
长期以来,对应分析(Correspondence analysis ,CA)是分析物种有无或多度数据最受欢迎的工具之一。原始数据首先被转化成一个描述样方对对Pearson 卡方统计量的贡献率的矩阵,将获得的矩阵通过奇异值分解(SVD)技术进行特征根和特征向量的提取。因此,CA的排序结果展示的是样方之间的卡方距离,而不是欧式距离。卡方距离不受零值的影响,因此,CA非常适用于原始的物种多度分析,要求数据非负和同纲量就行。
和PCA一样,正交的CA排序轴所承载的变差(variation)也是按顺序逐步降低,但与PAC不同的是,这里的总变差不是用总方差来表示,而是通过一个叫总惯量(total inertia)的指标来表示。
CA 也有两种类型的标尺。
- 1型标尺:行(样方)是列(物种)的形心。关注的对象,对象之间的距离是卡方距离。一个样方的点靠近一个物种的点,表示物种对于该样方的贡献比较大。
- 2型标尺:列(物种)是行(样方)的形心(centroid)。物种之间的距离是卡方距离。一个物种的点靠近样方,表示该物种在该样方中存在的可能性很大。
Kaiser-cuttman和断棍模型同样适用于CA排序轴的取舍。
# ======================================
# 导入本章所需的程序包
library(ade4)
library(vegan)
library(gclus)
library(ape)
rm(list = ls())
setwd("D:\\Users\\Administrator\\Desktop\\RStudio\\数量生态学\\DATA")
# 导入CSV文件数据
spe <- read.csv("DoubsSpe.csv", row.names=1)
env <- read.csv("DoubsEnv.csv", row.names=1)
spa <- read.csv("DoubsSpa.csv", row.names=1)
# 删除没有数据的样方8
spe <- spe[-8,]
env <- env[-8,]
spa <- spa[-8,]
# 原始物种多度数据的对应分析(CA)
# *******************************
# 计算CA
spe.ca <- cca(spe)
spe.ca
Call: cca(X = spe)
Inertia Rank
Total 1.167
Unconstrained 1.167 26
Inertia is scaled Chi-square
Eigenvalues for unconstrained axes:
CA1 CA2 CA3 CA4 CA5 CA6 CA7 CA8
0.6010 0.1444 0.1073 0.0834 0.0516 0.0418 0.0339 0.0288
(Showed only 8 of all 26 unconstrained eigenvalues)
summary(spe.ca) #默认scaling= 2
Call:
cca(X = spe)
Partitioning of scaled Chi-square:
Inertia Proportion
Total 1.167 1
Unconstrained 1.167 1
Eigenvalues, and their contribution to the scaled Chi-square
Importance of components:
CA1 CA2 CA3 CA4 CA5 CA6 CA7 CA8 CA9 CA10 CA11 CA12
Eigenvalue 0.601 0.1444 0.10729 0.08337 0.05158 0.04185 0.03389 0.02883 0.01684 0.010826 0.010142 0.007886
Proportion Explained 0.515 0.1237 0.09195 0.07145 0.04420 0.03586 0.02904 0.02470 0.01443 0.009278 0.008691 0.006758
Cumulative Proportion 0.515 0.6387 0.73069 0.80214 0.84634 0.88220 0.91124 0.93594 0.95038 0.959655 0.968346 0.975104
CA13 CA14 CA15 CA16 CA17 CA18 CA19 CA20 CA21 CA22 CA23
Eigenvalue 0.006123 0.004867 0.004606 0.003844 0.003067 0.001823 0.001642 0.001295 0.0008775 0.0004217 0.0002149
Proportion Explained 0.005247 0.004171 0.003948 0.003294 0.002629 0.001562 0.001407 0.001110 0.0007520 0.0003614 0.0001841
Cumulative Proportion 0.980351 0.984522 0.988470 0.991764 0.994393 0.995955 0.997362 0.998472 0.9992238 0.9995852 0.9997693
CA24 CA25 CA26
Eigenvalue 0.0001528 8.949e-05 2.695e-05
Proportion Explained 0.0001309 7.669e-05 2.310e-05
Cumulative Proportion 0.9999002 1.000e+00 1.000e+00
Scaling 2 for species and site scores
* Species are scaled proportional to eigenvalues
* Sites are unscaled: weighted dispersion equal on all dimensions
Species scores
CA1 CA2 CA3 CA4 CA5 CA6
CHA 1.50075 -1.410293 0.26049 -0.307203 0.271777 -0.003465
TRU 1.66167 0.444129 0.57571 0.166073 -0.261870 -0.326590
VAI 1.28545 0.285328 -0.04768 0.018126 0.043847 0.200732
LOC 0.98662 0.360900 -0.35265 -0.009021 -0.012231 0.253429
OMB 1.55554 -1.389752 0.80505 -0.468471 0.471301 0.225409
(......)
Site scores (weighted averages of species scores)
CA1 CA2 CA3 CA4 CA5 CA6
1 2.76488 3.076306 5.3657489 1.99192 -5.07714 -7.80447
2 2.27540 2.565531 1.2659130 0.87538 -1.89139 -0.13887
3 2.01823 2.441224 0.5144079 0.79436 -1.03741 0.56015
4 1.28485 1.935664 -0.2509482 0.76470 0.54752 0.10579
(......)
summary(spe.ca, scaling=1)
Call:
cca(X = spe)
Partitioning of scaled Chi-square:
Inertia Proportion
Total 1.167 1
Unconstrained 1.167 1
Eigenvalues, and their contribution to the scaled Chi-square
Importance of components:
CA1 CA2 CA3 CA4 CA5 CA6 CA7 CA8 CA9 CA10 CA11 CA12
Eigenvalue 0.601 0.1444 0.10729 0.08337 0.05158 0.04185 0.03389 0.02883 0.01684 0.010826 0.010142 0.007886
Proportion Explained 0.515 0.1237 0.09195 0.07145 0.04420 0.03586 0.02904 0.02470 0.01443 0.009278 0.008691 0.006758
Cumulative Proportion 0.515 0.6387 0.73069 0.80214 0.84634 0.88220 0.91124 0.93594 0.95038 0.959655 0.968346 0.975104
CA13 CA14 CA15 CA16 CA17 CA18 CA19 CA20 CA21 CA22 CA23
Eigenvalue 0.006123 0.004867 0.004606 0.003844 0.003067 0.001823 0.001642 0.001295 0.0008775 0.0004217 0.0002149
Proportion Explained 0.005247 0.004171 0.003948 0.003294 0.002629 0.001562 0.001407 0.001110 0.0007520 0.0003614 0.0001841
Cumulative Proportion 0.980351 0.984522 0.988470 0.991764 0.994393 0.995955 0.997362 0.998472 0.9992238 0.9995852 0.9997693
CA24 CA25 CA26
Eigenvalue 0.0001528 8.949e-05 2.695e-05
Proportion Explained 0.0001309 7.669e-05 2.310e-05
Cumulative Proportion 0.9999002 1.000e+00 1.000e+00
Scaling 1 for species and site scores
* Sites are scaled proportional to eigenvalues
* Species are unscaled: weighted dispersion equal on all dimensions
Species scores
CA1 CA2 CA3 CA4 CA5 CA6
CHA 1.93586 -3.71167 0.79524 -1.06393 1.19669 -0.01694
TRU 2.14343 1.16888 1.75759 0.57516 -1.15306 -1.59651
VAI 1.65814 0.75094 -0.14555 0.06277 0.19306 0.98127
LOC 1.27267 0.94983 -1.07661 -0.03124 -0.05385 1.23887
OMB 2.00654 -3.65761 2.45774 -1.62244 2.07523 1.10190
BLA 1.28617 -3.89487 -1.46646 0.27497 -0.46548 -1.62514
HOT -0.70838 -0.13563 0.03428 -0.33249 -1.68537 0.65900
TOX -0.23836 -1.15198 -1.75354 1.46935 -2.58533 0.44908
VAN 0.01724 -0.25092 -1.76067 0.73427 0.55774 -1.90211
CHE 0.01391 0.36998 -1.06276 -1.86417 0.81585 0.81679
BAR -0.43036 -0.79135 -0.15048 0.59208 -0.69219 0.50384
(......)
Site scores (weighted averages of species scores)
CA1 CA2 CA3 CA4 CA5 CA6
1 2.14343 1.168878 1.7575907 0.575155 -1.153061 -1.59651
2 1.76398 0.974804 0.4146591 0.252762 -0.429551 -0.02841
3 1.56461 0.927572 0.1684981 0.229368 -0.235605 0.11459
(......)
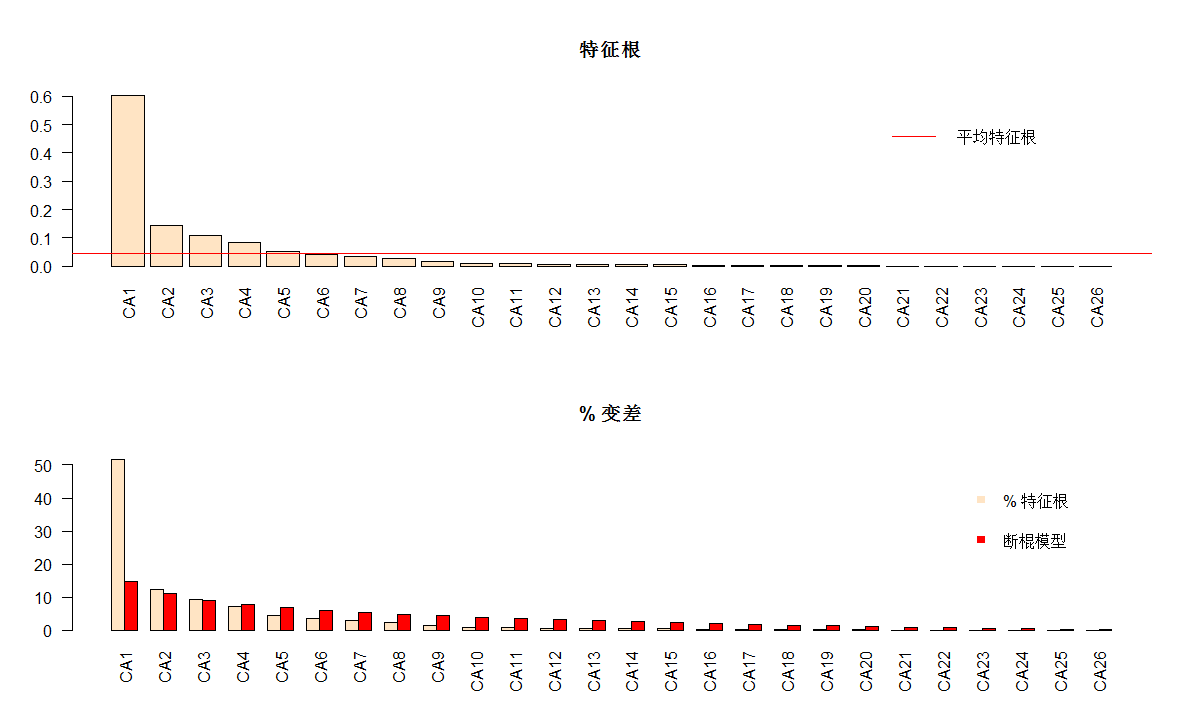
第一轴有一个很大的特征根。在CA里面,如果特征根超过0.6,代表数据结构梯度明显。第一轴特征根占总惯量多少比例呢?需要注意的是,两类标尺下,特征根一样。标尺的选择,只影响特征向量,不影响特征根。
#尺下,特征根一样。标尺的选择,只影响特征向量,不影响特征根。
# 绘制每轴的特征根和方差百分比
(ev2 <- spe.ca$CA$eig)
evplot(ev2)
CA1 CA2 CA3 CA4 CA5 CA6 CA7 CA8 CA9
6.009926e-01 1.443709e-01 1.072938e-01 8.337321e-02 5.157826e-02 4.184649e-02 3.388638e-02 2.882547e-02 1.684112e-02
CA10 CA11 CA12 CA13 CA14 CA15 CA16 CA17 CA18
1.082639e-02 1.014213e-02 7.885549e-03 6.123133e-03 4.867260e-03 4.606481e-03 3.843808e-03 3.067492e-03 1.823032e-03
CA19 CA20 CA21 CA22 CA23 CA24 CA25 CA26
1.641868e-03 1.295163e-03 8.775034e-04 4.217149e-04 2.148505e-04 1.527935e-04 8.948679e-05 2.695049e-05
> evplot(ev2)
#这里,断棍模型比Kaiser-Guttman准则更保守。无论是数量分析结果、还是
#条形图都显示第一轴占绝对优势。
# CA双序图
# *********
par(mfrow=c(1,2))
# 1型标尺:样方点是物种点的形心
plot(spe.ca, scaling=1, main="鱼类多度CA双序图(1型标尺)")
# 2型标尺(默认):物种点是样方点的形心
plot(spe.ca, main="鱼类多度CA双序图(2型标尺)")
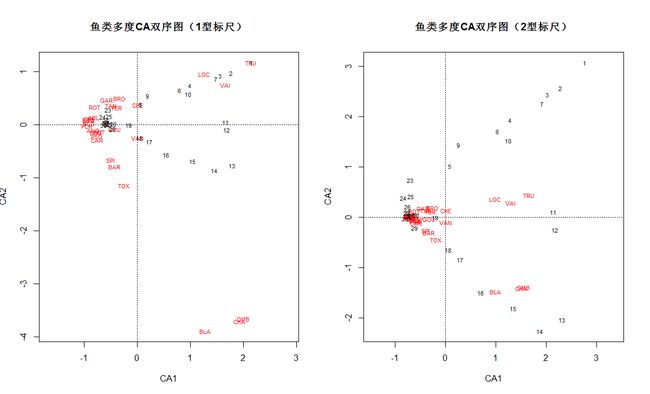
1 型标尺更适合解释样方之家的关系和样方的梯度排列;2型标尺更适合解释物种之间的关系和梯度分布。
CA排序中被动加入环境因子
plot(spe.ca, main="鱼类多度CA双序图(2型标尺)")
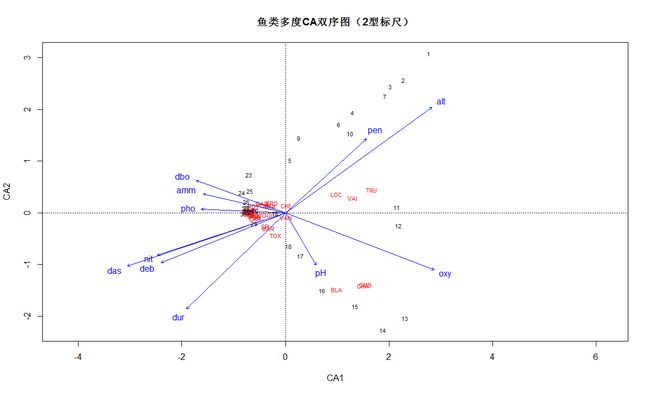
# CA排序中被动加入环境因子
# 调用最后生成CA结果对象(2型标尺)
spe.ca.env <- envfit(spe.ca, env)
plot(spe.ca.env)
# 这个命令的目的是在最后双序图加入环境变量
#新加入的环境变量信息对解读双序图是否有帮助?
基于CA排序结果的数据表格重排
vegemite(spe, spe.ca)
2322222222211 11 1 11 11 1
40867235190985976604547312231
PCH .53122..14...................
BBO 155244..3421.................
BCO .53234..3411.................
GRE 255454.135211................
ANG .54232..24211..1.............
ABL 5555552355532..2.............
ROT .52112.12221.2...............
BOU .54233..35322..1.............
PSO 134233..25211..11............
CAR .54123..23111..11............
HOT 111113..22221..1.............
GAR 255455115555254211...........
SPI .51111..23323..41............
TAN .54354..4342131112.11........
BAR .33245..45423..32...21.......
GOU 154345.2554422.1211121.......
PER .52114..342134.211.2.........
BRO .43243.1352114.111.2.1.1.....
TOX .21.12..22233..44............
CHE 23423411243132522221311.11...
VAN .32123.1232225.3512.3.1......
LOC ..1111..11253234554554551432.
BLA .........1.11..25...43.....2.
VAI ........11133314344545454445.
CHA ............1..12...33..12.2.
OMB .........1..1..1....24..12.3.
TRU .........1..12.23314455535553
sites species
29 27
#当前输出的表格与传统的群落数据表格排列方式相反,现在以行为物种,以#列为样方。物种排列顺序和样方排列顺序依赖于排序轴的方向(其实是任
#意的)。可以发现,单纯基于第一轴的结果重新排列数据表格,并没有达
#到最佳的效果。因为第二轴所反映的上游(样方1-10)到中游(样方11-18)#的梯度,以及这些样方的特征种,在这个表格里并没有聚集,而是分散的。
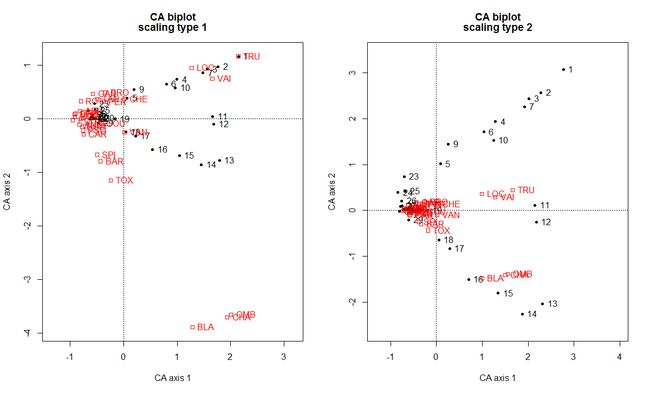
使用函数CA()进行对应分析
# ************************
source("CA.R") #导入CA.R脚本,此脚本必须在当前工作目录下或给路径
spe.CA.PL <- CA(spe)
biplot(spe.CA.PL, cex=1)
# 用CA第一轴排序结果重新排列数据表格
# 重新排列数据表格与vegemite()输出的结果一样
summary(spe.CA.PL)
Length Class Mode
total.inertia 1 -none- numeric
eigenvalues 26 -none- numeric
rel.eigen 26 -none- numeric
rel.cum.eigen 26 -none- numeric
U 702 -none- numeric
Uhat 754 -none- numeric
F 754 -none- numeric
Fhat 702 -none- numeric
V 702 -none- numeric
Vhat 754 -none- numeric
site.names 29 -none- character
sp.names 27 -none- character
color.sites 1 -none- character
color.sp 1 -none- character
call 2 -none- call
t(spe[order(spe.CA.PL$F[,1]),order(spe.CA.PL$V[,1])])
24 30 28 26 27 22 23 25 21 29 20 19 18 5 9 17 16 6 10 4 15 14 7 3 11 12 2 13 1
PCH 0 5 3 1 2 2 0 0 1 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
BBO 1 5 5 2 4 4 0 0 3 4 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
BCO 0 5 3 2 3 4 0 0 3 4 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
GRE 2 5 5 4 5 4 0 1 3 5 2 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ANG 0 5 4 2 3 2 0 0 2 4 2 1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
ABL 5 5 5 5 5 5 2 3 5 5 5 3 2 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0
ROT 0 5 2 1 1 2 0 1 2 2 2 1 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
BOU 0 5 4 2 3 3 0 0 3 5 3 2 2 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
PSO 1 3 4 2 3 3 0 0 2 5 2 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0
CAR 0 5 4 1 2 3 0 0 2 3 1 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0
HOT 1 1 1 1 1 3 0 0 2 2 2 2 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
GAR 2 5 5 4 5 5 1 1 5 5 5 5 2 5 4 2 1 1 0 0 0 0 0 0 0 0 0 0 0
SPI 0 5 1 1 1 1 0 0 2 3 3 2 3 0 0 4 1 0 0 0 0 0 0 0 0 0 0 0 0
TAN 0 5 4 3 5 4 0 0 4 3 4 2 1 3 1 1 1 2 0 1 1 0 0 0 0 0 0 0 0
BAR 0 3 3 2 4 5 0 0 4 5 4 2 3 0 0 3 2 0 0 0 2 1 0 0 0 0 0 0 0
GOU 1 5 4 3 4 5 0 2 5 5 4 4 2 2 0 1 2 1 1 1 2 1 0 0 0 0 0 0 0
PER 0 5 2 1 1 4 0 0 3 4 2 1 3 4 0 2 1 1 0 2 0 0 0 0 0 0 0 0 0
BRO 0 4 3 2 4 3 0 1 3 5 2 1 1 4 0 1 1 1 0 2 0 1 0 1 0 0 0 0 0
TOX 0 2 1 0 1 2 0 0 2 2 2 3 3 0 0 4 4 0 0 0 0 0 0 0 0 0 0 0 0
CHE 2 3 4 2 3 4 1 1 2 4 3 1 3 2 5 2 2 2 2 1 3 1 1 0 1 1 0 0 0
VAN 0 3 2 1 2 3 0 1 2 3 2 2 2 5 0 3 5 1 2 0 3 0 1 0 0 0 0 0 0
LOC 0 0 1 1 1 1 0 0 1 1 2 5 3 2 3 4 5 5 4 5 5 4 5 5 1 4 3 2 0
BLA 0 0 0 0 0 0 0 0 0 1 0 1 1 0 0 2 5 0 0 0 4 3 0 0 0 0 0 2 0
VAI 0 0 0 0 0 0 0 0 1 1 1 3 3 3 1 4 3 4 4 5 4 5 4 5 4 4 4 5 0
CHA 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 2 0 0 0 3 3 0 0 1 2 0 2 0
OMB 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 1 0 0 0 0 2 4 0 0 1 2 0 3 0
TRU 0 0 0 0 0 0 0 0 0 1 0 0 1 2 0 2 3 3 1 4 4 5 5 5 3 5 5 5 3
奇异值分解(SVD)详解及其应用
奇异值分解(SVD)原理详解及推导
奇异值的物理意义是什么?
对应分析中总惯量的意义是什么?
排序--3--CA对应分析Correspondence analysis