处理单元组成了一个层,若干个层再组成了一个网络,也就是"神经网络"。

在神经网络中,每个处理单元事实上就是一个逻辑回归模型,逻辑回归模型接收上层的输入,把模型的预测结果作为输出传输到下一个层次。通过这样的过程,神经网络可以完成非常复杂的非线性分类。
下图会演示神经网络在图像识别领域的一个著名应用,这个程序叫做LeNet,是一个基于多个隐层构建的神经网络。通过LeNet可以识别多种手写数字,并且达到很高的识别精度与拥有较好的鲁棒性。

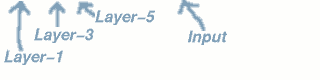
右下方的方形中显示的是输入计算机的图像,方形上方的红色字样“answer”后面显示的是计算机的输出。左边的三条竖直的图像列显示的是神经网络中三个隐藏层的输出,可以看出,随着层次的不断深入,越深的层次处理的细节越低,例如层3基本处理的都已经是线的细节了。LeNet的发明人是机器学习的大牛Yann LeCun。
进入90年代,神经网络的发展进入了一个瓶颈期。其主要原因是尽管有BP算法的加速,神经网络的训练过程仍然很困难。因此90年代后期支持向量机(SVM)算法取代了神经网络的地位。
6. K-means算法
前面讲的几种算法都属于监督学习,而K-means属于非监督学习中最典型的代表之一。K-means算法属于聚类算法。
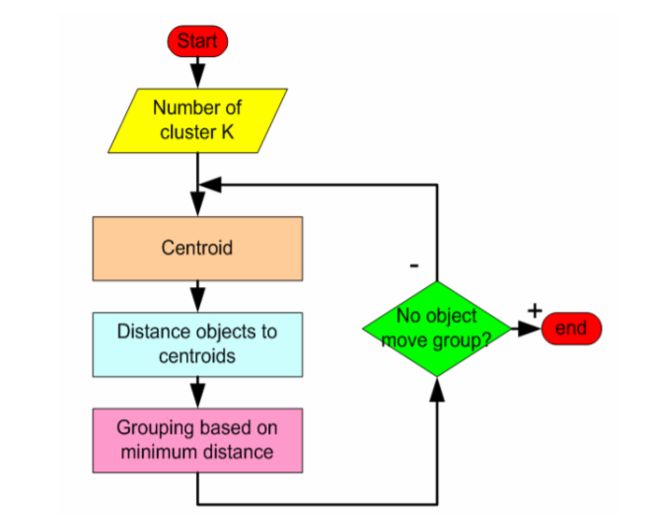
K-means算法原理:K-means算法的前提是需先知道数据集分为K类。
(1)任意选取每一类的中心值(点)。
(2)计算其他的点(实例)到各个分类中心值的距离,根据距离的大小将各个待分类的点,距离最近的为同一类,如此将所有点归类完成。
(3)将分好的各类取平均值为中心值,然后再次将所有的点计算距离进行分类。
(4)如此循环往复,直到某次分类计算结果与上次一样,则停止循环计算;或达到人为设定分类次数后终止计算,最后所得即为分类结果。
K-means算法优点:速度快,简单。
K-means算法缺点:最终结果跟初始点选择相关,容易陷入局部最优;需先知道K值。
7. 层次聚类(Hierarchical Clustering)
层次聚类对样品中的每一个样品计算其与其他样品间的距离。
假设有N个待聚类的样本,对于层次聚类来说,步骤:
1、(初始化)把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度;
2、寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个);
3、重新计算新生成的这个类与各个旧类之间的相似度;
4、重复2和3直到所有样本点都归为一类,结束。
整个聚类过程其实是建立了一棵树,在建立的过程中,可以通过在第二步上设置一个阈值,当最近的两个类的距离大于这个阈值,则认为迭代可以终止。另外关键的一步就是第三步,如何判断两个类之间的相似度有不少种方法。这里介绍一下三种:
SingleLinkage:又叫做 nearest-neighbor ,就是取两个类中距离最近的两个样本的距离作为这两个集合的距离,也就是说,最近两个样本之间的距离越小,这两个类之间的相似度就越大。容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
CompleteLinkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。这两种相似度的定义方法的共同问题就是指考虑了某个有特点的数据,而没有考虑类内数据的整体特点。
Average-linkage:这种方法就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
average-linkage的一个变种就是取两两距离的中值,与取均值相比更加能够解除个别偏离样本对结果的干扰。