转载请注明来源
InLoc: Indoor Visual Localization with Dense Matching and View Synthesis是H. Taira et al.发表在CVPR2018的一篇论文,研究了从一个大的室内3D地图中预测问询图像对应的6自由度位姿的问题。
作者设计的方案主要由三步构成:
(1)快速地检索相匹配的候选图片,保证了即使在大范围的场景中也有较好的实时性
(2)利用稠密匹配(而不是常见的局部特征匹配)来估计位姿,使得算法在纹理稀疏的场景中也有效
(3)利用从场景的3D模型中合成视野的方法验证估计的位姿
此外,作者还建立了一个数据集,并在数据及上验证了算法的效果。
简介
室内定位是智能移动机器人系统的关键功能,此外与增强现实(AR)等技术也密切相关。
与城镇环境的定位相比,室内定位主要面临以下困难:
(1)由于视距比较短,视野受位置的影响很大。
(2)室内场景中,很多部分是没有纹理的,有纹理的区域很小。
(3)室内场景常常单一、对称、重复。
(4)由于照明等因素,室内场景在一天内会发生很大的变化。
(5)室内场景常常是高度动态的,比如家具和人常常会移动。
因而作者提出了一个先针对建筑建立3D地图,随后使用相机估计当前位姿的方案。
相关工作
作者从如下三个侧面介绍了一些相关的工作,感兴趣的可以去查阅原文和引用:
基于图像检索的定位
基于先验3D地图的定位
室内3D地图
方法介绍
我们刚刚提到了室内环境给视觉定位带来的主要困难,作者设计的方案有针对性地解决了一些困难:
(1)缺乏稀疏的局部特征。SIFT、SURF等方法常常无法在室内场景中提取足够的特征(如墙面)。为了克服这个困难,作者采用多尺度稠密CNN特征(multi-scale dense CNN features)用于图片描述和特征匹配
(2)图像变化大。由于移动物体带来的场景变化,匹配出来的图像可能差别很大。作者因此没有依赖于匹配独立的局部特征,而是采取了稠密特征匹配的方法来收集尽可能多的支持证据——采用通过卷积神经网络提取的能够描述图像高层结构的图像描述子。
(3)自相似性。现有的匹配策略往往是统计支持证据(positive evidence),作者则提出可以同时统计负面证据(图像的哪一部分匹配不上)。更详细地,作者将问询图像(query image)与一个通过3D模型合成的虚拟视野比较。(事实证明这个方法极大地改善了效果。)
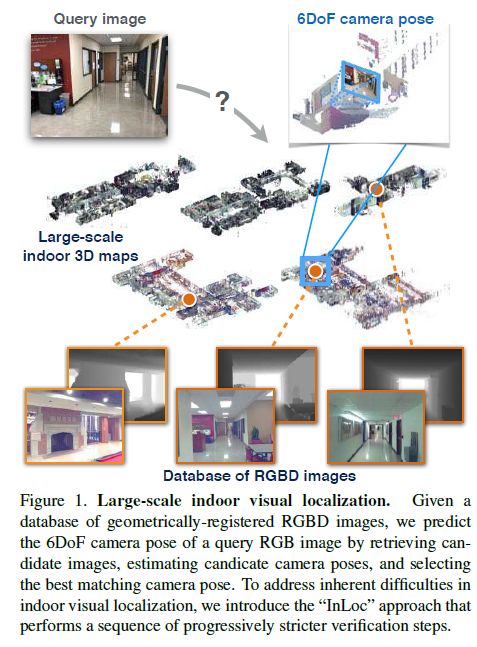
候选位姿(及图片)检索
作者用NetVLAD来描述问询图片和数据库图片,计算描述子之间均一化的距离,选取最优的个匹配图片,得到它们对应的位姿作为候选位姿。(关于NetVLAD,可以参考文末的两篇文章)
实际操作时,对于每张问询图片,作者通过4096维的NetVLAD描述向量从数据库中找到100个候选图片。
通过稠密匹配进行位姿估计
在上一步找到一些候选图片和对应的位姿后,作者利用一些稠密的特征来对这些候选图片进行验证和重排序。一个可能的方法是用DenseSIFT进行匹配,随后用基于RANSAC方法的验证。
然而作者在这里用CNN(VGG-16)提出的特征层表示图像,这样能够表示一组能够在一个更大的感受野描述更高层信息的多尺度的特征。
作者首先用含有高层信息的conv5层来找到一组对应信息。随后通过在conv3层寻找额外的匹配来细化之前找到的对应信息。
由于之前在使用NetVLAD表述问询图像时已经进行过卷积计算得到了特征层,因而这种操作不会额外消耗很多时间。
利用特征的对应信息,通过P3P-RANSAC的方法就能得到一个估计的位姿。
实际操作时,作者通过稠密地匹配通过CNN得到的特征得到可能的对应关系(correspondences),并用了一种由粗到细的方式:首先在conv5层特征中找到最接近的匹配,随后依据这些粗匹配在conv3中细化。这些匹配要经过RANSAC验证是否具有几何上的单应性关系。随后作者利用RANSAC在100个候选图像中筛选出10个最佳的数据集图像。对于这10个图像中的每一个,作者都用P3P-LO-RANSAC方法来估计6自由度位姿。
使用合成视野进行验证估计位姿
在这一步中,作者提出不仅收集支持证据,还要收集反对证据来判断是不是相匹配的。
考虑到光线的变化,作者比较的是局部面块的描述子(DenseRootSIFT)。
实际操作中,作者在考虑遮挡的情况下生成10个对应的合成图像,通过比较RootSIFT特征描述来打分,最后选出一个最佳图像。
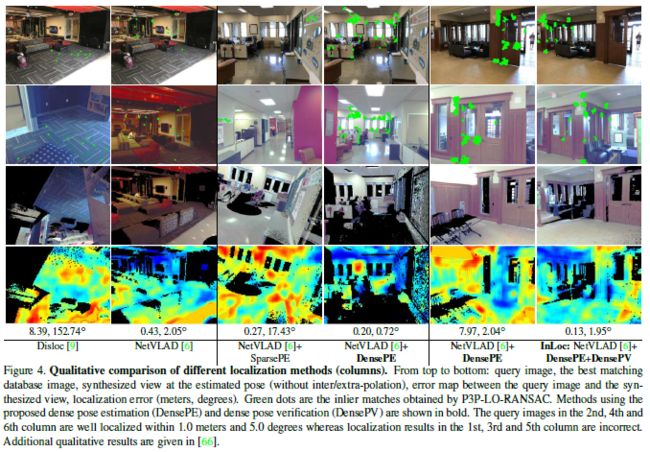
效果比较
总结
视觉室内定位是一个比较老的话题了,很长一段时间都无法取得较大的突破,整体的框架也相对稳定。这篇文章是对一些较新的技术的一个整合,利用了卷积神经网络的输出描述图像,如用NetVLAD来进行图像检索,用VGG-16的conv5和conv3来进行特征匹配。此外作者还添加了验证阶段,提高准确率,只是验证阶段需要有3D地图,这就牵扯到对场景进行3D重建的问题。整体来看,这篇文章比较难啃,因为涉及的方面比较多,好多部分的内容介绍得不是很详细。
相关知识点
DenseSIFT
传统的SIFT算法即Sparse SIFT,不能很好地表征不同类之间的特征差异,达不到所需的分类要求。而Dense SIFT算法,是一种对输入图像进行分块处理,再进行SIFT运算的特征提取过程。Dense SIFT根据可调的参数大小,来适当满足不同分类任务下对图像的特征表征能力。
经验表明,对于一些目标或者场景分类任务,在一个稠密的网格中计算SIFT描述子比稀疏的关键点得到的结果要更准确。一种比较基础的解释是,这样可以提供更多的信息。
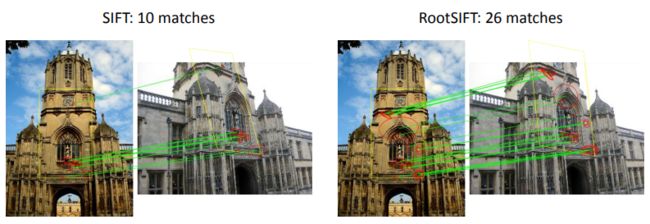
RootSIFT
牛津大学的R. Arandjelovic和A. Zisserman在CVPR2012上表示:
RootSIFT是一种有效的改善SIFT的方法,每个使用SIFT的人都应该尝试使用SIFT。
只需一行代码,你便可以把SIFT变成RootSIFT:
rootsift = sqrt( sift / sum(sift) );
BoW和VLAD
BoW(Bag of Word,词袋模型)或VLAD(Vector of Locally Aggregate Descriptor)是常用的图片分类或者图片检索的特征表示方式。以BoW为例,我们在对于每一幅图像提取了SIFT或者SURF特征后,利用这些特征建立一个字典。常见的做法是通过聚类得到个聚类中心,每个聚类中心对应一个编码,假设是每个特征描述子(编码)的维度,则这个字典可以被表示为一个的矩阵:
令是对于每一副图片提取的特征的数量,那每幅图片可以用一个的矩阵描述:
通过将每一个描述子对应到不同的聚类中,我们可以得到一个的矩阵,其中每一个量代表着描述子是(1)否(0)在所对应的聚类中。
这个的矩阵可以通过池化的方式进一步缩减为维向量。有两种不同的池化方式:平均池化(Average Pooling)和最大池化(Max Pooling),分别是求对应行的平均值和最大值。
对于VLAD来说,与BoW最大的区别在于BOW是把局部特征的个数累加到聚类中心上,而VLAD是把局部特征相对于聚类中心的偏差(有正负)累加到聚类中心上。

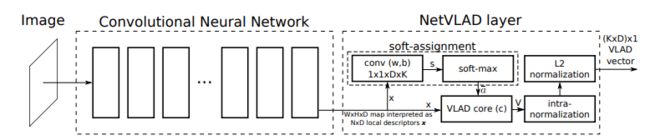
NetVLAD
整体的思想是将VLAD描述过程变成了CNN网络中的一个VLAD层。
经典的VLAD向量的计算公式可以表述为:
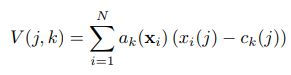
其中是表示第个点所在聚类的独热编码,是离散的。作者将替换成一种软边界,得到了连续的函数,并且能用soft-max层表示:
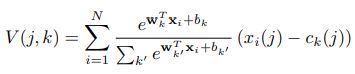
其中需要训练的参数包括,和聚类中心。
使用CNN特征层表示图像
P3P-RANSAC
参考
InLoc项目主页
jsjsdzd的CSDN博客(关于DenseSIFT)
R. Arandjelovic和A. Zisserman在CVPR2012上演讲PPT(关于RootSIFT)
SIFT和一些变种
曼陀罗彼岸花的CSDN博客(关于BoW)
NetVLAD: CNN architecture for weakly supervised place recognition(NetVLAD原文)
璇珠官人的知乎专栏:论文阅读-场景识别:NetVLAD
妖皇裂天:NetVLAD
作者的其他相关文章
基于视觉的机器人室内定位
论文阅读:StreetMap-基于向下摄像头的视觉建图与定位方案