1.SELECT语句的语法:
SELECT
column_1,column_2,...
FROM table_1
[INNER|LEFT|RIGHT] JOIN table_2 ON conditions
WHERE conditions
GROUPBY column_1
HAVING group_conditions
ORDERBY column_1
LIMIT offset,length;
SQL
SELECT语句由以下列表中所述的几个子句组成:
SELECT之后是逗号分隔列或星号(*)的列表,表示要返回所有列。
FROM指定要查询数据的表或视图。
JOIN根据某些连接条件从其他表中获取数据。
WHERE过滤结果集中的行。
GROUP BY将一组行组合成小分组,并对每个小分组应用聚合函数。
HAVING过滤器基于GROUP BY子句定义的小分组。
ORDER BY指定用于排序的列的列表。
LIMIT限制返回行的数量。
语句中的SELECT和FROM语句是必须的,其他部分是可选的。
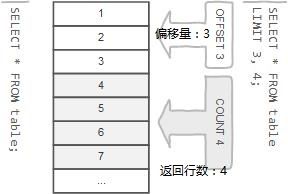
2.在SELECT语句中使用LIMIT子句来约束结果集中的行数。LIMIT子句接受一个或两个参数。两个参数的值必须为零或正整数。
下面说明了两个参数的LIMIT子句语法:
SELECT column1,column2,...
FROM table
LIMIT offset,count;
SQL
我们来查看LIMIT子句参数:
offset参数指定要返回的第一行的偏移量。第一行的偏移量为0,而不是1。
count指定要返回的最大行数。
LIMIT子句经常与ORDER BY子句一起使用。首先,使用ORDER BY子句根据特定条件对结果集进行排序,然后使用LIMIT子句来查找最小或最大值。
注意:ORDER BY子句按指定字段排序的使用。
使用MySQL LIMIT获得第n个最高值
首先,按照降序对结果集进行排序。
第二步,使用LIMIT子句获得第n贵的产品。
SELECT column1,column2,...
FROM table
ORDERBY column1 DESC
LIMIT nth-1,count;
当使用BETWEEN运算符与日期类型值时,要获得最佳结果,应该使用类型转换将列或表达式的类型显式转换为DATE类型。
例如,要查询获取所需日期(requiredDate)从2013-01-01到2013-01-31的所有订单,请使用以下查询:
SELECT
orderNumber,requiredDate,status
FROM orders
WHERE requireddate
BETWEEN CAST('2013-01-01'ASDATE)
AND CAST('2013-01-31'ASDATE);
MySQL提供两个通配符,用于与LIKE运算符一起使用,它们分别是:百分比符号 -%和下划线 -_。
百分比(%)通配符允许匹配任何字符串的零个或多个字符。
下划线(_)通配符允许匹配任何单个字符
有时想要匹配的模式包含通配符,例如10%,_20等这样的字符串时。在这种情况下,您可以使用ESCAPE子句指定转义字符,以便MySQL将通配符解释为文字字符。如果未明确指定转义字符,则反斜杠字符\是默认转义字符。
UPDATE[LOW_PRIORITY][IGNORE]table_nameSETcolumn_name1=expr1,column_name2=expr2,...WHEREcondition;
SQL
在上面UPDATE语句中:
首先,在UPDATE关键字后面指定要更新数据的表名。
其次,SET子句指定要修改的列和新值。要更新多个列,请使用以逗号分隔的列表。以字面值,表达式或子查询的形式在每列的赋值中来提供要设置的值。
第三,使用WHERE子句中的条件指定要更新的行。WHERE子句是可选的。 如果省略WHERE子句,则UPDATE语句将更新表中的所有行。
请注意,WHERE子句非常重要,所以不应该忘记指定更新的条件。 有时,您可能只想改变一行; 但是,可能会忘记写上WHERE子句,导致意外更新表中的所有行。
MySQL在UPDATE语句中支持两个修饰符。
LOW_PRIORITY修饰符指示UPDATE语句延迟更新,直到没有从表中读取数据的连接。LOW_PRIORITY对仅使用表级锁定的存储引擎(例如MyISAM,MERGE,MEMORY)生效。
即使发生错误,IGNORE修饰符也可以使UPDATE语句继续更新行。导致错误(如重复键冲突)的行不会更新。
1、主键:
若某一个属性组(注意是组)能唯一标识一条记录,该属性组就是一个主键。主键不能重复,且只能有一个,也不允许为空。定义主键主要是为了维护关系数据库的完整性。
2、外键:
外键用于与另一张表的关联,是能确定另一张表记录的字段。外键是另一个表的主键,可以重复,可以有多个,也可以是空值。定义外键主要是为了保持数据的一致性。
3、索引:
索引是对表中一个或多个列的值进行排序的结构。
1) 应该创建索引的列的特点:
① 在经常需要搜索的列上创建索引,可以加快搜索的速度;
② 在作为主键的列上创建索引,强制该列的唯一性;
③ 在经常用在连接的列上创建索引,主要是一些外键,可以加快连接的速度;
④ 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,可以利用索引的排序加快查询;
⑤ 在经常使用在WHERE子句中的列上创建索引,加快条件的判断速度。
2) 不应该创建索引的列的特点:
① 在查询中很少使用的列上不应该创建索引,因为这些列很少使用到,因此有索引或无索引,并不能提高查询速度,相反由于增加了索引,反而降低了系统维护速度,增大了空间需求;
② 在只有很少数据值的列上不应该创建索引,很少数据值的列如性别等,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大,增加索引,并不能明显加快检索速度;
③ 当修改性能远远大于检索性能时,不应该创建索引,因为改性能和检索性能是互相矛盾的,当增加索引时,会提高检索性能,但会降低修改性能,当减少索引时,会提高修改性能,但会降低检索性能。因此,当修改性能远大于检索性能时,不应该创建索引。
3) 可以在数据库设计器中创建三种索引:
① 唯一索引:
不允许其中任何两行具有相同索引值的索引。
② 主键索引:
表的某一列或列组合,其值唯一标识表中的每一行,该列或列组合称为表的主键。为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。
③ 聚集索引:
聚集索引:聚集索引表示表中存储的数据按照索引的顺序存储。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。
聚集索引实例:字典默认按字母顺序排序,如知道某个字的读音可根据字母顺序快速定位。
非聚集索引:非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置,需要查询两个地方才能查找到数据。一个表可以包含多个非聚集索引,可以为查找数据时常用的每个列创建一个非聚集索引。
非聚集索引实例:如需查询某个生僻字,则需按字典前面的索引,如按偏旁进行定位,找到该字对应的页数,再打开对应页数找到该字。
与非聚集索引相比,聚集索引通常提供更快的数据访问速度,但对数据更新影响较大。
4)索引的优点:
加快对数据的检索。
5)索引的缺点:
①减慢数据录入的速度;
②增加了数据库的尺寸大小。
4、主键和外键的关系:
外键是另一个表的主键,主键是可以被外键有效引用的对象。若A表中的一个字段,是B表的主键,则它可以是A表的外键。
5、主键和外键以及索引的区别:
定义作用个数
主键唯一标识一条记录,不能有重复,不允许为空保证数据完整性只能有一个主键
外键另一表的主键,可以重复,允许为空和其他表建立联系可以有多个外键
索引没有重复值,但可以有一个空值提高查询排序的速度可以有多个唯一索引
mysql索引原理:
索引的目的在于提高查询效率;
磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右。考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
建索引的几大原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
视图
什么是视图:视图就是一条SELECT语句执行后返回的结果集。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
视图的特性:视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,不存储具体的数据(基本表数据发生了改变,视图也会跟着改变);
可以跟基本表一样,进行增删改查操作(ps:增删改操作有条件限制);
视图的作用:方便操作,特别是查询操作,减少复杂的SQL语句,增强可读性;
更加安全,数据库授权命令不能限定到特定行和特定列,但是通过合理创建视图,可以把权限限定到行列级别;
使用场合:权限控制的时候,不希望用户访问表中某些含敏感信息的列,比如salary...
关键信息来源于多个复杂关联表,可以创建视图提取我们需要的信息,简化操作;
视图实例1-创建视图及查询数据操作
视图实例2-增删改数据操作
其它