本文的主题都是关于函数的
1. 函数的语法;
2. 函数的对象;
3. 函数装饰器;
4. lambda表达式;
5. Python内置函数;
6.
主题三:程序过程与设计
目标
-
应用目标
-
- 阶段实战:
- 股票查询系统的查询结果翻页显示;
- 信息系统的选择菜单;
-
- 综合实战:
-
完成股票查询系统的程序结构;
 面向过程的程序设计
面向过程的程序设计 完成信息管理系统的程序结构;
-
-
技能目标
-
- 能构建模块化的应用程序;
-
- 基本技术应用能力
- 能正确封装设计函数过程,并实现函数定义;
- 能正确调用函数完成数据处理;
- 能在函数中使用装饰器来实现特定应用;
- 能正确lambda表达式简化程序复杂度;
- 能正确使用内置标准函数与函数模块;
-
-
知识点目标
- 掌握函数的定义的调用
- 掌握函数的参数
- 掌握函数的返回值
- 掌握函数体与作用域
- 掌握递归函数
- 掌握函数对象
- 掌握函数装饰器
- 掌握lambda表达式
- 掌握顶层函数
- 掌握Python内置标准函数
- 掌握基本标准模块函数
函数的调用
在函数的编程方面,我们最容易用到的是经常调用函数。然后是根据需要封装定义函数,再调用。所以在这类我们先从函数调用运算符开始学习函数调用,然后再学习这些调用的函数是怎么实现的。
函数的调用语法
- 函数调用的语法
- Python提供了函数调用运算符号 ()
函数名(参数1,参数2,......) # 没有返回值
变量 = 数名(参数1,参数2,......) # 有返回值
- 规则1:
- 调用函数,参数必须是字面值,已经定义的变量,其他功能语句的返回结果。
a = 20
print('hello', a, a+40, input('输入数据'))
输入数据56
hello 20 60 56
- 规则2:
- 如果函数是在其他文件(模块),或者其他目录(包)的文件(模块)中,需要使用import 加载目录下的模块。
- 在使用函数的时候,根据import的方式,需要指定包路径与模块名。
import os
files = os.listdir()
for f in files:
print(f)
.DS_Store
.ipynb_checkpoints
a.txt
codes
L0_L1_L2_Regularization.ipynb
py.png
Python入门基础.ipynb
Python入门基础@数据与应用.ipynb
Python入门基础@数据与应用.pptx
Python入门基础@数据运算与流程控制.ipynb
Python入门基础@程序过程设计与函数.ipynb
Python入门基础@课程说明.ipynb
未命名.ipynb
未命名1.ipynb
课件@第01&02次
- 规则3:
- 如下情况,参数是可选的。
- 参数带默认值,比如:sep=','
- 可选的参数,如果没有传递的时候,就使用默认值。
- 除此以外的情况,参数都是必须的。
- 如下情况,参数是可选的。
print(1,2,3,4)
print(1,2,3,4,sep='。')
1 2 3 4
1。2。3。4
-
规则4:
- 文档中使用....表示的,参数可以多个,不受个数限制
-
规则5:
- 可以在调用函数的时候,指定参数名;
- 如下情况必须指定参数名:
- 文档中函数参数中出现.....或者*的后面的参数,必须指定参数名。
- 如下情况,一定不能指定参数名:
- 文档中函数参数中出现/的前面的参数,不能指定参数名。
print('hello', 'world', sep='...') # 只要sep使用,就必须使用参数名。
hello...world
-
规则6:
- 参数的顺序必须按照文档中显示的顺序传递。
-
规则7:
- 使用参数名的参数,可以不按照顺序使用。
- 没有使用参数名的参数必须按照顺序使用。
- 一旦某个参数使用了参数名,则后面参数都必须使用参数名。(不使用参数名的参数一定在前面。)
print('hello', 'word', flush=True, sep='...')
from socket import *
socket(AF_INET, SOCK_STREAM, proto=0, fileno=None)
socket(type=SOCK_STREAM, family=AF_INET, proto=0, fileno=None)
# socket(type=SOCK_STREAM, AF_INET, proto=0, fileno=None)
hello...word
- 使用help查看函数帮助
- 使用help函数直接查看帮助,从得到的信息中,重点关注如下几个信息:
- 函数的定义(函数名 + 函数参数 + 函数的返回类型);
-
函数的作用与返回值;
 在帮助查看函数返回值
在帮助查看函数返回值
- 使用help函数直接查看帮助,从得到的信息中,重点关注如下几个信息:
简单的函数调用
- 输入输出函数
- input函数
input(prompt=None, /)
Read a string from standard input. The trailing newline is stripped.
- 注意:
-
/ 前面的参数不允许使用,参数名
 函数的调用与调用运算发
函数的调用与调用运算发
-
result = input( '请输入数据:')
请输入数据:56
- print函数
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly fl
fd = open('a.txt', 'w')
print('输出值', 20, sep='|', end='。', file=fd, flush=True)
fd.close()
- 数学运算函数
- abs函数
- 返回一个数据的绝对值
abs(x, /)
Return the absolute value of the argument.
a = abs(-1)
print(a)
1
- divmod函数
- 求商与余数
divmod(x, y, /)
Return the tuple (x//y, x%y). Invariant: div*y + mod == x.
a = divmod(34.5, 7.5)
print(a)
(4.0, 4.5)
- round函数
- 四舍五入
round(...)
round(number[, ndigits]) -> number
a = round(45.7852135, 3)
print(a)
45.785
- min函数
- 求最小值
min(iterable, *[, default=obj, key=func]) -> value
min(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its smallest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
key= func模式是Python独有的编程模式,用函数来决定处理的数据。
a = min([1, 5, 3, 8, 9, 2], default=999)
print(a)
b = min([], default=999)
print(b)
dt = {
'赵德柱': 30,
'黄金花': 80,
'石破天': 70
}
def func(p):
return dt[p]
c = min(dt, default=999, key=func)
print(c)
1
999
赵德柱
- max函数
- 求最大值
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
dt = {
'赵德柱': 30,
'黄金花': 80,
'石破天': 70
}
def func(p):
return dt[p]
c = max(dt, default=999, key=func)
print(c, dt[c])
黄金花 80
- sum函数
- 求和
sum(iterable, start=0, /)
Return the sum of a 'start' value (default: 0) plus an iterable of numbers
a = sum([1, 5, 3, 8, 9, 2], 1000)
print(a)
1028
- pow函数
- 指数运算
pow(x, y, z=None, /)
Equivalent to x**y (with two arguments) or x**y % z (with three arguments)
a = pow(10, 2,)
print(a)
b = pow(10, 2, 10)
print(b)
100
0
- 类型判定函数
- id函数
- 返回变量的地址
id(obj, /)
Return the identity of an object.
a = 100
print(id(a))
print(id(100))
# 超过一个字节,就会单独创建空间,并拷贝数据
b =257
print(id(b))
print(id(257))
4405122080
4405122080
4442678512
4442678224
- isinstance函数
- 判定变量的类型
isinstance(obj, class_or_tuple, /)
Return whether an object is an instance of a class or of a subclass thereof.
a = 'hello'
#
r = isinstance(a, str)
print(r)
True
- 类型转换函数
- ord函数
- 返回unicode码
ord(c, /)
Return the Unicode code point for a one-character string.
print(ord('汉'))
27721
- hex函数
- 返回整数的16进制表示
hex(number, /)
Return the hexadecimal representation of an integer.
print(hex(111111111111111111))
0x18abef7846071c7
- bin函数
- 返回整数的二进制表示
bin(number, /)
Return the binary representation of an integer.
print(bin(888888888888))
0b1100111011110101111010000000111000111000
- ascii函数
- 返回字符的ASCII码
ascii(obj, /)
Return an ASCII-only representation of an object.
print(ascii('abcdef汉字'))
print(ascii(1245)) # 作为字符串处理
'abcdef\u6c49\u5b57'
1245
- chr函数
- 返回unicode的字符表示
chr(i, /)
Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff.
print(chr(0x6c49))
汉
- 列表有关函数
- len函数
- 返回数据结构的长度
len(obj, /)
Return the number of items in a container.
print(len([1,2,3,4,5]))
5
- any函数
- 判定序列中元素转换为bool后,是否有True。
any(iterable, /)
Return True if bool(x) is True for any x in the iterable.
If the iterable is empty, return False.
a = [1, 2, 3, 4, 5, 0]
print(any(a))
True
- all函数
- 判定序列中元素转换为bool后,是否都是True。
all(iterable, /)
Return True if bool(x) is True for all values x in the iterable.
If the iterable is empty, return True.
a = [1, 2, 3, 4, 5, 0]
print(all(a))
False
函数变量(函数命名)
- 把函数当成一个值使用,赋值给变量,变量也像函数一样使用。
- 函数当成值来使用,不能使用
()调用运算符号 - 函数可以赋值给变量的最大好处是:函数可以命名,与数据值可以命名一样。
- 函数变量与原来函数的使用完全一样的。
myfunc = print
myfunc(1,2,3,sep='...')
1...2...3
函数的定义与实现
- 语法
def 函数名(参数名,.....) :
语句
......
return 值
-
规则:
函数名遵循标识字的命名规则。
参数名遵循标识字的命名规则。
参数可以多个,使用逗号分隔。
没有参数的情况,就直接使用空的括号 def 函数名():
需要输出值,就是用return 值;
-
不需要输出值,下面三种情况都可以:
- return None
- return
- 省略return语句。
函数必须先定义才能调用。
-
规范:
- 函数名的命名规范:建议采用小写字母。
- 函数定义与其他代码之间,前后保留两个空行。
- 简单的函数实现与调用
- 使用函数表示一组代码,通过一个函数名,就可以执行到一组代码,这样代码可以反复调用,提高编码效率。
# print_hello() # 没有定义不能调用
def print_hello():
print('hello')
print_hello() # 上面已经定义,可以调用。
print_hello() # 上面已经定义,可以调用。
print(print_hello()) # 默认返回None
hello
hello
hello
None
- 简单函数参数实现与调用
- 使用参数的好处,就是调用者可以根据需要传递数据。
def print_hello(info):
print(info)
return
print_hello('hello')
print_hello('world')
print(print_hello('ok')) # 默认返回None
hello
world
ok
None
- 简单返回值实现与调用
def format_color(info):
val = F'\033[32;40m{info}\033[0m'
return val
print(format_color('Hello'))
print(format_color('World'))
�[32;40mHello�[0m
�[32;40mWorld�[0m
- 函数的文档注释
- 函数体中的第一行,都会作为文档注释使用。
- 编码规范:
- 尽管函数文档注释可以是任何字符串,但建议使用三个双引号来作为文档注释。
def doc_function():
"""
这是我的文档注释:
该函数是空的。
"""
pass # 空语句
help(doc_function)
Help on function doc_function in module __main__:
doc_function()
这是我的文档注释:
该函数是空的。
在python交互式编程终端查看的帮助:
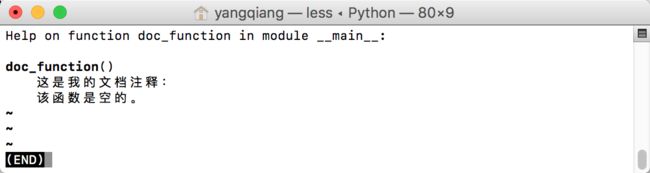 在终端交互式编程环境中查看帮助
在终端交互式编程环境中查看帮助
- 函数的参数类型说明
- 可以在函数定义时说明参数类型:
def 函数名(参数:类型,....)->返回值类型:
def add(a:int, b:int = 55) ->int:
return a+b
print(add(45))
100
- 函数的返回值类型说明
- 在Python3以后增加了函数的返回值类型说明,语法如下:
def 函数名(参数,...) ->类型:
语句
...
return 值
- 函数的返回类型不是强制的。不过我们申明了什么类型,还是按照类型返回!
def cal(p, q, r)->int:
"""
计算和与积,返回整数。
"""
v= (p+q)*r
return v
print(cal(2,3,4))
20
help(cal)
Help on function cal in module __main__:
cal(p, q, r) -> int
计算和与积,返回整数。
- 下面代码也是没有问题的,但是不规范。
def cal2(p, q, r)->int:
"""
计算和与积,返回整数。
"""
v= (p+q)*r
print(cal2(2,3,4))
None
函数的参数
Python中函数的参数与其他很多语言有差异,使用起来也非常方便。
- 参数名(keyword参数)
- Python中函数定义的参数名,在调用的时候,是可以使用的。
- 使用参数名的好处就是不用注意参数的顺序。
- 参数名在调用的时候没使用,语法如下:
参数名 = 参数值
def add(p1, p2):
return p1 + p2
# 使用参数名
v = add(p2=55, p1=45)
print(v)
100
- 可选参数
可选参数也称默认参数,是指在定义函数的时候,参数可以指定默认值,在调用的时候,参数可以不传递,不传递的参数使用默认值作为传递的参数值。
-
默认参数在定义函数的时候指定,语法如下:
参数名 = 默认值
注意:默认参数一定要放在非默认参数后面。换句话说就是,默认参数后面出现非默认参数是语法错误的。
# 定义默认参数
def add(p1=45, p2=55):
return p1 + p2
v = add()
print(v)
def add2(p1=45, p2):
return p1 + p2
File "", line 8
def add2(p1=45, p2):
^
SyntaxError: non-default argument follows default argument
- 变长参数
- Python提供两种变长参数:带参数名,不带参数名。
-
不带参数名的变长参数:
函数定义:
*args函数会使用:参数值1,....,参数值n
说明:参数使用元组类型传递。
-
带参数名的变长参数:
函数定义:
**kwargs函数使用:参数名1=参数值1,...., 参数名n=参数值n
说明:参数使用字典传递
-
- Python提供两种变长参数:带参数名,不带参数名。
def add(*arg):
return arg
# v = add(p1=1, p2=2,p3=3,p4=4,p5=5) # 不带参数名变长参数,不能使用参数名。
v = add(1, 2,3,4,5)
print(v)
(1, 2, 3, 4, 5)
def add(**arg):
return arg
# v = add(1, 2,3,4,5) # 带参数名变长参数,不使用参数名会导致错误。
v = add(p1=1, p2=2,p3=3,p4=4,p5=5)
print(v)
{'p1': 1, 'p2': 2, 'p3': 3, 'p4': 4, 'p5': 5}
- 变长参数*与**的顺序
-
* 与 **用来区分带参数名与不带参数名。
- * 不带参数名
- ** 带参数名
-
注意
- *参数只能出现在**参数前面
在函数体中,使用*与**用来表示参数的使用方式
-
# *变长参数只能用在**前面,否则语法错误。
def add(**kwargs, *args):
pass
File "", line 2
def add(**kwargs, *args):
^
SyntaxError: invalid syntax
- 变长参数只能一个,不能使用两个
def add(*args1, *args2):
pass
File "", line 1
def add(*args1, *args2):
^
SyntaxError: invalid syntax
- 变长参数中*与**的作用
- *的使用:
- *:在函数参数定义中使用,负责把函数调用的参数打包成元组。
- *:在函数体中使用,负责把列表解包成参数列表。
- **的使用:
- **:在函数参数定义中使用,负责把函数调用的参数打包成字典。(定义)
- **:在函数体中使用,负责把字典解包成参数列表。 (调用:作为普通参数传递给其他参数调用)
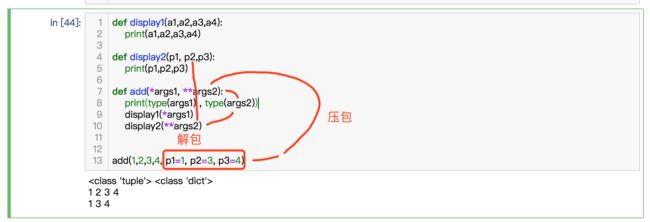 函数的参数的压包与解包
函数的参数的压包与解包
- *的使用:
def display1(a1,a2,a3,a4):
print(a1,a2,a3,a4)
def display2(p1, p2,p3):
print(p1,p2,p3)
def add(*args1, **args2):
print(type(args1) , type(args2))
display1(*args1)
display2(**args2)
add(1,2,3,4, p1=1, p2=3, p3=4)
1 2 3 4
1 3 4
- 变长参数的解包与压包的进一步应用理解
- 下面通过例子来进一步理解解包。
# 元组解包,把p元组,解包成参数格式。
def add(*args):
sum = 0
for v in args:
sum += v
return sum
p = (1,2,3,4)
v = add(*p)
print(v)
10
# 元组解包,把p元组,解包成参数格式。
def add(**kwargs):
print(kwargs)
p= {'p1':1, 'p2':3, 'p3':55}
add(**p) # 解包后,再压包(不能直接使用)
# add(p) # 这是错误的
add(p1=30,p2=50,p3=99,p4=88) # 压包
{'p1': 1, 'p2': 3, 'p3': 55}
{'p1': 30, 'p2': 50, 'p3': 99, 'p4': 88}
- 变长参数的使用
- 变长参数就可以按照元组与字典的的使用方式使用。
- 一般带参数名的变长参数,参数名都可以传递,但在函数中使用到的参数才有意义。
def add(*args):
sum = 0
for v in args:
sum += v
return sum
v = add(1, 2, 3, 4)
print(v)
v = add(1, 2, 3, 4, 5, 6, 7, 8)
print(v)
10
36
- keyword-only参数
- 也称为强制带命名(关键字参数):再使用参数的时候,必须使用参数名。
- Python提供了语法机制来约束。
- 语法: 使用特殊参数
*:
|- 在*后的参数,就是强制参数。
|- 在*前的参数,参数的使用根据前面讲解的规则。
def add(p1, p2=30, * ,p3, p4):
print(p1,p2,p3,p4)
# add(1,2,3,p4=4) 错误,3必须使用参数名(keyword)
add(1,2,p3=3,p4=4)
add(1,p2=2,p3=3,p4=4)
add(1,p3=3,p4=4)
add(p1=1,p3=3,p4=4)
# add(p1=1,2,p3=3,p4=4) # 错误,违背了命名参数后面必须是命名参数
1 2 3 4
1 2 3 4
1 30 3 4
1 30 3 4
- 参数匹配模型
由于Python中函数的参数引入很多参数语法规则,单个语法容易理解,但多个语法放在一起导致我们容易产生混乱,实际上Python函数的参数的语法规则主要还是断字、短句的范畴,只要能唯一确定调用形式即可,这就存在一套匹配规则,了解匹配规则,容易正确使用语法,在语法冲突的时候,容易知道错误在什么地方。
-
匹配规则是:
-
- 通过位置分配非关键字参数;
-
- 匹配关键字参数;
-
- 其他额外的非关键字参数分配到 * name 元组中
-
- 其他额外的关键字参数分配到 **name 字典中
-
- 用默认值分配给在头部未得到分配的参数
-
-
一个完整的函数参数定义例子
- * 与*args不能重复使用
- 变长参数不能匹配歧义。
def func(p1, p2, p3=4,p4=5, *,p7, p8,):
print(p1,p2,p3,p4,p5,p6,p7,p8)
# def func(p1, p2, p3=4,p4=5, *,p7, p8,*args): # 匹配歧义
# print(p1,p2,p3,p4,p5,p6
def func2(p1, p2, p3=4,p4=5, *args, p7, p8,):
print(p1,p2,p3,p4,p5,p6,p7,p8,args)
# def func3(p1, p2, p3=4,p4=5, *,p7, p8, **args): #匹配歧义
# print(p1,p2,p3,p4,p5,p6,p7,p8,args,kwargs)
- 使用参数输出数据
- 这个语法现象,最终是因为Python全部采用对象管理,参数都是传地址,不是传值。
- 整数,复数,小数,
a = [1,2,3,4]
def add (p1,p2):
p1[1] = 88
print(a)
add(a,40)
print(a)
[1, 2, 3, 4]
[1, 88, 3, 4]
a = 257
def add (p1,p2):
p1 = 400
print(a) # 因为20不可修改,这个对字符串,元组都是一样。
add(a,40)
print(a)
257
257
- 使用函数作为参数
- 函数参数可以直接使用函数名
- 函数参数也可以使用函数变量
def mydisplay(val, func):
func(F'\033[32m{val}!')
mydisplay('helll', print)
myf = print
mydisplay('helll', myf)
�[32mhelll!
�[32mhelll!
函数的返回值
使用return返回数据值
-
没有return的默认返回值
- 函数没有return默认返回None。表示没有返回值。也可以使用return返回None。
-
返回数据结构(包含将要学习的对象)
- Python函数可以返回任意类型,包含数据结构。不过对元组,列表,字典,集合的返回与使用,提供一些独特的使用方式。 在某些场合下元组的括号可以省略。
# 返回元组
def mymod(p1, p2):
return (p1, p2)
print(mymod(100,200))
# 返回列表
def mymod(p1, p2):
return [p1, p2]
print(mymod(100,200))
# 返回集合
def mymod(p1, p2):
return {p1, p2}
print(mymod(100,200))
# 返回字典
def mymod(p1, p2):
return {'参数1':p1, '参数2':p2}
print(mymod(100,200))
(100, 200)
[100, 200]
{200, 100}
{'参数1': 100, '参数2': 200}
- 对返回数据结构的处理
# 返回元组
def mymod_tuple(p1, p2):
return (p1, p2)
# 返回列表
def mymod_list(p1, p2):
return [p1, p2]
# 返回集合
def mymod_set(p1, p2):
return {p1, p2}
# 返回字典
def mymod_dict(p1, p2):
return {'参数1':p1, '参数2':p2}
(r1, r2)= mymod_tuple(100,200)
print(r1,r2)
[r1, r2]= mymod_tuple(100,200)
print(r1,r2)
# {r1, r2}= mymod_tuple(100,200)
r1, r2= mymod_tuple(100,200) # 省略
print(r1,r2)
(r1, r2)= mymod_list(100,200)
print(r1,r2)
[r1, r2]= mymod_list(100,200)
print(r1,r2)
# {r1, r2}= mymod_list(100,200)
r1, r2= mymod_list(100,200) # 省略
print(r1,r2)
(r1, r2)= mymod_set(100,200)
print(r1,r2)
[r1, r2]= mymod_set(100,200)
print(r1,r2)
# {r1, r2} = mymod_set(100,200)
r1, r2= mymod_set(100,200) # 省略
print(r1,r2)
(r1, r2)= mymod_dict(100,200)
print(r1,r2)
[r1, r2]= mymod_dict(100,200)
print(r1,r2)
# {r1, r2} = mymod_dict(100,200)
r1, r2= mymod_dict(100,200) # 省略
print(r1,r2)
r= mymod_dict(100,200) # 省略
print(r)
100 200
100 200
100 200
100 200
100 200
100 200
200 100
200 100
200 100
参数1 参数2
参数1 参数2
参数1 参数2
{'参数1': 100, '参数2': 200}
r1, _= mymod_dict(100,200) # 省略
print(r1, _) # 一般会使用_占位。
参数1 参数2
返回函数与嵌套函数
- 直接返回一个函数
- 既然函数可以赋值给变量,所以返回函数,使用变量接受返回值,也可以直接使用。
def myfunc():
return print;
re = myfunc()
re('hello','world',sep='...')
hello...world
- 函数嵌套
- 在Python中函数是可以嵌套的。就是在函数中海可以定义函数。
- 函数中嵌套的函数也作为返回值。
def outter_func():
def inner_func():
print('inner function')
return inner_func;
f = outter_func()
f()
inner function
yeild与生成器Generator
- python提供了一个yield语句,用来对数据序列的返回操作。
- 语法:
yield 数据- yield必须在函数中使用
val = yield 2 # SyntaxError: 'yield' outside function
- yield的作用
- 自动返回一个生成器对象
- 这里不解释什么是生成器,但生成器可以创建一个数据序列,可以转换为list类型的数据。
- 但是yield语句不返回数据
def fc(p):
x = yield p
print(x) # x位None
rv = fc(100)
print(type(rv) ,rv)
print(list(rv), tuple(rv), set(rv))
None
[100] () set()
def fc(p):
yield p
yield p+1
yield p+2
rv = fc(100)
lt = list(rv)
print(lt)
[100, 101, 102]
- 使用yield产生数据序列
def gen_fc():
for i in range(5):
yield I
rv = list(gen_fc())
print(rv)
print(type(gen_fc())) # 返回一个独特的类型generator
[0, 1, 2, 3, 4]
- 生成器(generator)函数
- 使用yield语句的函数,就是python中一种特殊的函数:生成器函数。(只要调用依次yield语句,该函数就是生成器函数。)
- 调用生成器函数的时候,并没有执行代码,只是创建了一个生成器(可以理解为代码容器)。
- 只有访问生成器的时候,代码才得到执行。访问生成器使用生成器对象的__next__函数与send函数。
- 每次调用,执行到yield就暂停,直到下次调用。
def gen_fc():
for i in range(5):
print('before')
yield I
print(i)
if i == 4:
return 'hello' # 抛出StopIteration信号。
rv = gen_fc()
# 调用生成器容器中代码,并得到yield的值
r = rv.__next__()
r = rv.__next__()
r = rv.__next__()
r = rv.__next__()
r = rv.__next__()
print('输出', r)
r = rv.__next__()
before
0
before
1
before
2
before
3
before
输出 4
4
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
in ()
15 r = rv.__next__()
16 print('输出', r)
---> 17 r = rv.__next__()
StopIteration: hello
- Generator类说明
- Generator在typing模块中定义。
class Generator(collections.abc.Generator, Iterator)
| Abstract base class for generic types.
|
| A generic type is typically declared by inheriting from
| this class parameterized with one or more type variables.
| For example, a generic mapping type might be defined as::
- Generator的操作
| __next__(self)
| Return the next item from the generator.
| When exhausted, raise StopIteration.
|
| close(self)
| Raise GeneratorExit inside generator.
|
| send(self, value)
| Send a value into the generator.
| Return next yielded value or raise StopIteration.
|
| throw(self, typ, val=None, tb=None)
| Raise an exception in the generator.
| Return next yielded value or raise StopIteration.
- 生成器操作
- send操作
# send从上一次yield结束位置开始
def gen_fc():
for i in range(5):
print('before')
yield I
print(i)
if i == 4:
return 'hello' # 抛出StopIteration信号。
rv = gen_fc()
# rv.send(0) # TypeError: can't send non-None value to a just-started generator
rv.send(None)
before
0
- 生成器send与__next__的区别
- send比起__next__的差异就是可以传递一个值给yield函数,并使得yield语句返回一个值,默认yield函数返回None。
- 因为yield第一次执行暂停,所以send第一次传递的值没有意义,所以send第一次调用只能传递None值。
- 当第二次调用的时候,上一次yield开始执行,并返回这次send传递的值。(或者先执行next再执行send一样的效果)
# send与next的区别在于,send在执行的时候,可以传递一个值给yield语句用于返回
def gen_fc():
for i in range(5):
print('before')
re = yield I
print(F'{re}:{I}')
if i == 4:
return 'hello' # 抛出StopIteration信号。
rv = gen_fc()
rv.send(None) # yield后执行不到
print('第01次------')
rv.send(888)
print('第02次------')
rv.send(999)
print('第03次------')
rv.send(111)
print('第04次------')
rv.send(222)
print('第05次------')
before
第01次------
888:0
before
第02次------
999:1
before
第03次------
111:2
before
第04次------
222:3
before
第05次------
- 生成器这种工作方式属于协程的技术范畴
- 所谓协程:就是执行过程中,产生中断(暂停),并返回调用处执行。这个与线程是有区别的,协程系统层面来讲,属于进程或者线程通信的范畴。
-
再系统底层有一个函数就是yield,用来暂时放弃当前分配的CPU执行机会。
 系统中的yield函数
系统中的yield函数
生成器表达式
- 语法:
( 表达式 for 标识字 in 可迭代数据 if 条件 ) - 可以把生成器表达式转换为列表:
[ 表达式 for 标识字 in 可迭代数据 if 条件 ] - 其中for与if 可以嵌套(每个for可以拥有一个if用来过滤数据,不支持else)。
- 生成器表达式例子
(x * 2 for x in range(10))
at 0x108d748e0>
[x * 2 for x in range(10)]
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
(print(x) for x in range(10))
at 0x108d747d8>
[print(x, end='') for x in range(10)]
0123456789
[None, None, None, None, None, None, None, None, None, None]
- 生成器表达式if使用的例子(不要在if中使用else,没有这个语法,但可以在前面表达式中使用)
[x * 2 for x in range(10) if x%2==0 ]
[0, 4, 8, 12, 16]
[x * 2 if x%2==0 else x*3 for x in range(10) ]
[0, 3, 4, 9, 8, 15, 12, 21, 16, 27]
- 生成器循环嵌套的例子
[F'{x} + {y}={x + y}' for x in range(5) for y in range(x)]
['1 + 0=1',
'2 + 0=2',
'2 + 1=3',
'3 + 0=3',
'3 + 1=4',
'3 + 2=5',
'4 + 0=4',
'4 + 1=5',
'4 + 2=6',
'4 + 3=7']
函数体与作用域
函数是独立的块,在Python中,不同的块之间,变量的访问是有约束的。这个部分就来说明函数块与外部的变量的访问规则。
变量的作用域
因为函数中也可以定义变量,并且参数还传递变量,在函数外部还可以有变量。这些变量名是否可以相同?他们在什么时候释放?(比如函数调用结束后,其中定义的变量释放么?函数测餐食是否释放?)
- 全局变量与局部变量
-
临时变量(也称局部变量):
- 函数中定义的变量,在函数调用完毕是自动释放的,函数的参数也是自动释放的。这种随着调用环境结束二释放的变量,我们称为临时变量(局部变量)
-
全局变量
- 程序结束才释放的变量,我们称为全局变量。(Python中存在顶层函数,其中定义的变量都是全局变量)
-
全局变量与局部变量使用规则:
- 在函数中,可以使用全局变量
- 在全局中,不能使用局部变量
-
def func():
la = 30 # 局部变量
print('函数局部:',gb)
gb = 40 # 全局变量
func()
print('全局:',la) # la不能被使用。
函数局部: 40
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
4 gb = 40 # 全局变量
5 func()
----> 6 print('全局:',la)
NameError: name 'la' is not defined
- 全局变量与局部变量的命名冲突
- 全局变量与局部变量在不同的运行环境中,可以有相同的变量名;
- 规则:变量名相同,使用的时候遵循一个规则:局部优先。
- 规则:没有冲突,变量不会产生访问歧义,直接使用全局变量,但全局中不能使用局部变量;
- 为了区分变量是全局还是局部变量,python引入了一个关键字来处理。
- global
- 全局变量申明的语法:
global 变量名1, 变量名2,......- 就算没有在全局定义全局变量,在函数内部使用global声明的变量都是全局变量。
- 全局变量与局部变量在不同的运行环境中,可以有相同的变量名;
def func():
global glb,glc, gld
gla = 30 # 局部变量
glb = 888 # 全局变量
glc = 999 # 全局变量
gld = 777
print('函数局部:',gla, glb, glc,gld) # 局部优先
gla = 40 # 全局变量
glb = 50 # 全局变量
glc = 50 # 全局变量
func()
print('全局:',gla, glb, glc,gld) # la不能被使用。
函数局部: 30 888 999 777
全局: 40 888 999 777
- 函数嵌套中的变量作用域
- 函数可以嵌套,导致变量的作用域更加复杂。但遵循一个总得规则:
- 内层可以访问外层,外层不能访问内层。
- 函数可以嵌套,导致变量的作用域更加复杂。但遵循一个总得规则:
def func_1():
a1 = 1
def func_2():
a2 = 2
def func_3():
a3 = 3
print(a0, a1, a2, a3)
func_3()
func_2()
# print(a2) # 外层不能访问内层:NameError: name 'a2' is not defined
a0 = 0
func_1()
0 1 2 3
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
13 a0 = 0
14
---> 15 func_1()
in func_1()
10 func_3()
11 func_2()
---> 12 print(a2)
13 a0 = 0
14
NameError: name 'a2' is not defined
- 内外层的变量名冲突
- 可以使用nonlocal来解决内外层的变量名冲突与作用域问题
- 语法:
nonlocal 外层变量, 外层变量, ...... - 规则:
- nonlocal与global的使用差别是:nonlocal 绑定的变量必须在外层申明过,global的不需要申明。
- nonlocal不能绑定全局变量
def func_1():
a1 = 11
def func_2():
nonlocal a1
# nonlocal a0 # SyntaxError: no binding for nonlocal 'a0' found
a1 = 22
def func_3():
a3 = 33
print(a0, a1, a3)
func_3()
func_2()
print(a1) # 外层不能访问内层:NameError: name 'a2' is not defined
a0 = 0
func_1()
0 22 33
22
闭包
-
闭包这个概念也与作用域有关,上面变量作用域都是函数调用完毕变量就被释放,但这种情况存在一种问题。
- 当函数返回函数,就存在调用函数结束,返回的嵌套函数还在运行,这个函数的外层环境已经被释放,如果其中引用的外层变量就不存在,这种情况的解决,在Python中引入了闭包的概念来解决。
-
闭包
- 闭包 = 内部嵌套函数 + 外部引用环境
- 闭包:内部嵌套函数 + 外部引用环境打包成为一个新的整体,可以解决了函数编程中的嵌套所引发的问题;
- 闭包 = 内部嵌套函数 + 外部引用环境
def out_func():
a = 40
def in_func():
nonlocal a # 不使用这个语句,a赋值当成当前局部变量处理。
a = a + 1
print(a)
return in_func
in_f = out_func() # 这儿调用完毕,a应该释放,但因为存在函数返回,会把in_func函数与out_func引用环境一起打包(这是内存管理的范畴)。
in_f() # 该函数引用的外层环境,因为闭包而存在。
41
函数递归
在Python中支持函数调用函数本身的语法(实际基本上所有语言都支持),这种语法现象就是递归。
有的时候使用好递归,可以很方便的解决某些问题。
-
函数调用函数,逻辑上是无穷递归调用的,所以使用递归的时候处理好两个问题:
- 递归结束
- 递归的返回值(这个可以用来产生二叉树)
函数调用函数本身的语法规则与函数调用是一样的。
-
递归的使用技巧
- 使用条件结束递归调用。
- 选择递归的思路:使用初中的数列通项式。
- 使用递归显示某个目录
import os
def list_dir(d, depth):
fd = os.path.basename(d)
# print(' ' * depth, fd, sep='|-')
if os.path.isdir(d):
files = os.listdir(d)
for file in files:
file_path = os.path.join(d, file)
list_dir(file_path, depth + 1)
list_dir('.', 1)
- 使用递归生成目录树
import os
def list_dir(d, depth):
fd = os.path.basename(d)
# print('\t' * depth, fd, sep='|-')
v = []
if os.path.isdir(d):
files = os.listdir(d)
for file in files:
file_path = os.path.join(d, file)
r = list_dir(file_path, depth + 1)
v.append(r)
return {d: v}
re = list_dir('.', 1)
# print(re)
函数对象
函数对象的类型
- 我们在前面看见,函数可以作为函数值赋值给变量,这个函数实际是作为函数对象而存在。既然函数可以作为对象值赋值给i变量,函数变量就与函数一样,具备如下变量与函数共有的操作:
- 函数变量像函数一样调用;
- 函数变量,可以作为变量使用,在函数参数与返回值中使用;
- 函数可以使用在变量使用的任何场景;
- 作为函数对象,函数可以想对象一样操作,对象具备如下操作:
- 类型:type
- 地址:id
def my_func(a, b)->int:
return a + b
print(my_func) # 作为变量值使用
print(id(my_func)) # 地址
print(type(my_func)) # 类型
4519963776
- builtins.function的帮助
- 因为fuction动态构建,使用help(builtins.function)无法查看帮助。只有动态返回的类型才能查看。
- help(type(my_func)) 能使用这种方式查看到帮助,
-
builtins.function的源代码截图如下:
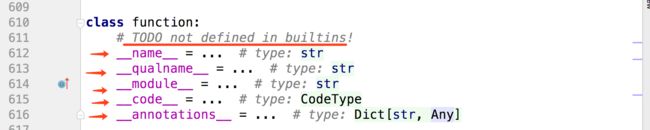 函数对象源代码截图
函数对象源代码截图
- 因为fuction动态构建,使用help(builtins.function)无法查看帮助。只有动态返回的类型才能查看。
# 使用代码获取帮助
help(function)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
1 # 使用代码获取帮助
----> 2 help(function)
3 a =function()
NameError: name 'function' is not defined
# 不能直接使用function类,函数对象是根据代码而创建的对象,类型时function类型,这个类型在builtins模块中定义。
a =function()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
1 # 不能直接使用function类,函数对象是根据代码而创建的对象,类型时function类型,这个类型在builtins模块中定义。
----> 2 a =function()
NameError: name 'function' is not defined
# 通过定义的函数才能获取这个类型与对象
def my_func(a, b)->int:
return a + b
print(type(my_func))
# 获取类型的帮助
help(type(my_func))
Help on class function in module builtins:
class function(object)
| function(code, globals[, name[, argdefs[, closure]]])
|
| Create a function object from a code object and a dictionary.
| The optional name string overrides the name from the code object.
| The optional argdefs tuple specifies the default argument values.
| The optional closure tuple supplies the bindings for free variables.
|
| Methods defined here:
|
| __call__(self, /, *args, **kwargs)
| Call self as a function.
|
| __get__(self, instance, owner, /)
| Return an attribute of instance, which is of type owner.
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| __repr__(self, /)
| Return repr(self).
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __annotations__
|
| __closure__
|
| __code__
|
| __defaults__
|
| __dict__
|
| __globals__
|
| __kwdefaults__
使用函数对象
- 函数的属性
import builtins
def my_func(a: int, b: int=3, *, c: int = 40, d: int) -> int:
"""
注释文档
"""
re = 30
return a + b
# 使用函数对象
print(my_func.__closure__) # 闭包
print(my_func.__annotations__) # 参数与返回值说明
print(my_func.__code__) # 代码
print(my_func.__defaults__) # 缺省值
print(my_func.__dict__) # 字典(用来存放属性列表,函数没有)
# print(my_func.__globals__) # 全局
print(my_func.__kwdefaults__) # keyword缺省
print('------')
print(my_func.__name__) # 函数名
print(my_func.__doc__) # 函数的注释文档
print(my_func.__module__) # 函数所在模块
print(my_func.__sizeof__()) # 函数占用的内存大小
print(my_func.__str__()) # 代表函数的字符串
print(my_func.__class__) # 函数的类型
print(my_func.__dir__()) # 函数的目录(成员)
r = my_func.__call__(1, 2, c=3, d=4) # 使用__call__调用函数。
print(':', r) # 调用方的返回值
None
{'a': , 'b': , 'c': , 'd': , 'return': }
", line 4>
(3,)
{}
{'c': 40}
------
my_func
注释文档
__main__
112
['__repr__', '__call__', '__get__', '__new__', '__closure__', '__doc__', '__globals__', '__module__', '__code__', '__defaults__', '__kwdefaults__', '__annotations__', '__dict__', '__name__', '__qualname__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__init__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__']
: 3
函数对象中的闭包属性
- 函数闭包产生的条件:
- 内部函数
- 作为返回值返回到外部
- 在外部调用。
- 只有内部函数使用了外部的变量,才会生成闭包
- 闭包是一个元组(因为嵌套的层数,可能是多个)
# 函数闭包产生的条件:内部函数,作为返回值返回到外部,在外部调用。
def out_f():
a = 45
def in_f():
print(a) # 只有使用了外部的变量,才会生成闭包
# pass
print('函数的闭包:', in_f.__closure__)
return in_f
ff = out_f()
ff()
print('函数的闭包:', ff.__closure__)
print(type(ff.__closure__))
print(type(ff.__closure__[0]))
函数的闭包: (,)
45
函数的闭包: (,)
| | - 闭包的类型与帮助
# 获取cell的帮助(这个类不能直接查看帮助,只能依托具体的对象查看帮助)
help(type(ff.__closure__[0]))
Help on class cell in module builtins:
class cell(object)
| Methods defined here:
|
| __eq__(self, value, /)
| Return self==value.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __gt__(self, value, /)
| Return self>value.
|
| __le__(self, value, /)
| Return self<=value.
|
| __lt__(self, value, /)
| Return self- 闭包的内容
print(ff.__closure__[0].cell_contents)
45
函数的属性
- 在函数中定义不了属性,但可以通过函数对象定义属性
def my_func(a: int, b: int=3, *, c: int = 40, d: int) -> int:
"""
注释文档
"""
re = 30
return a + b
my_func.f_a = 100
my_func.f_b = 600
print(my_func.__dict__)
{'f_a': 100, 'f_b': 600}
- 说明:
- 一般函数属性没有什么用处,一般用于非常专用(专业的语法解析器什么的应用),或者仅仅是传递一个数据。
函数装饰器
装饰器的使用背景
装饰器语法提出的背景是回调(从语法上就是使用函数作为参数传递调用),Python提供了一种更加简洁的回调语法:装饰器(一种软件设计模式的称呼:装饰器模式)。
下面是一个回调的经典例子(这种耦合设计,与Qt的信号与槽非常类似)
def txt_log(info):
print('信息日志:',info)
def net_log(info):
print('网络日志:',info)
def biz(lg):
lg('日志记录')
print('业务处理')
lg('日志记录')
biz(txt_log)
biz(net_log)
信息日志: 日志记录
业务处理
信息日志: 日志记录
网络日志: 日志记录
业务处理
网络日志: 日志记录
装饰器的内置编程模式
- 上面是回调来自传统的语法调用,这个编程模式增加了函数之间的耦合程度(因为参数属于函数的一部分),尽管Python宽松的参数类型检查,降低了这种耦合,不像其他语言通过接口等诸多语法来降低这种耦合。但是Python还是提供了一种语法来提供更加便捷的调用方式。
- 装饰器就是一种编程模式的语法级实现(给已知函数添加新的功能)。
- 利用python的两个语法:
- 函数参数可以传递函数;
- 函数可以返回函数;
- 确定被装饰的函数,编写一个装饰函数;装饰函数的逻辑如下:
- 装饰函数提供一个参数,用来传递被装饰的函数;
- 实现一个内部函数,内部函数,在内部函数中调用被装饰的函数,再调用被装饰的函数的实现中,可以添加额外的功能。
- 把内部函数作为装饰函数的返回值。
- 当调用返回的函数的时候,这个函数已经对传递的函数提供了额外的功能。
- 利用python的两个语法:
# 1. 被装饰的函数
def 被装饰者():
print('被装饰功能实现')
# 2. 装饰函数:用来对被装饰者增加功能(就是装饰)
def 装饰器(被装饰者参数):
# 3. 装饰实现:使用内部函数完整多被装饰者的装饰
def 装饰实现():
print('额外增加的功能!')
被装饰者参数() # 调用被装饰者
print('其他额外功能增加')
return 装饰实现 # 返回被装饰后的函数
# 4. 被装饰后的函数:调用装饰器得到被装饰后的函数
被装饰以后的函数 = 装饰器(被装饰者)
# 5. 被装饰函数调用:调用返回的函数,得到被装饰的功能
被装饰以后的函数()
额外增加的功能!
被装饰功能实现
其他额外功能增加
装饰器语法
- 装饰器语法
- 装饰器语法自动实现装饰过程。
- 被装饰装饰过的函数就不是原来的函数了,是增加了功能的新的函数。
@ 装饰器
def 被装饰函数:
函数实现
...
# 1. 装饰器
def 装饰器_函数(被装饰者传递):
# 使用内部函数完整多被装饰者的装饰
def 装饰内部实现():
print('额外增加的功能!')
被装饰者传递() # 调用被装饰者
print('其他额外功能增加')
return 装饰内部实现 # 返回被装饰后的函数
# 2 使用装饰器语法使用装饰器
@装饰器_函数
def 被装饰者_函数():
print('被装饰功能实现')
# 被装饰者调用
被装饰者_函数()
额外增加的功能!
被装饰功能实现
其他额外功能增加
被装饰者的参数
- 明白了装饰器的原理与机制,怎么实现装饰器传递参数就容易理解,遵循调用过程传递参数。
- 下面使用一个参数来举例说明( 其他方式的参数以此类推 ):
# 1. 装饰器
def 装饰器_函数(被装饰者传递):
# 使用内部函数完整多被装饰者的装饰
def 装饰内部实现(参数):
print('额外增加的功能!')
被装饰者传递(参数) # 调用被装饰者
print('其他额外功能增加')
return 装饰内部实现 # 返回被装饰后的函数
# 2 使用装饰器语法使用装饰器
@装饰器_函数
def 被装饰者_函数(参数1):
print('被装饰功能实现', 参数1)
# 被装饰者调用
被装饰者_函数(20)
额外增加的功能!
被装饰功能实现 20
其他额外功能增加
装饰器的参数
- 既然装饰器作为函数,也应该存在参数;
- 装饰器的参数实现,采用的还是装饰器的思维,在原来的装饰器上面再装饰一层函数。
# 1. 装饰器
def 装饰器参数(装饰器参数): # 装饰器参数传递
def 装饰器_函数(被装饰者传递): # 装饰器函数,负责传递被装饰的函数
# 使用内部函数完整多被装饰者的装饰
def 装饰内部实现(参数): # 装饰实现函数,负责传递被装饰函数的参数
print('装饰器参数:',装饰器参数)
print('额外增加的功能!')
被装饰者传递(参数) # 调用被装饰者
print('其他额外功能增加')
return 装饰内部实现 # 返回被装饰后的函数
return 装饰器_函数
# 2 使用装饰器语法使用装饰器
@装饰器参数('this is a 装饰器参数')
def 被装饰者_函数(参数1):
print('被装饰功能实现', 参数1)
# 被装饰者调用
被装饰者_函数(20)
装饰器参数: this is a 装饰器参数
额外增加的功能!
被装饰功能实现 20
其他额外功能增加
多重装饰
-
一般一个装饰器,肯定可以装饰多个函数,在Python语法中,一个函数也可以被多个装饰器装饰。
- 多个装饰器装饰本质是嵌套装饰
-
语法:
- 每个装饰器单独一个语句,修饰最近的函数,包括装饰器也是函数,也可以被装饰。
@ 装饰器1
@ 装饰器2
def 被装饰函数(参数):
pass
```
```python
def log_decorator(param_log):
def log_wrapper(func):
def decorator_impl(param_func):
print('装饰器参数:', param_log)
print('开始装饰')
r = func(param_func) # 被装饰函数调用(被装饰函数参数)
print('装饰结束')
return F'被装饰函数返回{r}' # 装饰器函数的返回值
return decorator_impl
return log_wrapper
def net_decorator(param_log):
def net_wrapper(func):
def decorator_impl(param_func):
print('装饰器参数:', param_log)
print('开始装饰')
r = func(param_func) # 被装饰函数调用(被装饰函数参数)
print('装饰结束')
return F'被装饰函数返回{r}' # 装饰器函数的返回值
return decorator_impl
return net_wrapper
@ net_decorator(666)
@ log_decorator(999)
def biz_db(p):
print(F'数据处理{p}')
return 111
biz_db(888)
装饰器参数: 666
开始装饰
装饰器参数: 999
开始装饰
数据处理888
装饰结束
装饰结束
'被装饰函数返回被装饰函数返回111'
lambda表达式
-
lambda表达式(表达式):本质是解决函数的字面值的问题,因为通常的数据有两种形态:
- 字面值(也称匿名变量),比如:整数20
- 变量,比如:a = 20
-
函数因为其特殊性,在表示的时候,只能使用变量表示,比如函数作为参数只能传函数名,不能传函数代码。
- 为了能传递函数,Python语言引入了lambda表达式。
- lambda表达式严格意义上讲是一个自定义的运算表达式,但最终返回的实际上是一个函数对象(所以也称匿名函数)。
lambda表达式语法:
lambda 参数列表: 表达式
- 等价于:
def ( 参数列表):
return 表达式
- lambda表达式没有提供参数与返回值的类型说明。
- lambda本质是函数,使用方式与函数一样,只是比函数方便多了,可以在传函数参数的时候,直接使用lambda表达式,代码会非常简洁。
la = lambda x, y: x+y
print(la(45, 55))
100
# 定义完毕直接调用
r = (lambda x, y: x+y)(45,55)
print(r)
100
# 类型
print(type( lambda x, y: x+y ))
main函数
当我们写第一行语句的时候,实际代码也是通过函数运行的,这个函数就是main函数;
-
当模块作为import,代码的name是模块名;只有当作为初始执行,实际是调用main来执行,name返回的是main 。
- 不管使用
python 文件名还是python -m 模块名执行,初始执行都从main模块开始执行。
- 不管使用
判定name是否等于main可以判定一个模块是引入,还是执行开始执行的。
print(__name__)
__main__
Python内置标准函数
- python提供了很多内置函数,前面已经调用过一些,还有一些函数位:
| abs() | dict() | help() | min() | setattr() |
| all() | dir() | hex() | next() | slice() |
| any() | divmod() | id() | object() | sorted() |
| ascii() | enumerate() | input() | oct() | staticmethod() |
| bin() | eval() | int() | open() | str() |
| bool() | exec() | isinstance() | ord() | sum() |
| bytearray() | filter() | issubclass() | pow() | super() |
| bytes() | float() | iter() | print() | tuple() |
| callable() | format() | len() | property() | type() |
| chr() | frozenset() | list() | range() | vars() |
| classmethod() | getattr() | locals() | repr() | zip() |
| compile() | globals() | map() | reversed() | __import__() |
| complex() | hasattr() | max() | round() | |
| delattr() | hash() | memoryview() | set() |
- sorted函数
- 序列数据排序
sorted(iterable, /, *, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
lt = [1, 5, 3, 4, 2]
sorted_lt = sorted(lt)
print(sorted_lt)
# key是一个回调函数,用来处理复杂数据项的处理
dt = {
'Jack': 89,
'Rose': 78,
'Tom': 99
}
# 使用ley处理复杂数据
sorted_dt = sorted(dt, key= lambda x : dt[x], reverse=True)
print(sorted_dt)
[1, 2, 3, 4, 5]
['Tom', 'Jack', 'Rose']
- reversed
- 对序列数据做逆操作
class reversed(object)
| reversed(sequence) -> reverse iterator over values of the sequence
|
| Return a reverse iterator
lt = [1, 5, 3, 4, 2]
reversed_lt = reversed(lt)
# 返回逆序可迭代对象
print(reversed_lt)
print(list(reversed_lt)) # 返回的不是列表,是迭代器,可以直接转换为list类型使用。
[2, 4, 3, 5, 1]
- filter函数
- 过滤数据
class filter(object)
| filter(function or None, iterable) --> filter object
|
| Return an iterator yielding those items of iterable for which function(item)
| is true. If function is None, return the items that are true.
lt = [1, 5, 3, 4, 2]
filter_lt = filter(None, lt)
print(list(filter_lt))
# 使用lambda函数,过滤奇数
filter_lt = filter(lambda x : True if x % 2 ==0 else False, lt)
print(filter_lt) # filter对象也是迭代器。
print(list(filter_lt))
[1, 5, 3, 4, 2]
[4, 2]
- map函数
- 对数据做对应映射处理
class map(object)
| map(func, *iterables) --> map object
|
| Make an iterator that computes the function using arguments from
| each of the iterables. Stops when the shortest iterable is exhausted.
# 技术每个数的平方,使用生成器表达式也可以
lt1 = [1, 5, 3, 4, 2]
# 使用ley处理复杂数据
map_lt = map(lambda x : x**2, lt1)
print(list(map_lt))
lt2 = [6, 3, 2, 1, 4]
map_lt = map(lambda x, y : x * y, lt1,lt2) # 如果有单个列表,则处理函数就有三个参数
print(map_lt) # map对象
print(list(map_lt))
[1, 25, 9, 16, 4]
- zip函数
- 合并数据位元组。
class zip(object)
| zip(iter1 [,iter2 [...]]) --> zip object
|
| Return a zip object whose .__next__() method returns a tuple where
| the i-th element comes from the i-th iterable argument. The .__next__()
| method continues until the shortest iterable in the argument sequence
| is exhausted and then it raises StopIteration.
lt1 = [1, 5, 3, 4, 2, 88]
lt2 = [6, 3, 2, 1, 4]
# 返回长度,取最短的长度
zip_lt = zip(lt1, lt2)
print(zip_lt) # zip对象
print(list(zip_lt))
[(1, 6), (5, 3), (3, 2), (4, 1), (2, 4)]
- format函数
- 格式化字符串
format(value, format_spec='', /)
Return value.__format__(format_spec)
format_spec defaults to the empty string.
See the Format Specification Mini-Language section of help('FORMATTING') for
details.
- 格式化规范如下:
format_spec ::= [[fill]align][sign][#][0][width][grouping_option][.precision][type]
fill ::=
align ::= "<" | ">" | "=" | "^"
sign ::= "+" | "-" | " "
width ::= digit+
grouping_option ::= "_" | ","
precision ::= digit+
type ::= "b" | "c" | "d" | "e" | "E" | "f" | "F" | "g" | "G" | "n" | "o" | "s" | "x" | "X" | "%"
a = 20
f_a = format(a, '>+5.2e')
print(f_a)
+2.00e+01
- open函数
- 打开一个文件位文件对象流。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Open file and return a stream. Raise IOError upon failure.
# 在python中打开的文件也是一个可迭代的对象
fd = open('recurit.py')
for line in fd:
print(line)
fd.close()
import os
def list_dir(d, depth):
fd = os.path.basename(d)
print(' ' * depth, fd, sep='|-')
v = []
if os.path.isdir(d):
files = os.listdir(d)
for file in files:
file_path = os.path.join(d, file)
r = list_dir(file_path, depth + 1)
v.append(r)
return {d: v}
re = list_dir('.', 1)
print(re)
# 在python中打开的文件也是一个可迭代的对象
fd = open('recurit.py')
lines = list(fd)
print(lines)
fd.close()
['import os\n', '\n', '\n', 'def list_dir(d, depth):\n', ' fd = os.path.basename(d)\n', " print(' ' * depth, fd, sep='|-')\n", ' v = []\n', ' if os.path.isdir(d):\n', ' files = os.listdir(d)\n', ' for file in files:\n', ' file_path = os.path.join(d, file)\n', ' r = list_dir(file_path, depth + 1)\n', ' v.append(r)\n', ' return {d: v}\n', '\n', '\n', "re = list_dir('.', 1)\n", 'print(re)\n', '\n']
- vars,globals与locals函数
- 返回当前作用域的全局变量与局部变量
- 如果vars不指定参数,vars与locals是一样的效果。
- 如果使用参数,等于调用指定对象的dict
vars(...)
vars([object]) -> dictionary
Without arguments, equivalent to locals().
With an argument, equivalent to object.__dict__.
globals()
Return the dictionary containing the current scope's global variables.
locals()
Return a dictionary containing the current scope's local variables.
g = globals()
l = locals()
# print(g)
# print(l)
def ff():
l_a = 89
print(locals())
print(vars())
ff()
ff.a=20 # 给函数增加一个属性
v = vars(ff)
print(v)
{'l_a': 89}
{'l_a': 89}
{'a': 20}
- eval与exec函数
- 计算或者执行Python语句与表达式。
eval(source, globals=None, locals=None, /)
Evaluate the given source in the context of globals and locals.
exec(source, globals=None, locals=None, /)
Execute the given source in the context of globals and locals.
epr = ' 20 + (40-10) / 6, 20, print("heloo")'
r = eval(epr)
print(r)
heloo
(25.0, 20, None)
epr = '20 + (40-10) / 6, 20, print("heloo"), 30'
r =exec(epr) # 只是执行,不返回值
print(r)
epr = 'import math; r = math.sin(math.pi/6); print(r)'
exec(epr)
heloo
None
0.49999999999999994