-1、https://www.numpy.org.cn/article/basics/an_introduction_to_scientific_python_numpy.html
-1.5、https://www.kaggle.com/thele0nx/learning-pandas-numpy-matplotlib-and-scipy
0、核查数据质量的函数/用法:

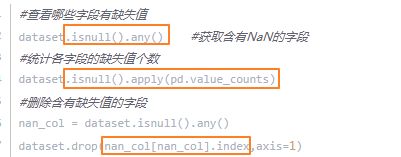
更巧妙地查找缺失值个数/列名的方法:判断 data_df [columnname].count() != len(data_df) # 后者减去前者即该列缺失值的个数
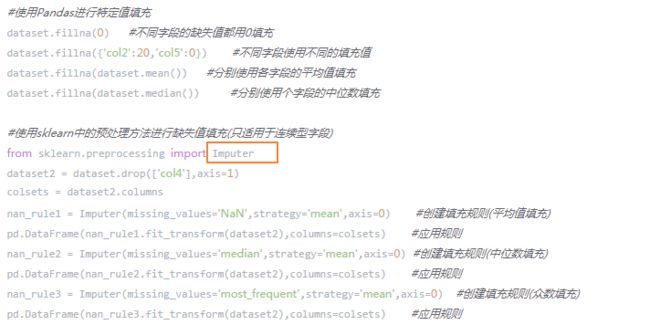
补充,用dataframe自带的方法实现用众数填充缺失值:df.fillna(df.mode().iloc[0])——因为df.mode()返回的是一个dataframe,很多同最大频率的值都会返回。
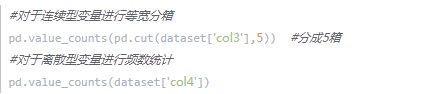

1、df.iloc[:,-2] ----取表的倒数第二列 df.iloc[0] ----取表的第一行
2、获取列名:list(my_dataframe.columns.values) 或者 list(my_dataframe) 或者 [column for column in df] ----得到column名字的list
3、索引问题:
for provin provinces:
reg ='\A' + prov
df_county_in_province = df_2861_county.filter(regex=reg, axis=0)
gov_codes = df_county_in_province.index
# 遍历一个省下的所有县
for gov_code in gov_codes:
if gov_code in df_2861_county.index.values:
……
4、切片问题: ——好久不用又忘记了!!!2018/6/14
for node_name in env_corners:
# 获得一个node类型
node_type = df_node[df_node['name'] == node_name]['is_bottom'].values[0] //不是 .values()[0]!!! —— 会报错:'numpy.ndarray' object is not callable
print(df_node[df_node['name']==node_name]['is_bottom'])
print(df_node[df_node['name'] == node_name]['is_bottom'].values)
print(node_type)
输出:
【df_node[df_node['name']==node_name]['is_bottom']】:
4 1
Name: is_bottom, dtype: object
【df_node[df_node['name'] == node_name]['is_bottom'].values】:
['1']
【df_node[df_node['name'] == node_name]['is_bottom'].values[0]】:
1
5、清洗NAN:
df_new = df_new.where(df_new.notnull(), '本区县暂无数据')
补充:
5/1
DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False, raise_on_error=None)
cond : boolean NDFrame, array-like, or callable
Where cond is True, keep the original value. Where False, replace with corresponding value from other.
5/2
判断np.nan和None的方法:
① df.isnull() ------True为np.nan或None, False为其他值
②df.notnull() ----与①结果相反,True为其他值, False为np.nan或None
③df != df ——True为np.nan或None, False为其他值
5/3
在dataframe里查找nan的位置:
# 获取索引名
① df.index [ np.where(np.isnan(df['gov']))[0] ].tolist() —— 又忘了。。。2019/3/2
[0]----对应取行号
② df[ df['gov'] != df['gov'] ].index
③ df.index[ df['gov'] != df['gov'] ] —— 又忘了。。。2018/7/13
# 获取列名
df.columns [ np.where(np.isnan(df))[1] ].tolist()
[1]-----对应取列号

6、排名
df_new['ENV_rank'].rank(method='first', ascending=False)

7、加列:
一、加一列:

二、加两列以上:
(1)第一个方法是利用pd.concat 在DataFrame后面添加两列,这种方法的缺点是不能指定位置
pd.concat([df, pd.DataFrame(columns=list('DE'))])

(2)第二种方法是利用 reindex来重排和增加列名df.reindex(columns=list('ABCDE'))
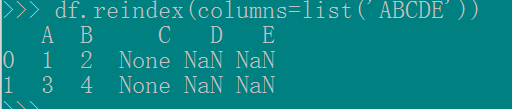
这种方法,你可以改变各列的相对位置,且保留原始列的数值,比如df.reindex(columns=list('BCADE'))
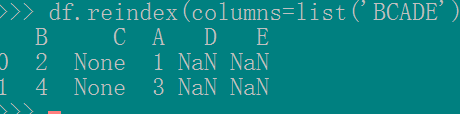
reindex 还有 fill_value 选项,可以填充NaN,例子如下df.reindex(columns=list('ABCDE'), fill_value=0)
三、list.insert
list.insert的方法list.insert(index, obj)
参数
index -- 对象obj需要插入的索引位置。
obj -- 要插入列表中的对象。
先获取原列名集合, 赋值给新变量(这个很重要,具体原因我也不知道为啥), 然后 insert
col_name = df.columns.tolist()
col_name.insert(1,'D')
df.reindex(columns=col_name)
Out[92]:
A D B C01 NaNNoneNone13 NaNNoneNone
或者不用数字索引,直接在某列前面或后面插入,利用 list.index的方法
col_name = df.columns.tolist()
col_name.insert(col_name.index('B'),'D')# 在 B 列前面插入df.reindex(columns=col_name)
Out[93]:
A D B C01 NaNNoneNone13 NaNNoneNone
col_name = df.columns.tolist()
col_name.insert(col_name.index('B')+1,'D')# 在 B 列后面插入df.reindex(columns=col_name)
Out[96]:
A B D C
01None NaNNone
13None NaNNone
8、axis=0 VS axis=1:
其实问题理解axis有问题,df.mean其实是在每一行上取所有列的均值,而不是保留每一列的均值。也许简单的来记就是axis=0代表往跨行(down),而axis=1代表跨列(across),作为方法动作的副词(译者注)
换句话说:
使用0值表示沿着每一列或行标签\索引值向下执行方法
使用1值表示沿着每一行或者列标签模向执行对应的方法
下图代表在DataFrame当中axis为0和1时分别代表的含义:

axis参数作用方向图示
另外,记住,Pandas保持了Numpy对关键字axis的用法,用法在Numpy库的词汇表当中有过解释:
轴用来为超过一维的数组定义的属性,二维数据拥有两个轴:第0轴沿着行的垂直往下,第1轴沿着列的方向水平延伸。
所以问题当中第一个列子 df.mean(axis=1)代表沿着列水平方向计算均值,而第二个列子df.drop(name, axis=1) 代表将name对应的列标签(们)沿着水平的方向依次删掉。
9、dataframe改列名:
a.rename(columns={'A':'a', 'C':'c'}, inplace = True)
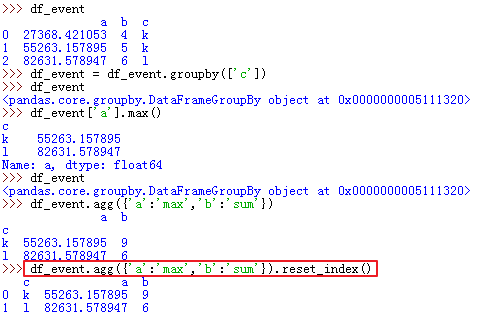
10、dataframe——groupby,注意apply操作的用法~~
group_by_province = df_dataset.groupby([df_dataset['gov_code'].apply(lambda x: int(int(x) / 10000)),
df_dataset['full_name'].apply(lambda x: x.split('|')[0])])
mean = group_by_province.mean()['total_score'].reset_index()
max = group_by_province.max()['total_score'].reset_index()
min = group_by_province.min()['total_score'].reset_index()
count = group_by_province.size().reset_index()
11、
df=DataFrame([{‘A’:’11’,’B’:’12’},{‘A’:’111’,’B’:’121’},{‘A’:’1111’,’B’:’1211’}])
print df.columns.size#列数 2
print df.iloc[:,0].size#行数 3
print df.ix[[0]].index.values[0]#索引值 0
print df.ix[[0]].values[0][0]#第一行第一列的值 11
print df.ix[[1]].values[0][1]#第二行第二列的值 121
12、
1) df.loc['c']——通过行标签索引行数据
2) df.iloc[0]——通过行号获取行数据
3) df[0:2] #取前两行数据
# map, apply, lambda太好用了!!!!少写了好多循环啊@!!!!!
13、对dataframe一整列进行某函数操作: —— 太神奇了!!!!!!【只要没有任务的压力,Python还是很好玩儿的……】
df_temp['content_pre'] = df_temp['content'].apply(lambda x:TextDispose(x).text_preparation(weibo_min_len, weibo_max_len))
df_temp['content_pree'] =list(map(lambda x:TextDispose(x).text_preparation(weibo_min_len, weibo_max_len), df_temp['content']))
注意:lambda函数,前面是形参,后面是返回值
print(df_temp)
print(df_temp['content_pre'] == df_temp['content_pree']) //都是用的同一个函数处理,看结果是否一致
输出结果:

14、# 清洗None / np.nan
df_temp.drop(df_temp.index[df_temp['content_pre'] != df_temp['content_pre']], inplace=True) //去掉所在行 —— 2018/8/1 又忘了。。。
df_temp[ratio_col].replace([np.nan, '', None], 0, inplace=True) //直接替换成0
# inplace=True使改变发生在原表上!!!\
15、总结一下merge(多基于index),concat(可以ignore index), join等等 —— 都是基于index的,不好弄。。。直接赋值添加列吧
16、遍历取dataframe的简便方法:
for index, row in df_temp.iterrows(): // 注意:只写 for row in df_temp.iterrows()的话,取row['col']会报错!!!
print(row['col'])
print(index)
PS:这里的iterrows()返回值为元组,(index,row)
上面的代码里,for循环定义了两个变量,index,row,那么返回的元组,index=index,row=row.
17、dataframe按某一列的值排序:df.sort_values(by=['col1'])
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html
18、 建议表达:dfmi.loc[:,'one'] ——取列操作
dfmi['one']会报warning;注:dfmi.iloc[a,b]——a,b只能为整数(第a+1行,第b+1列)
19、pd.read_sql()
20、dataframe删除行:
df_temp.drop(df_temp.index[df_temp['content_pre'] != df_temp['content_pre']], inplace=True)
21、dataframe.update —— 可以满足多个分块dataframe对同一个dataframe更新填值的操作 —— 20190626
与dataframe.fillna区分开,fillna也可以传dataframe

22、研究一下
23、dataframe drop_duplicates,groupby, pivot_table
24、dataframe有一个坑:如果直接pd.read_json,会做一些意想不到的转换,比如,把日期字符串转换为timestamp格式存入pandas中。但如果先将load成字典,再用pd.DataFrame.from_dict,则可保持原有的日期字符串格式。另外,无论是read_json还是from_dict转换,都不能保证字典的顺序也能以相应行序存入dataframe中(顺序可能完全打乱),所以转为pandas后用sort_values先排个序,再处理。
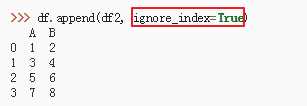
25、df.append(df0, ignore_index=True)
26、Series取值:索引列为数字时,Series[n],n只能为索引值;如果索引列为字符串(如:"a","b","c"等),Series[n],取的是对应第n+1行的数据
27、dataframe - dtype


原因?

因为字符串长度是不固定的,pandas没有用字节字符串的形式而是用了object ndarray

28、取每个县的最后一个名字:(ps,gov_name样例:‘四川省|成都市|高新区’)df_class_city["gov_name"].str.split('|', n=-1, expand=True).iloc[:,-1]
另一种dataframe不同列之间的拼接(相加)方法:
- 类型相同(都为字符串):df1['i'].str.split('|',n=-1, expand=True).iloc[:,-1] + '['+df1['a']+']'
- 类型不同(字符串和整型的拼接):
df1['i'].str.split('|',n=-1, expand=True).iloc[:,-1] + '['+df1['b'].map(str)+']'

29、dataframe.str. :https://www.cnblogs.com/P--K/p/8443995.html
30、index / reindex / reset_index —— 研究下
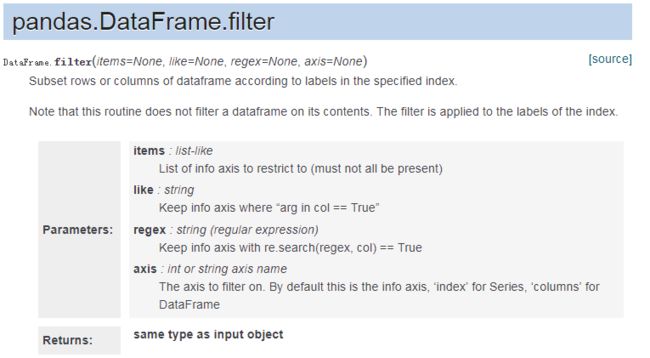
31、dataframe.filter
32、某一列取整/四舍五入/转换类型:
df['event'].map(str) / df['event'].apply(int) / df['event'].apply(numpy.round)
33、dataframe groupby agg【分组后各列的操作不一样】:
34、修改列名:

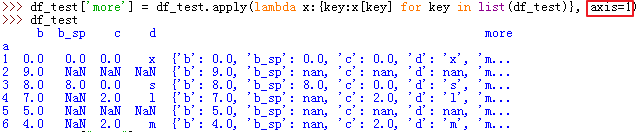
35、dataframe.update —— 可实现更新总表中部分值的作用:

36、lambda 函数的axis参数:
37、join

常用:
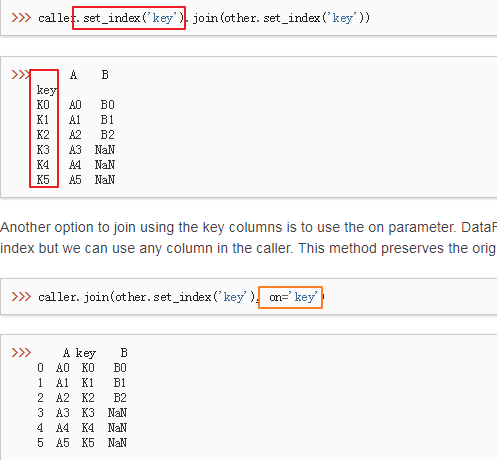
38、根据某列的值在一个已有列表中的行,取另一列的值
missing_govs = df_2861_gaode_geo.loc[df_2861_gaode_geo["gov_id"].isin(missing_govids)]["full_name"].values.tolist()
39、列名按指定顺序,输出dataframe
方法一:
如果列少,这是最直观,也最简洁的方法
order = ['date', 'time', 'open', 'high', 'low', 'close', 'volumefrom', 'volumeto'] df = df[order] # 肥肠巧妙!!!
方法二:
查询自下面的链接。
https://blog.csdn.net/u012560212/article/details/54928255
先把需要调整的列的数据拿出来,之后,再将这个列删掉,最后,再用插入的方式把这个列调整到对应的位置上。下面这段代码把数据调到了第一列。
df_id = df.id
df = df.drop('id',axis=1)
df.insert(0,'id',df_id)
注意:
insert( n, 'col_name', col) 中 n 必须是 >= 0的整数。
如果列很多,倒数比较方便,可以用 df.shape[1] 先算出这个 df一共有多少列,
再 df.shape[1]-1 就是倒数第二列啦~
另,如果我只是想把新增的一列插入到df中,放在最后一列位置就可以,此时 concat函数即可。
dis_series 是新的一列,series的类型。
output = pd.concat([rawdt,dis_series],axis=1)
40、dataframe append 容易改变原df列名顺序的问题:


41、dataframe基本操作函数整理:https://blog.csdn.net/hhtnan/article/details/80080240
42、dataframe查看每列空值个数:_dataframe.sum()是个功能!!能统计出每列的总值,输出以列名为index的Series

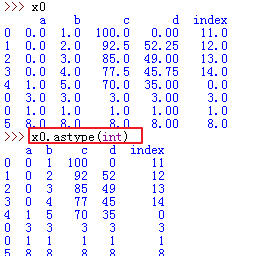
43、整个dataframe数据转换:
1)astype
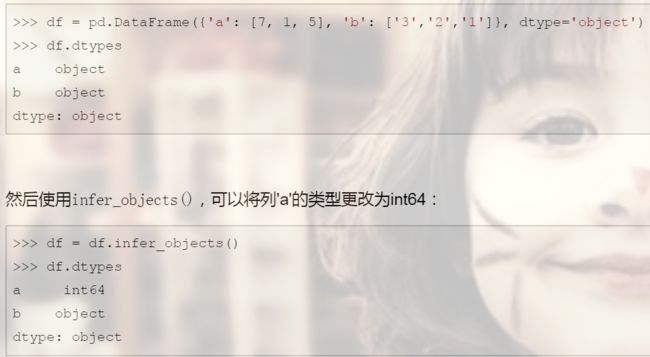
2)软转换——infer_objects() 类型自动推断
3) pd.to_numeric() _转换为数值


4) 另外pd.to_datetime和pd.to_timedelta可将数据转换为日期和时间戳。
44、numpy.array数组去掉nan:

45、numpy里的空值填充:

记住,numpy永远是以坐标的方式在操作,不像pandas是以表为对象用功能函数~~
注意:list不能像numpy这样坐标定位的方式:
numpy:

list:

46、如何使整个dataframe四舍五入取整? 先加0.5, 再astype(int),很巧妙啊!!!

47、问题:读取csv文件指定index_col/处理dataframe的过程中, 可能产生原有index独立出来为列,列名为:Unnamed:0,很烦。如下图:

Unnamed
解决方法:很巧妙~~~df = df.loc[:, ~df.columns.str.contains('^Unnamed')] # 取列名不包含Unnamed开头的列
48、pandas 多sheet的excel修改
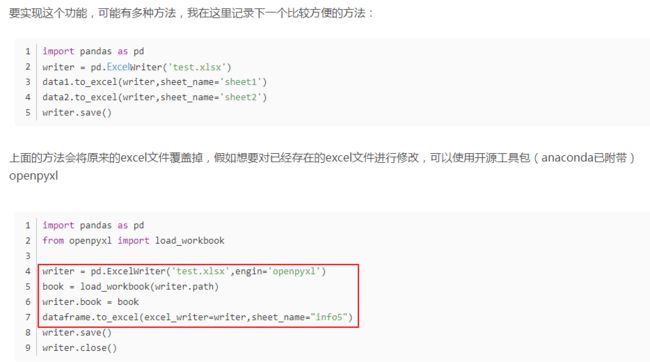
不加时,会擦除之前的,仅储存本次写入的sheet


问题:我只想修改已存在的excel里某个sheet怎么办?当前用openyxl可以做到,但sheet_name相同时不会覆盖,只会重新生成一个原名+1的sheet。。。 ??? 之后研究一下20190223
49、numpy.log 可以对整个dataframe操作!!!太方便了!!!
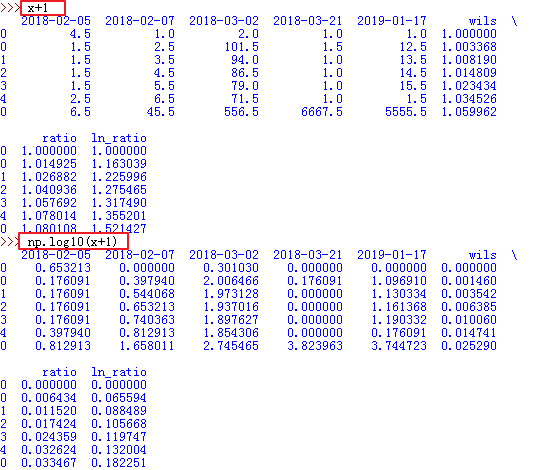
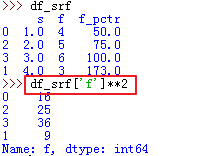
50、pandas 某一列求n次幂 —— **n
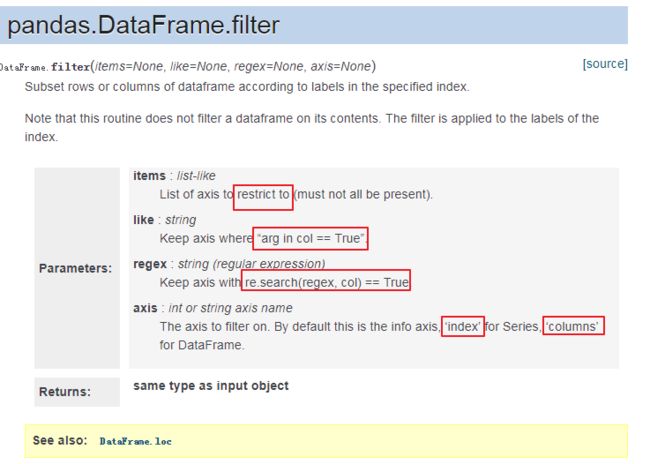
51、dataframe.filter
52、reset_index 和 multiIndex —— 多层级index的处理
http://blog.sina.com.cn/s/blog_12c3192a50102xdzq.html
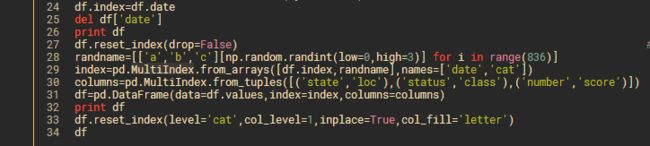
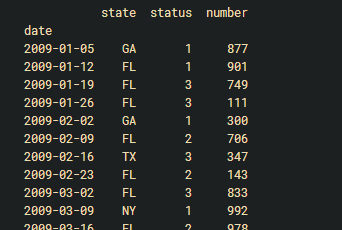


由于groupby这个函数不能对index进行组合,所以可以通过reset_index()把index变成columns后在进行groupby的计算,例如df.reset_index().groupby(['state','status']).sum()
如果写成df=df.reset_index().groupby(['state','date']).sum() 可以通过df.loc['FL']['2009':'2010']按年份提取
53、多层级索引降级:https://blog.csdn.net/flyfoxs/article/details/81346885
54、定义多索引dataframe
index = pd.MultiIndex.from_arrays([['GA', 'TX'], ['2019-03-01' , '2019-03-03']], names=['state', 'date'])
df_added = pd.DataFrame(data=[[2,3],[4,5]],index=index, columns=['x','y'])
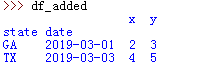
55、按层级获取多重索引的索引值:df.index.get_level_values(level_num).values



56、多重索引不同方法取值效果
原表:
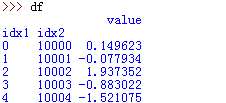
df.index:

df.index[0]:并不是取出一个维度的index,而是取出多重index的第一行的tuple
df.index.get_level_values(0):取出level0的全部index
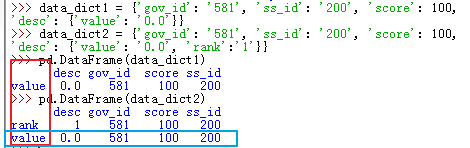
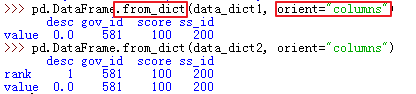
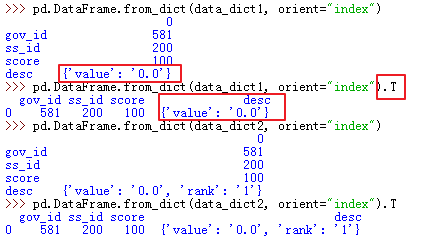
57、pd.DataFrame(data_dict) .VS. pd.DataFrame.from_dict(data_dict, orient="index")
eg:
data_dict1 = {'gov_id': '581', 'ss_id': '200', 'score': 100, 'desc': {'value': '0.0'}}
data_dict2 = {'gov_id': '581', 'ss_id': '200', 'score': 100, 'desc': {'value': '0.0', 'rank':'1'}}
1) pd.DataFrame(data_dict)
2) pd.DataFrame.from_dict(data_dict, orient="columns")
pd.DataFrame(data_dict) 等效于 pd.DataFrame.from_dict(data_dict, orient="columns")
3) pd.DataFrame.from_dict(data_dict, orient="index")
58、pandas.DataFrame.to_dict


59、【dataframe数据透视表】pandas.pivot_table:
https://www.cnblogs.com/onemorepoint/p/8425300.html
60、一行内容拆分成多行:https://blog.csdn.net/erinapple/article/details/80737449
61、矩阵/数组,存成txt:
np.savetxt(txt_path, df_label_num.values, fmt="%d:%s", delimiter="\r\n")
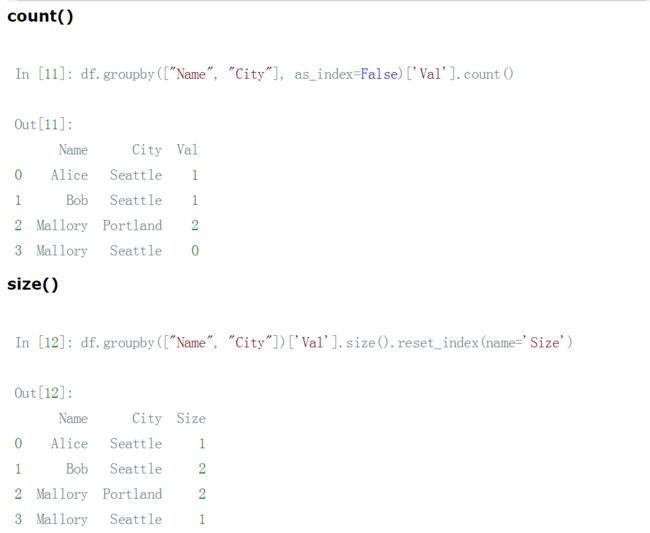
62、pandas groupby 后统计每类个数 - .count() / .size()
63、# 对sentence字段,按逗号,句号和分号等各种符号拆分
df_unmatch_ad = df_unmatch_data.drop("sentence", axis=1).join(df_unmatch_data["sentence"].str.split(para.PUNCTUATION_R, expand=True).stack().reset_index(level=1, drop=True).rename("sentence"))
.stack() —— 把列堆叠转到行索引
.reset_index(level=1, drop=True) —— 删除第一层的索引,且不将索引插回到列中
level : int,str,tuple或list,默认为None
仅从索引中删除给定的级别。默认情况下删除所有级别。
drop : bool,默认为False
不要尝试将索引插入到dataframe列中。这会将索引重置为默认整数索引。
64、np.einsum:https://zhuanlan.zhihu.com/p/27739282
65、pd.to_csv('your.csv', index=False)

66、pandas 数据类型 - dtypes
https://juejin.im/post/5acc36e66fb9a028d043c2a5
67、切片取series:
data.iloc[-1] #选取DataFrame最后一行,返回的是Series
切片取dataframe:
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
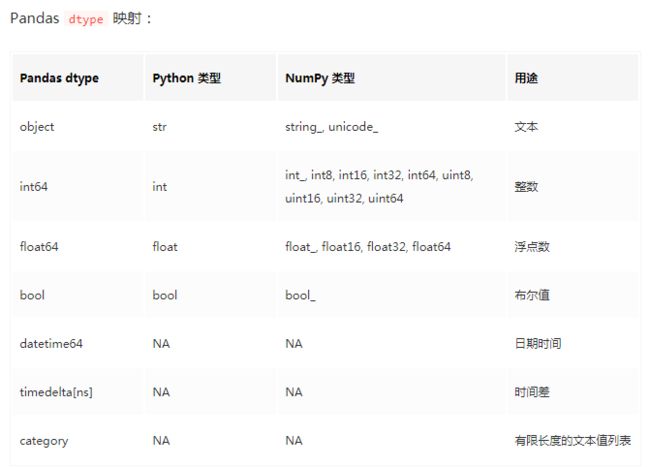
68、用字典形式 一行一行写dataframe:
1)append
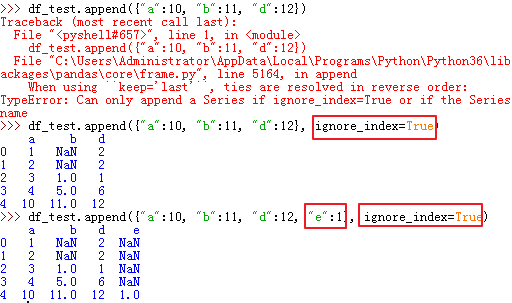
2).loc

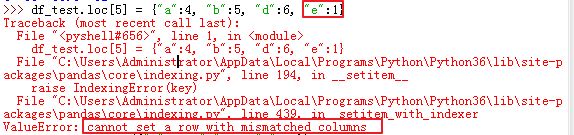
69、转变索引的数据类型
#changetypetounicodeifnotisinstance(df.index,unicode):
df.index= df.index.astype(unicode)
70、multiindex - 多重索引检索
df_average = df_average.set_index(["region_type","gov_id", "gov_code", "gov_name"], drop=True)
df_average.loc[(slice(None), slice(None),slice(None),"河北省|石家庄市"),:] —— 唯一标准的表达,必须写全所有索引列(无筛选的列用slice(None)),用圆括号
71、reindex - 重置索引,没有的补0
https://blog.csdn.net/zhili8866/article/details/68134481

71.5、注意:reindex的坑:a = a.reindex(b.index, fill_value=0),会洗掉原本a有的,但b没有的索引;
所以如果需求只是:把b中有的索引,给a补全;a中本来的索引及数据都保留,则应该这么做:a = a.reindex(a.index | b.index, fill_value=0)
取两个dataframe的索引并集。
72、集合交/并/差集
>>> x = set('spam')
>>> y = set(['h','a','m'])
>>> x, y
(set(['a','p','s','m']), set(['a','h','m']))
再来些小应用。
>>> x & y# 交集
set(['a','m'])
>>> x | y# 并集
set(['a','p','s','h','m'])
>>> x - y# 差集
set(['p','s'])
73、调整列的顺序:
df = df.reindex([新顺序列名], axis='columns') / df.reindex([新顺序列名], axis=1)
删除指定列:
df = df.drop([需要删除的列名], axis=1)
