本节内容:
拼写纠错
停用词过滤
NLP项目一般流程:

一、分词
常用分词工具:
- Jieba分词https://github.com/fxsjy/jieba
- SnowNLP https://github.com/isnowfy/snownlp
- LTP http://www.ltp-cloud.com/
- HanNLP https://github.com/hankcs/HanLP/
- ...
1.1 最大匹配
前向最大匹配(forward-max matching)
例子:我们经常有意见分歧
词典:[“我们”, “经常”, “有”, “有意见”,“意见”,“分歧”]
假设max-len设为5
第一轮,选定前五个字
[我们经常有],词典中没有单词匹配,去掉最后一个字
[我们经常],词典中没有单词匹配,去掉最后一个字
[我们经],词典中没有单词匹配,去掉最后一个字
[我们],词典中有单词匹配
第二轮,选定我们后面的五个字
[经常有意见],词典中没有单词匹配,去掉最后一个字
[经常有意],词典中没有单词匹配,去掉最后一个字
[经常有],词典中没有单词匹配,去掉最后一个字
[经常],词典中有单词匹配
第三轮,选定经常后面的五个字
[有意见分歧],词典中没有单词匹配,去掉最后一个字
[有意见分],词典中没有单词匹配,去掉最后一个字
[有意见],词典中有单词匹配
第四轮,选定有意见后面的五个字
[分歧],词典有单词匹配
分词结果:我们 经常 有意见 分歧
后向最大匹配
例子:我们经常有意见分歧
词典:[“我们”, “经常”, “有”, “有意见”,“意见”,“分歧”]
假设max-len设为5
第一轮,选定最后5个子
[常有意见分歧],词典中没有单词匹配,去掉最前一个字
[有意见分歧],词典中没有单词匹配,去掉最前一个字
[意见分歧],词典中没有单词匹配,去掉最前一个字
[见分歧],词典中没有单词匹配,去掉最前一个字
[分歧],词典中有单词匹配
第二轮,选定分歧前5个字
[经常有意见],词典中没有单词匹配,去掉最前一个字
[常有意见],词典中没有单词匹配,去掉最前一个字
[有意见],词典中有单词匹配
第三轮,选定有意见前5个字
[我们经常],词典中没有单词匹配,去掉最前一个字
[们经常],词典中没有单词匹配,去掉最前一个字
[经常],词典中有单词匹配
第四轮,选定经常前5个字
[我们],词典中有单词匹配
分词结果:我们 经常 有意见 分歧
后向前向最大匹配都是贪心算法,缺点:细分,可能有更好的,局部最优,效率低,没考虑语义
1.2 考虑语义

选择其中最好的要根据工具选择
最经典的工具是语言模型(Language Model)
s1 = 经常 有 意见 分歧
s2 = 经常 有意见 分歧
语言模型可以计算概率 P(s1)、P(s2)
P(经常,有,意见,分歧) = P(经常)P(有)P(意见)P(分歧)
P(经常,有意见,分歧) = P(经常)P(有意见)P(分歧)
概率是如何得到呢?
比如,有一本大部头的书,统计每个单词出现的次数,单词出现次数/所有词的数量 就是这个单词的概率了。
某个单词的概率P往往非常小,多个单词的概率相乘容易引发溢出错误(underflow)
于是,我们往往加log,比如计算logP(经常,有,意见,分歧)=logP(经常) + logP(有) + logP(意见) + logP(分歧),转为了加法
log可以保证P(s1)>P(s2)时,logP(s1)>logP(s2)
缺点:复杂度非常高,因为要生成所有可能的分割组合。
1.3 维特比算法
上面的方法分两步:step1,生成所有可能分割;step2,选择最好的。
两步合并能不能降低复杂度呢?


蓝直线,代表一个字,上面的数字是其概率,假设词典没有出现的单词其概率为20
蓝曲线箭头,将词典中出现的词的字连起来,将词的概率标注在线的上面,比如经常的概率为2.3
于是所有蓝线可以进行组合从1到8,每个组合都是一个分词结果,找到概率和最小的路径即可
假设
f(8):从节点1到8的最短路径的值
f(7):从节点1到7的最短路径的值
f(6):从节点1到6的最短路径的值
...
先看f(8),只用一步有几条路到第8个节点呢
5->8,6->8,7->8
因此,f(8)就是下面的最小值
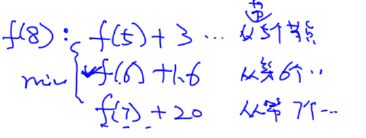
那么f(7):f(6) + 2.3
f(6):

f(5):f(4) + 3
...
因此,我们可以计算f(1)、f(2)、f(3)...f(8)

上面是最短路径,下面是最短路径对应的节点,比如f(8)最短路径值是6.2,对应的上一个节点是6,节点6最短路径值是4.6,对应节点是3,节点3最短路径值是2.3,对应节点是1
因此,1368是最佳组合,分词是: 经常 有意见 分歧
维护数组

二、错误拼写纠正(Spell Correction)

最经典方法计算编辑距离

一般有三个操作:insert、delete、replace,成本都是1
therr变为there,需要把r替换为1,成本为1
therr变为their,需要把r替换为i,成本为1
therr变为thesis,需要r替换为s,增加一个i,r替换为s,成本为3
therr变为theirs,需要r替换为i,增加一个s,成本为2
therr变为the,需要删除两个r,成本为2
因此,there和their是最佳选择,此时需要根据上下文、词频判断,返回最佳的一个单词。
循环词典,找出最佳编辑距离的词,复杂度非常高是O(V),其中V是词典中所有的单词。
dp算法的核心是问题拆分
dp算法练习题:https://people.cs.clemson.edu/~bcdean/dp_practice/
有什么方法降低时间复杂度呢?

主动生成想要的字符串,选择编辑距离1和2,是因为这两种情况可以覆盖绝大多数场景
通过独立使用add、replace、delete三种操作生成编辑为1的字符串组合
生成编辑为1的字符串后,再重复上面操作,生成编辑距离为2的字符串
生成大量字符串后,如何选择最合适的字符串呢?

比如,正确apple
用户1:app
用户2:appl
用户3:appl
用户4:app
用户5:appla
用户6:appl
P(appl|apple)=3/6=50%
P(app|apple)=2/6=33.3%
P(s|c):c是正确的单词,对于一个正确的字符串,有百分之多少的人写成了s的形式?
P(c):c在整个文档中出现的概率,倾向于选最可能出现的单词
三、词过虑
通常把停用词、出现频率很低的词汇过滤掉。
待续