本章要点
- 你可以为类、方法、字段、局部变量、参数、表达式、类型参数以及各种类型定义添加注解。
- 对于表达式和类型,注解跟在被注解的条目之后
- 注解的形式有: @Annotation、 @Annotation(value) 或 @Annotation(namel = value, ...)
- @volatitle、 @transient、 @strictfp 和 @native 分别生成等效的Java修饰符。
- 用@throws来生成与Java兼容的throws规格说明
- @tailrec注解让你教研某个递归函数使用了尾递归优化
- assert函数利用了@elidable注解。你可以选择从Scala程序中移除所有断言。
- 用@deprecated注解来标记已过时的特性。
什么是注解
注解是那些你插入到代码中,以便有工具可以对它们进行处理的标签。工具可以在代码级别运作,也可以处理被编译器加入了注解信息的类文件。
注解的语法和Java一样:
@Test(timeout = 100) def testSomeFeature() { ... }
@Entity class Credentials {
@Id @BeanProperty var username: String = _
@BeanProperty var password: String = _
}
你可以对Scala类使用Java注解。上述示例中的注解除了@BeanProperty外,其他的都来自JUnit和JPA,而这两个Java框架并不知道我们用的是Scala。
Scala特有的注解通常是由Scala编译器或编译器插件处理。Scala注解和Java注解是有区别的:
Java注解并不影响编译器如何将源码翻译成字节码;它们仅仅是往字节码中添加数据,以便外部工具可以利用到它们。而在Scala中,注解可以影响编译过程。例如@BeanPropetry注解将触发getter和setter方法(如果为var的话)的生成。
什么可以被注解
在Scala中,你可以为类、方法、字段、局部变量和参数添加注解
@Entity class Credentials
@Test def testSomeFeature() {}
@BeanProperty var username = _
def doSomething(@NotNull message: String) {}
// 同时添加多个注解
@BeanProperty @Id var username = _
// 给构造器添加注解,需要将注解放置在构造器之前,并加上一对圆括号(注解不带参数的话)
class Credentials @Inject() (var username: String, var password: String)
// 给表达式添加注解,需要在表达式后加上冒号,然后是注解本身
(myMap.get(key): @unchecked) match { ... }
// 为类型参数添加注解
class MyContainer[@specialized T]
// 为实际类型添加注解应放置在类型名称之后
String @cps[Unit]
注解参数
Java注解可以有带名参数:
@Test(timeout = 100, expected = classOf[IOException])
// 如果参数名为value,则该名称可以直接略去。
@Named("creds") var credentials: Credentials = _ // value参数的值为 “creds”
// 注解不带参数,圆括号可以省去
@Entity class Credentials
Java 注解的参数类型只能是:
- 数值型的字面量
- 字符串
- 类字面量
- Java枚举
- 其他注解
- 上述类型的数组(但不能是数组的数组)
Scala注解可以是任何类型,但只有少数几个Scala注解利用了这个增加的灵活性。
注解实现
你可以实现自己的注解,但是更多的是使用Scala和Java提供的注解。
注解必须扩展Annotation特质:
class unchecked extends annotation.Annotation
针对Java特性的注解
- Java修饰符
对于那些不是很常用的Java特性,Scala使用注解,而不是修饰符关键字:
@volatile var done = false // JVM中将成为volatile的字段
@transient var recentLookups = new HashMap[String, String] // 在JVM中将成为transient字段,该字段不会被序列化。
@strictfp def calculate(x: Double) = ...
@native def win32RegKeys(root: Int, path: String): Array[String]
- 标记接口
Scala用注解@cloneable和@remote 而不是 Cloneable和Java.rmi.Remote标记接口来标记可被克隆的和远程的对象。
@cloneable class Employee
对于可序列化的类,你可以用@SerialVersionUID注解来指定序列化版本
@SerialVersionUID(6157032470129070425L)
class Employee extends Person with Serializable
- 受检异常
和Scala不同,Java编译器会跟踪受检异常。如果你从Java代码中调用Scala的方法,其签名应包含那些可能被抛出的受检异常。用@throws注解来生成正确的签名。
class Book {
@throws (classOf[IOException]) def read(filename: String) { ... }
// Java版本为
// void read(String filename) throws IOException
...
}
// 如果没有@throws注解,Java代码将不能捕获该异常
try {
book.read("war-and-peace.txt");
} catch (IOException ex) {
...
}
Java 编译器需要知道read方法可以抛出IOException,否则会拒绝捕获该异常。
- 变长参数
@varargs注解让你可以从Java调用Scala的带有变长参数的方法。
// 默认情况
def process(agrs: String*)
// Scala编译器会把变长参数翻译成序列:
def process(args: Seq[String]) // 这样的方法签名在Java中使用很费劲
// 加上 @varargs
@varargs def process(args: String*)
// 编译器将生成如下java方法
void process(String... args)
- JavaBeans
@BeanProperty注解将会生成JavaBean风格的getter和setter方法。
用于优化的注解
- 尾递归
递归调用有时候能被转化成循环,这样能节约栈空间。
object Util {
def sum(xs: Seq[Int]): BigInt = {
if (xs.isEmpty) 0 else xs.head + sum(xs.tail)
}
...
}
上面的sum方法无法被优化,因为计算过程中最后一步是加法,而不是递归调用。调整后的代码:
def sum2(xs: Seq[Int], partial: BigInt): BigInt = {
if (xs.isEmpty) partial else sum2(xs.tail, xs.head + partial)
}
Scala编译器会自动对sum2应用“尾递归”优化。如果你调用sum(1 to 1000000) 将会发生一个栈溢出错误。不过sum2(1 to 1000000, 0) 将会得到正确的结果。
尽管Scala编译器会尝试使用尾递归优化,但有时候某些不太明显的原因会造成它无法这样做。如果你想编译器无法进行优化时报错,则应该给你的方法加上@tailrec注解。
注意上面的方法是在Object中定义的,如果是在class中呢:
class Util {
import scala.annotation._
@tailrec def sum2(xs: Seq[Int], partial: BigInt): BigInt = {
if (xs.isEmpty) partial else sum2(xs.tail, xs.head + partial)
}
...
}
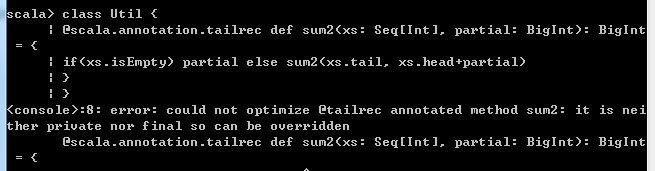
这种情况下,你可以将方法挪到对象中,或者将它声明为private或final。
**说明: **对于消除递归,一个更加通用的机制叫做“蹦床”。蹦床的实现会将执行一个循环,不停的调用函数。每个函数都返回下一个将被调用的函数。尾递归在这里是一个特例,每个函数都返回它自己。Scala有一个名为TailCalls的工具对象,帮助我们轻松实现蹦床。
import scala.util.control.TailCalls._
def evenLength(xs: Seq[Int]): TailRec[Boolean] = {
if(xs.isEmpty) done(true) else tailcall(oddLength(xs.tail))
}
def oddLength(xs: Seq[Int]): TailRec[Boolean] = {
if(xs.isEmpty) done(false) else tailcall(evenLength(xs.tail))
}
// 获得TailRec对象获取最终结果,可以用result方法
evenLength(1 to 1000000).result
2 跳转表生成与内联
在C++或Java中,switch语句通常被编译成跳转表,用于多种情况的判断,比if/else方便高效。Scala也会尝试对匹配语句生成跳转表,使用@switch注解。
(n @switch) match {
case 0 => "Zero"
case 1 => "One"
case _ => "?"
}
另一个常见的优化方法是使用@inline来进行内联:用函数体替换函数调用,这与C++或Java的inline函数相同。 而@noinline来告诉编译器不要内联。
- 可省略方法
@elidable注解给那些可以在生产代码中移除的方法打上标记。
@elidable(500) deg dump(props: Map[String, String]) = { ... }
使用 scalac -Xelide-below 800 myprog.scala 则上述方法代码不会被生成。
- 基本类型的特殊化
打包和解包基本类型的值是不高效的,但是在泛型代码中很常见。
def allDifferent[T](x: T, y: T, z: T) = x != y && x != x && y != z
当你调用allDifferent(3,4,5) 则参数的类型为java.lang.Integer。你可以重载该版本,指定具体的类型,你也可以让编译器自动生成这些方法,使用@specialized注解:
def allDifferent[@specialized T](x: T, y: T, z: T) = ...
// 你也可以将特化限定在某几个可选类型的子集
def allDifferent[@specialized(Long, Double) T](x: T, y: T, z: T) = ...
用于错误和警告的注解
如果给特性加上@deprecated注解,则每当编译器遇到这个特性的使用时都会生成一个警告信息。
@deprecated(message = "Use factorial(n: BigInt) instead")
def factorial(n: Int): Int = ...
@implicitNotFound注解用于某个隐士参数不存在的时候生成有意义的错误提示。
@unchecked注解用于匹配不完整时取消警告信息:
(lst: @unchecked) match {
case head :: tail => ...
}
编译器不会报告说没有给出Nil选项。但是当lst是Nil的时候还是会抛出异常。