主题:如果训练模型 经过多次迭代后,需要进一步精简
学习算法是否具有增量学习能力是衡量其是否适合于解决现实问题的一个重要方面。增量学习使学习算法的时间和空间资源消耗保持在可以管理和控制的水平 ,已被广泛应用于解决大规模数据集问题。因此,在随着样本信息的不断更新,原有的训练集模型会包含过多错误的、过时的分类信息,不利于分类边界的划分的情况下,需要进行一定的修剪数据集。
本文中介绍3种增量学习算法和这些算法中的修剪策略:
第一种,C2EV-KNNMODEL算法,根据训练样本的每个特征参数对样本的分类贡献度和样本的贡献有限度来判断是否需要修剪。修剪后可以减少计算量和提高模型精度,能够有效地降低增量训练集模型的复
杂度,解决KNN在无穷增量环境下,分类精度低、不平稳,且健壮性差,泛化性能低的缺陷。
第二种,在IKNNMODEL增量学习方法,通过合并和删除模型镞的方法对它进行修剪, 降低了模型的复杂度, 增加了泛化能力, 提高了预测效率.该算法更好的适用于实际领域中.
第三种,基于推拉策略中心法的增量学习模型ICCDP,设置好必要的参数,若样本分类错误,则用推拉公式修正正确类与错误类的中心向量 ,并重新计算这两个类的归一化中心。该算法易于实现 ,训练和分类速度快 ,而且该算法的分类性能接近一次性学习算法的性能。
1、C2EV-KNNMODEL的修剪算法
增量学习的效果直接影响到KNN的效率和准确率。提出基于分类贡献有效值的增量KNN修剪模型(C2EV-KNNMODEL),将特征参数的分类贡献度与KNN增量学习结合起来,定义一种新的训练样本的贡献有效值,并根据此定义制定训练集模型的修剪策略。理论和实验表明,C2EV-KNNMODEL的适用性较强,能够使分类器的分类性能得到极大的提高。
1.1引言
KNN是一种典型的非参数的、有效惰性学习方法,是数据挖掘、机器学习和模式识别研究中的重点技术[1]。但KNN 自身并不具备增量学习的特性,是一种静态的学习方法,对于一些数据每天都在增加、变化的应用领域,如股市、气象预测、网络入侵、电力、银行等,无论是分类精度,还是分类效率,适用性都较差。因此,如何设置KNN增量学习的方法,使KNN训练集模型在增量过程中保持较高的有效分类信息量的条件下,控制训练集模型的样本数量,成为国内外学者研究的热点。在下面就提出了KNN增量学习算法和一种基于分类贡献有效值的增量KNN修剪模型(ClassificationContributionEffective Value,C2EV-KNNMODEL)
1.2 KNN增量学习算法简介
KNNMODEL提出了簇优化训练样本集的概念,在原始训练样本集上构建多个簇,由于产生的簇的数量远低于训练集样本的数量,因此可提高KNN的分类效率,且每个簇的大小可根据训练集的分布情况动生成,从而减少对参数K的依赖。
IKNNMODEL 是基于 KNNMODEL 常用的增量学习方法。它通过对训练集样本模型簇引进“层”的概念,对新增数据建立不同“层”的新模型簇的方式对原有训练集样本模型进行优化,达到增量学习的效果,其具体学习算法参见文献[4]。随着样本信息的不断更新,原有的训练集模型会包含过多错误的、过时的分类信息,不利于分类边界的划分。IKNNMODEL在原始训练集样本模型的基础上构建新的模型簇,使得新增模型与原始训练集模型的交叉区域更加准确,并赋予新的模型簇更高的层值,使其能覆盖旧训练集模型的错分区域,通过增量学习不断地进行修正。
1.3 C2EV-KNNMODEL的修剪算法
KNN类别判断是一种典型的、基于案例的学习,其过程必然与训练样本自身的类别特征有关。因此,如何确定训练样本针对类别的贡献程度颇为重要。首先给出特征参数分类贡献度的定义,并对其可行性进行了分析,然后在此基础上定义样本的贡献有效值,验证其有效性和准确性
下图就对分类贡献度和贡献有效值进行了定义:

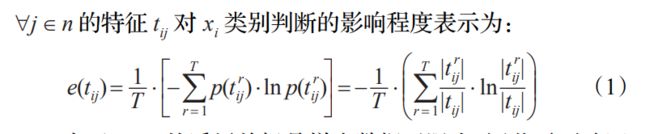

1.4 C2EV-KNNMODEL修剪的实现
针对增量KNN模型修剪的准确性和效率问题,在上述算法有效性及精度分析的基础上,给出C2EV-KNNMODEL修剪模型在学习阶段的基本步骤,其核心思想是:借助式(1)确定每个特征参数对样本类别判断的影响程度;根据式(5)确定原始训练集和增量集中各个样本的分类贡献有效值,分别取其均值作为两个数据集彼此修剪的判断依据;循环执行,直至增量集不再增加。具体执行过程如下:
输入:原始KNN训练集S,样本个数为m;若干z个增量步训练集,每个增量步训练集的样本数为mz个
输出:修剪后的KNN训练集模型。
**步骤1 根据特征参数分类贡献度的定义,由式(1)对训练集S中所有不同的、还未计算过的特征参数进行分类贡献度的特征转换。
步骤 2 根据贡献有效值的定义,由式(5)计算训练集 S中 各样本的 W(xi),并计算 S 的平均贡献有效值,并设置该平均贡献有效值为增量训练集 z1 的修剪阀值。阀值。
步骤3 根据特征参数分类贡献度的定义,由式(1)对 z1 增量步训练集中所有不同的特征参数进行分类贡献度的特征转换。
步骤4 根据贡献有效值的定义,由式(5)计算增量步训练
集 z1 中各样本的W(xi),并计算 z1 的平均贡献有效值,并设置该平均贡献有效值为训练集 S 的修剪阀值。
步骤5 对训练集S进行修剪
for i=0 to m
if W(xi) < ----- W(z1) then W(xi) 对应的删除强度值加1
if W(xi) 对应的删除强度在一段时间内大于k(文献[6]中的生存期),即W(xi) 均连续小于k个增量步训练集的平均贡献有效值then样本 xi 对于分类所起的作用已失效,删除掉 xi 样本;
步骤6 对 z1 增量步训练集进行修剪
for i=0 to m′
if W(xi) ≥ ------ W(S) then W(xi) 对应的添加强度值加1;
if W(xi) 对应的添加强度在一段时间内大于k,即W(xi) 均连续大于k个增量步训练集修剪后的训练集S的平均贡献有效值then样本xi 对于分类所起的正面作用越来越大,将 xi 添加入训练集S;
步骤7 用修剪后的训练集模型替换原始训练集S,跳回步骤1,继续执行下一个增量步训练集的修剪工作
1.6 总结
修剪机制的设置是增量KNN算法的重点。通过对特征参数分类贡献度和贡献有效值两个方面的研究,提出基于分类贡献有效值的增量 KNN 修剪模型(C2EV-KNNMODEL)。

实验表明,CEV-KNNMODEL 性能优于文献[1]、文献[2]及传统IKNNMODEL等算法,能够有效地降低增量训练集模型的复杂度,解决KNN在无穷增量环境下,分类精度低、不平稳,且健壮性差,泛化性能低的缺陷。下一步改进的重点有:(1)特征参数分类贡献度 e(tij)、贡献有效值W(xi) 计算所需的索引结构及搜索技术是制约C2EV-KNNMODEL分类效率的瓶颈;(2)贡献有效值 W(xi) 的生存周期,即 k 值的计算。改进后,C2EVKNNMODEL的准确率和训练集样本数量规模应该有进一步提升的空间。
2、增量KNN模型的修剪策略研究
KNN模型是 k-近邻算法的一种改进版本, IKNNModel算法实现了基于 KNNModel的增量学习.然而随着增量步数的增加, IKNNModel算法生成模型簇的数量也在不断地增加, 从而导致模型过于复杂, 也增大了预测的时间花销.提出一种新颖的模型簇修剪策略, 在增量学习过程中通过有效合并和删除多余的模型簇, 在保证精度的同时降低了模型簇的数量, 从而缩短了算法的预测时间.在一些公共数据集上的实验结果验证了本方法的有效性.
2.1 引言
KNN模型算法(简记 KNNModel)是 Guo[ 1]等人提出的一种改进的 KNN算法.它克服了传统 KNN分类算法参数 k难以确定以及分类新数据时间耗费大的两个缺陷.KNNModel通过有监督地构建数据的多个 KNN模型簇, 以此代替原始数据集作为分类的基础 .传统的 KNNModel算法是静态的学习算法, IKNNModel算法 [ 2] 则是基于 KNNModel的增量学习算法.IKNNModel算法通过对模型簇引进"层"的概念, 达到增量学习的效果, 使得 KNNModel算法能够适用于一些数据每天都在增加的应用领域, 如网络入侵, 股市分析, 电力, 银行等.然而, 随着增量步数的增加, 算法生成模型簇的数量也会同时增加, 从而严重地影响了预测时间.而在这些实际应用领域中, 增量步数可以看成是无限大的,因此,需要控制模型簇的数量成了亟需解决的问题.
2.2 KNNMODEL算法
KNN模型算法(简记 KNNModel)是 Guo[ 1]等人提出的一种改进的 KNN算法, 它改进了传统 KNN分类算法前述的两个缺陷.KNNModel在数据集上构建多个 KNN模型簇, 以此代替原数据集作为分类的基础, 由于产生的模型簇的数量远远小于训练集中的样本个数, 因此提高了分类的效率;而每个模型簇的大小由 KNNModel算法根据数据集的分布情况自动形成, 从而减少了对参数 k的依赖, 并在一定程度上提高了分类的精度.
2.3 IKNNModel算法
IKNNModel是基于 KNNModel的增量学习方法, 它通过对 KNNModel产生的模型簇引进"层"的概念, 对新增数据建立不同"层"的新模型簇的方式对原有模型进行优化 , 达到增量学习的效果 [ 2] .当一个模型簇覆盖了过多的错分样本时, 说明这个模型簇在某些区域是不够准确的.因此 IKNNModel提出一种层的概念, 在新训练数据上建立新模型簇, 并通过用高层的模型簇覆盖低层模型簇的方法, 对原有模型进行优化,见图 2.3.1
图 2.3.1中有方形和三角形两类新样本点, 原有的模型簇 old中包含了过多的错分点, 显然在边界处不够准确.而在新样本基础上构建的新模型簇 new在交叉区域则更加准确.因此我们赋予新模型簇更高的层值, 使其能覆盖旧模型簇的错分区域, 这样就使得原有模型能够通过增量学习不断地得到修正.
2.4 增量 KNNModel的修剪策略
在 IKNNModel增量算法中, 由于训练样本不是一次性到达, 算法在不同层次建立了多个模型簇.在多个增量步后IKNNModel算法建立的模型簇数量将比用 KNNModel算法直接在整个训练集上建立的模型簇数量来得多.而在金融, 入侵检测等实际应用领域中, 增量的步数可以看成是无穷大的.这样, 随着增量步数的不断增加, 过多的模型簇将对预测时间产生严重的影响, 而并非所有的模型簇都对预测样本产生正面的作用.因此, 在 IKNNModel算法中对模型簇进行修剪是很有必要的.
本文通过合并和删除两种方法对 IKNNModel算法进行修剪.其中, 我们通过合并的修剪方法, 将同层中同类模型簇合并成一个新的模型簇, 并用这个新的模型簇取代原有的同类模型簇.这样, 在减少了模型簇的数量的同时提高了算法的泛化能力.另外, 利用删除的修剪方法删除掉多余的模型簇.有些模型簇因为发生了概念漂移而无法正确反映当前的数据分布情况, 有些模型簇由于被其他高层异类的模型簇所覆盖, 而在预测新样本时不起作用.这些模型簇的存在对预测样本无法起到正面的作用, 因此, 我们需要删除这些模型簇.这样, 在减少模型簇数量的同时, 使得算法能够更加适应增量过程中数据的概念变化[ 11] .
2.5 IKNNModel修剪方法
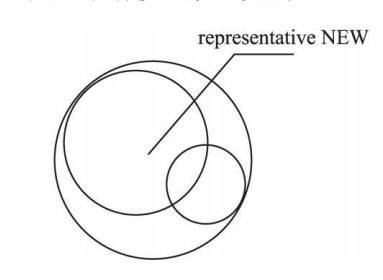
2.5.1 模型簇的合并操作

图 2.5.1中模型簇 1和 2的类别相同 , 层值相同 , 若模型簇new中不包含其它类别的数据点, 则可用模型簇 new
2.5.2模型簇的删除操作
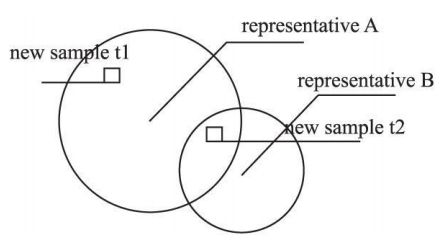
根据文献[ 2] 中预测阶段的叙述, 可以认为在预测新数据样本时, 对一个新数据样本的类别真正起决定作用的只是某一个模型簇.如图 4例子所示, 假设模型簇 A的层值大于模型簇 B的层值.由于在预测阶段, 当一个样本被多个模型簇覆盖时, 选择层值高的模型簇的类别 [ 2] .因此, 实际上对新数据样本t1,t2的类别起决定作用的都是模型簇 A.图中 t2虽然同时被模型簇 A, B所覆盖, 但模型簇 B由于层值小于 A, 所以对于 t2类别的预测是不起作用的.
在每次增量步中, IKNNModel算法先对新的一批训练样本进行预测.假设在预测过程中模型簇 i对 n个被正确分类的新样本类别起决定作用, 则模型簇 i的有效值为 n;而当模型簇 i对错误分类的新样本起到决定作用时, 则不增加其有效值.当某个模型簇在一段时间内 (或者说 k次增量步中)的有效值都为 0, 那么认为这种模型簇已经失效了.如果一个模型簇是无效的, 说明这个模型簇或者由于发生了概念漂移, 或者由于被其它高层的模型簇所覆盖, 而在预测中无法起到作用.这些模型簇的存在对预测新样本没有正面的作用, 反而增加了预测时间, 因此, 需要将这样的模型簇删除.
2.6 带修剪的 IKNNModel算法实现
带修剪的 IKNNModel算法在学习阶段的基本步骤如下:
输入:n个新的训练样本和已有的 IKNNModel模型, 参数 k;
输出:修剪后的 IKNNModel模型
Step1.用已有的 IKNNModel模型对每个新训练样本进行分类, 并计算每个模型簇的有效值;
Step2.利用 IKNNModel算法对已有模型进行更新[ 2] ;
Step3.删除 在连 续 k次 增量 步中有 效值 都为 0的 模
型簇;
Step4.遍历所有模型簇, 若存在能够合并的模型簇, 则通过公式(1)-(5)对模型簇进行合并;
Step5.输出更新后的模型簇.其中, 参数 k类似于文献[ 10] 中的生存期, k值越小算法对过去样本的"遗忘 "率则越高 [ 7] .Step1中, 由于在新样本到达时 IKNNModel算法都要先对其进行分类, 然后对正确分类和错分两种情况分别做处理 [ 2], 因此可以在分类时计算每个模型簇的有效值.
2.7 结 论
本文提出了一种增量 KNN模型的修剪策略.通过合并和删除模型簇, 降低了模型的复杂度, 增加了泛化能力, 提高了预测效率.

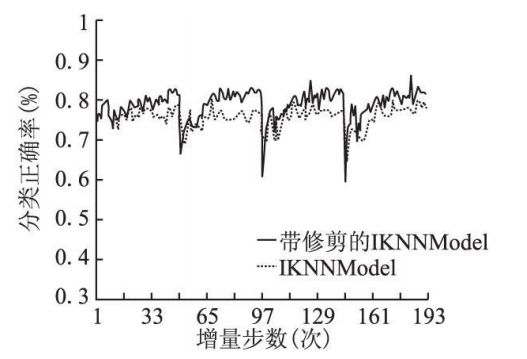
在 UCI机器学习公共数据集, KDDCUP′99入侵检测数据集以及移动超平面数据集上的实验结果表明, 通过修剪, IKNNModel能更好的适用于实际领域中.
3、基于推拉策略的文本分类增量学习研究
学习算法是否具有增量学习能力是衡量其是否适合于解决现实问题的一个重要方面。增量学习使学习算法的时间和空间资源消耗保持在可以管理和控制的水平 ,已被广泛应用于解决大规模数据集问题。针对文本分类问题 ,本文提出了增量学习算法的一般性问题。基于推拉策略的基本思想 ,本文提出了文本分类的增量学习算法ICCDP ,并使用该算法对提出的一般性问题进行了分析。实验表明 ,该算法训练速度快 ,分类精度高 ,具有较高的实用价值。
3.1 引言
传统的文本分类方法 ,即非增量学习算法 ,或者称为一次性学习算法 ,根据当前所获得的所有训练样本计算得到文本分类模型 ,如中心法、朴素贝叶斯(NB) 、K最近邻方法 ( KNN) 、支持向量机 (SVM) 、决策树方法(Decision Tree) 等。然而它们并不总是有效,原因:(1) 训练样本很难一次性获得。(2) 内存限制。
在这种情况下 ,我们需要根据已经获得的分类器模型 ,增量学习新的训练样本 ,并更新现有的分类器模型。其中 ,对每一批样本进行增量学习得到一个新的模型 ,称为经过一个增量步。增量学习使得一种学习算法更适合于现实应用。它使学习算法的时间和空间资源消耗保持在可以管理和控制的水平 ;或者用于训练数据不足时需要做出分类决定的情形 ,比如在线环境中。
3.2 相关工作
3.2.1 推拉策略
文献[ 9 ,10 ]将推拉策略引入到中心法 ,使得中心法的性能显著提高 ,分类精度接近 SVM ,但训练速度远快于 SVM。推拉策略的基本思想是利用错分样本对误分入的类别中心和所属中心同时做出修正 ,推远错误中心 ,拉近正确中心。这样既保证了错误修正的一致性 ,又能很快达到高水平的性能平衡点。经过“推拉”操作之后 ,样本被正确分类的可能性大大提高。该策略对全部训练样本进行分类 ,对每一个错分样本都要进行“推拉”操作。推拉操作仅需重复执行少量次数就能达到稳定的性能。经证明 ,在线性可分情况下 ,推拉策略在训练集上是收敛的。
3.3 基于推拉策略的增量学习模型
3.3.1 模型描述
中心分类法将已学习过的训练样本压缩为各个类的中心来表示 ,而且更新中心法模型的代价较小。这两种属性使得中心法特别适合于增量学习。将推拉策略引入到中心法得到的文本分类器训练速度快 ,分类精度高。因此 ,我们提出了一种基于推拉策略中 心 法 的 增 量 学 习 模 型 ICCDP ( Incremental Centroid Classifier based on Dragp ushing) 。
ICCDP 的算法描述如下 :


3.4 结论和下一步工作
当训练样本需要分批处理时 ,传统的文本分类方法并不总是有效。增量学习算法作为一种解决方案引起广泛关注。本文重点对增量学习算法设计和研究中的一般问题进行研究。同时 ,提出一种增量学习算法 ICCDP。该算法易于实现 ,训练和分类速度快 ,而且该算法的分类性能接近一次性学习算法的性能。我们利用 ICCDP 进行了一系列实验 ,对增量学习中的一般问题做进一步的探讨。得出的结论是 ,该算法对参数不敏感、对样本输入顺序轻微敏感 ,而且该算法是一个高效的增量学习算法。
增量学习与一次性学习一个很大的区别是 : 增量学习面对的是一个开放的环境 ,可以不断地接收新的训练样本 ;而一次性学习处在一个封闭的环境中 ,一次学习完所有样本。这种区别就使得增量学习面临以下问题 : 随着增量步数的增加 ,可能发生概念漂移 ,如何早一些检测到概念漂移 ,并自适应地调整分类器模型 ,就显得非常重要。
总结
因为训练样本很难一次性获得等等的原因,所以增量学习模型适用于现实中大多数情况。那么当训练模型迭代训练多次时,就需要对训练集和增量集或训练的模型进行一定的修剪策略来提高最终模型的精确度和降低计算量。因此需要看情况来进行相应的修剪策略来达到上述所说目的。
参考文献:
【1】周 靖,刘晋胜, 基于分类贡献有效值的增量KNN模型修剪研究
【2】黄 杰 , 郭躬德 , 陈黎飞,增量 KNN模型的修剪策略研究
【3】罗长升,段建国,郭 莉,基于推拉策略的文本分类增量学习研究