On Deep Learning for Trust-Aware Recommendations in Social Networks
文章链接:https://www.researchgate.net/publication/295243846_On_Deep_Learning_for_Trust-Aware_Recommendations_in_Social_Networks?_sg=Obs_flkGvZ6OZbMpoiPuIfFH9ydcZAxNAz_av3xcdlPVorfBfdH9j90lLCKTyrTF55s3rqHrM__VzV8G5Prb1A
摘要
随着社会化网络的产生,基于社会化网络的推荐方法也越来越多,这种方法的好处是能够良好的处理冷启动问题。此外,对于社会化网络,用户信任信息在推荐系统可靠性上扮演重要角色,尽管矩阵分解的方法在学术推荐系统中广泛使用,这种推荐极大程度上依赖于用户和项目潜在特征矩阵的初始化。为了解决这一挑战,我们提出一种全新的基于信任的社会化推荐方法。我们试图利用深度学习来决定在矩阵分解当中的初始化问题,用于社会化信任感知推荐,,并且识别在不同社区下的用户信任关系的影响程度。推荐过程分为两部分:使用深度学习的初始化过程和融合用户兴趣偏好以及在不同社区群影响下的信任用户的兴趣偏好。在真是的社交数据集上进行了实验,证明是有效的。
介绍
仍存在的主要问题:
数据稀疏性
冷启动问题
可信赖性问题
矩阵分解技术是通过历史评分和信任关系来学习用户和项目的潜在因子,矩阵分解技术被认为是一种精确的模型化学习过程,通过使用训练数据建立模型。确切的说,更具体地说,它确实是一个优化确定模型参数的问题,以最佳逼近地面真理与预测。对于一个优化问题,有时是初始化的一个优化质量的关键问题。因子这就鼓励我们解决这个矩阵分解上的关键问题,试图同时解决这两个问题。
首先,目前的通常对用户和项目的潜在特征向量初始化的时候是简单机制的,例如随机和0初始化,实际上,从优化的角度来看,基于矩阵分解的方法是敏感的,对于用户和项目特征矩阵的初始化,由于在MF的最小化程序是非凸的。一个好的初始化能够产生最好的局部最小化,提升效率和精度。
在决定初始化用户和项目潜在特征向量时显而易见显然应该与学习算法相一致应用.用户潜在因子和项目矩阵的学习是在预测评分和实际评分R之间取得最小的损失函数。由于用户和项目都是高维的。可能存在一组局部全损失函数空间中的最优值,如何选择最佳的初始化会影响到矩阵的聚合程度。如果,我们得到用户项目潜在特征矩阵在一个低维空间中,将会更加容易处理初始化难的问题。为了解决这个问题,我们使用深度学习的方法,,他是一种有效的非线性降维的方法。的通过多层限制功能的限制Boltzmann机器将高维数据抽象到潜在特征RBMS
第二点,目前的模型没有考虑用户信任网络多样性,例如用户会在不同的领域主题下对不同的好友产生不同程度的信任。人们往往根据他们在社会关系中的社会关系,形成不同的社区一个被称为社区效应的社会网络。在这种社区关系下,不论是显式或隐式,都能够融合进社会化网络规则当中。直观的来看,根据与目标用户的相似程度,来自朋友当中不同子集朋友圈的推荐的贡献程度应当是不同的。也就是说,在一个社区中的用户相比于其他社区更趋向于本社区内部的相互信任,并且共享共同的偏好。因此,社区影响极大的影响着在社会化推荐过程中的推荐效果。
信任感知推荐
使用深度学习的自动化编码来学习初始化用户项目的潜在特征值,然后使用学习得到的特征值向量构建最小的目标函数,对于目标函数,我们考虑目标用户的特点和他们信任的朋友的推荐。此外,信任感知的正则化项还加入了描述信任传播。
A使用深度学习自动化编码的预处理阶段
由于矩阵分解是非凸的最优化问题,不保证都比矩阵(P和Q)是最佳的决定。对应于不同的初始P和Q值MF可以收敛不同的局部最优。我们分析了如何使用深自编码来pretrain评分矩阵和学习用户和项目的潜在特征的初始值。
评分矩阵
每一行代表用户的历史对每项的评分,因此我们定义用户向量
Un×m =[U1, . . . , Ui, . . . , Um] =R^T ,
其中
特点:高维,稀疏
在对准确的特征向量进行调查时MF模型中,我们可以观察到类似的用户(例如,用户为相同的项目评分类似的分数)有类似的用户特征向量。基于这一观察,我们可以直观地得出这样的结论,if the initialization of feature vectors characterized
the similarities of users and items more precisely,
因此,我们试图获得初始值
自动化编码是一种人工神经网络,其目的在于学习对高维数据的压缩。Hinton and Salakhutdinov提出了一种训练的预处理技术使用多层深度自动编码,使用使用一个反向传播技术微调
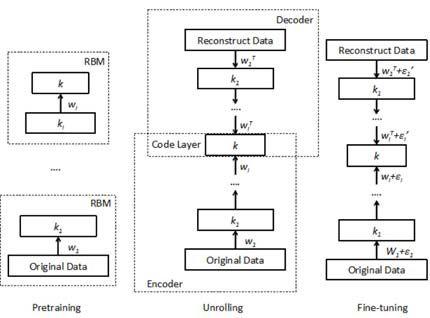
包含一个encode网络和一个decode网络,encode网络的目标是将高维编码转换为低维编码,decode网络可被视为是该过程的逆过程。是重建从代码的原始数据。链接的一部分两个网络被称为代码层,这是核心的整个系统,并确定了内在维度原始数据。
深度自动化解码的主要过程是使用RBM学习两个网络的权重开始。然后使用反向传播的误差衍生工具来训练通过最小化两个网络之间的偏差原始数据及其重构。由于RBM是仅能用于二值数据,而评分数据不能理想的适用,因此使用连续RBM(CRBM)来预处理权重。
CRBM是由可见层和隐藏层组成,分别连接输入输出数据
将一个用户向量做输入输出Un×m和U�‘p ×m,n-dimensional user vector能够encode成为p-dimensional vectors.n visible units可见单元vi和p hidden units隐藏单元h j ,,定义其之间权重且有wi j = w j i

 Paste_Image.png
Paste_Image.png



CRBM的主要encoding阶段如下:
最后multiple CRBMs to encode the
n-dimensional user vectors to the final k-dimensional vectors
B社会化信任集成
the trust values are given in a matrix T = [Tu,v]m×m .
the first we do is to propose a new model of trust degree no
matter the trust values are assigned explicitly or not.
preference similarity to model
trust degree Tu,v将目标用户偏好融入信任度模型当中

trust(u,v)是由用户u指派的信任值0,1
Su即与用户u直接连接的用户集。请注意,这个方程只适用于两个直接链接的用户。对于不使用的用户链接直接,我们使用乘法作为信任传播计算信任度
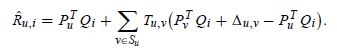
C正则化社区效应
如前所述,社交网络表现出强烈的群落的影响。社交网络中的用户有一种倾向紧密连接的形式组。组也所谓的社区集群,集团在不同的上下文中。此外,一组中的人往往彼此信任和与彼此有共同的偏好比那些更多的在其他组。因此,在这一节中,我们将讨论如何纳入信任社会网络中的社区效应作为正则化项的修改提出了MF模型细节。
图形挖掘技术已被广泛用于社会网络中的社区检测,因为它们是有效的在识别隐藏在基础数据中的组。社区检测的一个重要类型是识别基于网络中的行动者之间的可达性集团。受社会现有的社区结构n-集团,在社会学学科中,我们提出的n-trust-clique(集团)识别派系在一个基于信任关系的社交网络中用户和开发一个算法来检测集团TrustCliques。我们选择n-clique的原因是这种方法有助于检测重叠社区。此外,它是值得注意,我们不直接适用于n-clique原因在社交网络上,是链接信息本身会导致检测精度低,而信任信息有助于保证良好的性能。
社区检测的主要定义
n-clique是其中一个最大的子图,每一对的最大距离节点的不大于n。