1.Tomcat的总体结构及其工作原理
https://www.ibm.com/developerworks/cn/java/j-lo-tomcat1/
Tomcat 的总体结构
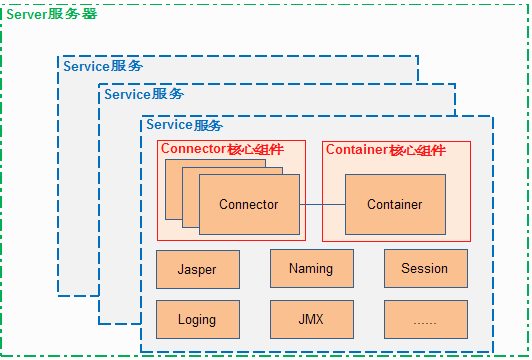
Tomcat 的心脏是两个组件:Connector [kə'nektə(r)] 和 Container [kən'teɪnə],Connector 主要负责对外交流,可以有多个。Container 主要处理 Connector 接受的请求,主要是处理内部事务,只有一个。 Service将Connector 和 Container连接起来,用Lifecycle 接口来控制下面组件的生命周期,
最外层的Server 提供一个接口让其它程序能够访问到这个 Service 集合、同时要维护它所包含的所有 Service 的生命周期,包括如何初始化、如何结束服务、如何找到别人要访问的 Service。
二、Tomcat目录
tomcat
|---bin Tomcat:存放启动和关闭tomcat脚本;
|---confTomcat:存放不同的配置文件(server.xml和web.xml);
|---doc:存放Tomcat文档;
|---lib/japser/common:存放Tomcat运行需要的库文件(JARS);
|---logs:存放Tomcat执行时的LOG文件;
|---src:存放Tomcat的源代码;
|---webapps:Tomcat的主要Web发布目录(包括应用程序示例);
|---work:存放jsp编译后产生的class文件;
三、server.xml配置简介:
下面讲述这个文件中的基本配置信息,更具体的配置信息请参考tomcat的文档:
server: 1、port 指定一个端口,这个端口负责监听关闭tomcat的请求
2、shutdown 指定向端口发送的命令字符串
service: 1、name 指定service的名字
Connector (表示客户端和service之间的连接):
1、port 指定服务器端要创建的端口号,并在这个断口监听来自客户端的请求
2、minProcessors 服务器启动时创建的处理请求的线程数
3、maxProcessors 最大可以创建的处理请求的线程数
4、enableLookups 如果为true,则可以通过调用request.getRemoteHost()进行DNS查
询来得到远程客户端的实际主机名,若为false则不进行DNS查询,而是返回其ip地址
5、redirectPort 指定服务器正在处理http请求时收到了一个SSL传输请求后重定向的端口号
6、acceptCount 指定当所有可以使用的处理请求的线程数都被使用时,可以放到处理
队列中的请求数,超过这个数的请求将不予处理
7、connectionTimeout 指定超时的时间数(以毫秒为单位)
Engine(表示指定service中的请求处理机,接收和处理来自Connector的请求):
1、defaultHost 指定缺省的处理请求的主机名,它至少与其中的一个host元素的name属性值是一样的
Context (表示一个web应用程序):
1、docBase 应用程序的路径或者是WAR文件存放的路径
2、path 表示此web应用程序的url的前缀,这样请求的url为http://localhost:8080/path/****
3、reloadable 这个属性非常重要,如果为true,则tomcat会自动检测应用程序的/WEB-INF/lib 和/WEB-INF/classes目录的变化,自动装载新的应用程序,我们可以在不重起tomcat的情况下改变应用程序
host (表示一个虚拟主机):
1、name 指定主机名
2、appBase 应用程序基本目录,即存放应用程序的目录
3、unpackWARs 如果为true,则tomcat会自动将WAR文件解压,否则不解压,直接
从WAR文件中运行应用程序
Logger (表示日志,调试和错误信息):
1、className 指定logger使用的类名,此类必须实现org.apache.catalina.Logger 接口
2、prefix 指定log文件的前缀
3、suffix 指定log文件的后缀
4、timestamp 如果为true,则log文件名中要加入时间,如下例:localhost_log.2001-10-04.txt
Realm (表示存放用户名,密码及role的数据库):
1、className 指定Realm使用的类名,此类必须实现org.apache.catalina.Realm接口
Valve (功能与Logger差不多,其prefix和suffix属性解释和Logger 中的一样):
1、className 指定Valve使用的类名,如用org.apache.catalina.valves.AccessLogValve类可以记录应用程序的访问信息
directory(指定log文件存放的位置):
1、pattern 有两个值,common方式记录远程主机名或ip地址,用户名,日期,第一行请求的字符串,HTTP响应代码,发送的字节数。combined方式比common方式记录的值更多
2.ConcurrentHashMap原理分析
通过分析Hashtable(线程安全)就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对hash表的不同部分进行的修改。ConcurrentHashMap内部使用段(Segment) ['segm(ə)nt]来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。这里“按顺序”是很重要的,否则极有可能出现死锁,在ConcurrentHashMap内部,段数组是final的,并且其成员变量实际上也是final的,但是,仅仅是将数组声明为final的并不保证数组成员也是final的,这需要实现上的保证。这可以确保不会出现死锁,因为获得锁的顺序是固定的。
3.内存溢出和内存泄漏的区别
内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory;比如申请了一个integer,但给它存了long才能存下的数,那就是内存溢出(内存不足)。
内存泄露 memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光(申请到的内存不释放,占据系统内存)。
memory leak会最终会导致out of memory!
4.Java反射机制
Java反射机制是一个反编译的过程.class-->.java。通过反射机制访问java对象的属性,方法,构造方法等;最经典的应用就是jdbc时用过一行代码, Class.forName("com.mysql.jdbc.Driver.class").newInstance();但是那时候只知道那行代码是生成 驱动对象实例,很多开框架都用到反射机制,hibernate、struts都是用反射机制实现的。
5.在springMVC中,controller是单例的,那么当并发请求的时候,怎么处理?
由于只有一个Controller的instance,当多个线程同时调用它的时候,它里面的instance变量就不是线程安全的了,会发生窜数据的问题。、
1、在控制器中不使用实例变量
2、将控制器的作用域从单例改为原型,即在spring配置文件Controller中声明
scope="prototype",每次都创建新的controller
3、在Controller中使用ThreadLocal变量
6.线程池的底层实现原理
worker:工作类,一个worker代表启动了一个线程,它启动后会循环执行workQueue里面的所有任务
workQueue:任务队列,用于存放待执行的任务
keepAliveTime:线程活动保持时间,线程池的工作线程空闲后,保持存活的时间。
线程池原理:预先启动一些线程,线程无限循环从任务队列中获取一个任务进行执行,直到线程池被关闭。如果某个线程因为执行某个任务发生异常而终止,那么重新创建一个新的线程而已。如此反复。
7.Java内存机制哪里不会出现内存溢出
五大内存区域,除了程序计数器,其它的都会出现溢出:包括Java虚拟机栈与本地方法栈,方法区内存溢出,堆内存的溢出
8.ArrayList和LinkedList的大致区别
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
9.关于Java的锁分类
公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
10.BIO和NIO的区别
BIO(Blocking IO)阻塞IO
NIO(Non-Blocking IO)非阻塞IO
共同点:两者都是同步操作。即必须先进行IO操作后才能进行下一步操作。
不同点:BIO多线程对某资源进行IO操作时会出现阻塞,即一个线程进行IO操作完才会通知另外的IO操作线程,必须等待。
NIO多线程对某资源进行IO操作时会把资源先操作至内存缓冲区。然后询问是否IO操作就绪,是则进行IO操作,否则进行下一步操作,然后不断的轮询是否IO操作就绪,直到iIO操作就绪后进行相关操作。
11.JAVA中同步和异步的区别
ArrayList 和HashMap是异步,Vector和HashTable是同步,这里同步是线程安全的,异步不是线程安全的。线程安全的并发时会在程序上加上锁,而其它非线程安全的则不会。
12.缓存一致性
缓存一致性机制整体来说,是当某块CPU对缓存中的数据进行操作了之后,就通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取。
java语言中的volatile关键字就干了一件这样的事。使用volatile修饰的共享变量,当有线程修改了他的值的时候,他会立即强制将修改的值写回到主存,并通知其他使用该共享变量的线程:他们的缓存区中关于此变量的值已经失效。请重新从主存中读取。 但是volatile仅仅保证了可见性,关于i++的操作是原子性的操作,这个volatile保证不了。
13.Java堆的插入和删除的过程
⑴最大堆的插入
由于需要维持完全二叉树的形态,需要先将要插入的结点x放在最底层的最右边,插入后满 足完全二叉树的特点;然后把x依次向上调整到合适位置满足堆的性质, 时间:O(logn)。 “结点上浮”
⑵删除
操作原理是:当删除节点的数值时,原来的位置就会出现一个孔,填充这个孔的方法就是, 把最后的叶子的值赋给该孔并下调到合适位置,最后把该叶子删除。“结点下沉”
14.Java IO 中涉及到的设计模式
装饰者模式:动态地将责任附加到对象上,若要扩展功能,装饰者模提供了比继承更有弹性的替代方案。
通俗的解释:装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例。例如:根据inputstream和outputstream来扩展出很多其它的类。
15.CopyOnWriteArrayList的工作原理
其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。CopyOnWriteArrayList对add()操作还是加锁的,适合与读多写少的场合
16.实践中如何实现SQL的优化
① SQL语句及索引的优化
② 数据库表结构的优化
③ 系统配置的优化
④ 硬件的优化
具体优化的内容可以参考自己写的笔记。
17. 什么情况下设置了索引但无法使用
① 以“%”开头的LIKE语句,模糊匹配
② OR语句前后没有同时使用索引
③ 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型)
18.索引的底层实现原理和优化
B+树,经过优化的B+树
主要是在所有的叶子结点中增加了指向下一个叶子节点的指针,因此InnoDB建议为大部分表使用默认自增的主键作为主索引。
19.如何设计一个高并发的系统
① 数据库的优化,包括合理的事务隔离级别、SQL语句优化、索引的优化
② 使用缓存,尽量减少数据库 IO
③ 分布式数据库、分布式缓存
④ 服务器的负载均衡
20.锁的优化策略
① 读写分离
② 分段加锁
③ 减少锁持有的时间
④ 多个线程尽量以相同的顺序去获取资源