*案例:抓取 http://www.tjcn.org 中国统计信息网上前50页(每页包含20个市的数据)的1000个地区的GDP数据。
使用stata版本为 stata13,与12版本和14版本都不兼容。本文do-file及相关文件 链接:https://pan.baidu.com/s/1smVkcUh 密码:40uq
初学stata爬虫,见网络上还未有详细的案例,此类培训费用也较高,特分享此篇案例,仅为个人经验的总结,与诸君共享。学无止境,相信还有更好的处理命令和方法,欢迎指教。
首先对于网页的数据结构有一定的要求,要求数据在网页中排布的规律性较强,方便进行抓取,如案例网站中,每个地区就是一份公报,每份公报的格式大同小异,基本开篇都有GDP数据,还比较规律。因此就用此网站作为案例尝试:
Tips:杂乱无章的网页也不是不能处理,只是处理起来难度较大而已,只要掌握了基本原理,再去处理复杂网页数据相信也不是什么难事。

/*先观察网站上公报每一页对应的网址链接变化规律,一般是最后的编号有规律变化,一个数字对应一页,将鼠标放在页数数字上(不用点击),在浏览器左下角便会显示相应页面的链接,如下:可以看到网址的后段 list_5_1对应第一页,list_5_2对应第二页,依次类推直到最后一页*/
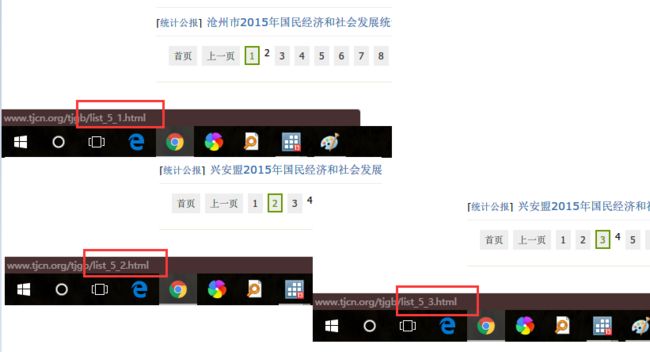
*http://www.tjcn.org/tjgb/list_5_1.html
* http://www.tjcn.org/tjgb/list_5_2.html
*.......................................
* http://www.tjcn.org/tjgb/list_5_50.html,后面更多不在这举例。
以上我们就得到了翻页链接,看似没有什么实质性的内容。但是,在这一共50个页面中,每页中都有20份地区公报,点击即可进入查看,所以这50个翻页链接中实际上更包含了50*20共1000个统计公报的链接,而这1000个链接对我们来说就很重要了,因为我们最终需要从这1000个链接分别所对应的页面中抓取1000个地区的统计公报信息进行分析。
依上,我们的抓取将分为两轮:第一轮是抓取50个翻页链接所指向的50个网页的网页元素(其中就含有50*20个公报的链接地址,需要提取处理)。第二轮则是在获取了1000个公报的链接后,分别抓取1000个公报所在网页的元素信息(耗时较长,约30mins)。
(Tips:为了两轮处理的方便,建议新建两个文件夹分别储存两轮抓取的文本,本例在 e盘新建文件夹 1 和 2)
有了翻页规律之后,我们可以开始第一轮的抓取,本轮抓取获得的是共50个页面的网页元素,每页的元素中都包含了20份公报链接。采用 forvalues ( = forv ) 循环语句命令,写法如下:注意字母 i ,这里表示赋的一个值,这个值范围是从1-50,中间间隔是1。“copy + 网页链接 +保存位置” 可以抓取该网页元素,网页链接的最后根据我们开始发现的页面变化规律设置其随 i 值变化,copy后保存到e盘的1文件夹,分别命名为temp1.txt—temp50.txt。等待片刻便可完成抓取。

我们首先来看如何处理抓取的第1页的信息,从中提取出20份公报的链接,后面再同时处理50个页面,提取1000个链接。
在浏览器中打开第1页,右键点击空白处,查看网页源代码,stata抓取的信息实际上就是网页的源代码,我们就是要用源代码中寻找指向每个公报所在的次级网页的链接。寻找的办法很简单:寻找与次级网页title有关的关键词(Note:这些关键词对我们马上提取链接还很有帮助),看关键词附近有没有网页地址格式的短链接(一般以.html结尾),一般会是彩色,如图中蓝色部分。如果按照我们的分析没错,那么该网站的主链接加上这个短链接一定能直接打开次级网页,试试在浏览器地址栏直接输入www.tjcn.org/tjgb/201606/32971.html,看看能否打开《拉萨市015年国民经济和社会发展统计公报》,经尝试没有问题。


OK,既然我们知道了短链接都隐藏在这里,下面便可以将其导入 stata 中进行提取,同样先处理第1页,后面再同时处理。
使用infix命令将存储有网页源代码的txt文本文档导入stata,让网页源代码在stata中以1个变量 v,n行的格式显示,可以把每一行看作一个case便于理解,与我们在浏览器中查看源代码时的格式相同,1-20000指的是对源代码每一行最多读取20000个字符,可以设置大一点没问题,保证每一行都能被完整读取。
format 命令调整下stata中的显示格式,让其显示200个字符宽度,方便我们查看。
如果变量 v 的case中含有引号中的内容我们就将其keep,这里用到 index 指标函数,将括号中的内容作为stata识别保留与否的指标。
split 切割命令,以后面括号中的内容为标准对文本进行切割。第一个需要注意的是切割之后,括号中作为切割线的引号内部分会被删除。例如,“拉萨市2015年”,若以 “市” 字作为分割线,则只会得到两个新变量:“拉萨”、“2015年”,第二次切割同理。此外还需要注意的是括号引用部分(`"xxx "')双层引号表示绝对引用的意思,因为有些作为分割线的内容本身含有引号,为了避免stata出错,使用双层引号的绝对引用,当然,如果作为分割线的内容中不含引号,直接使用单层引号("xxx")即可。
切割完之后就得到了20个次级网页的短链,加上主链之后,得到20个公报的链接,命名为新变量purl

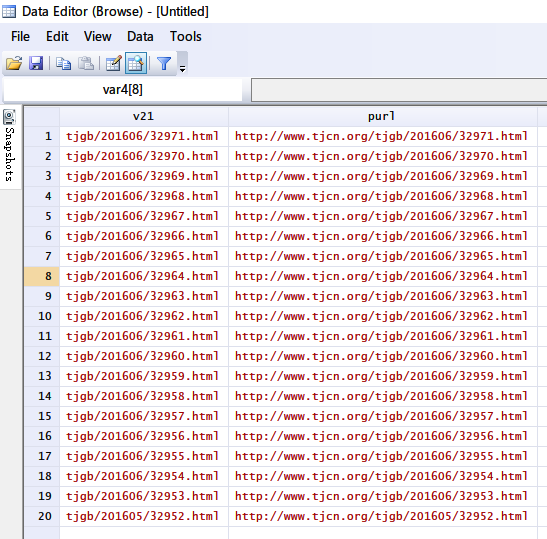
Ok,到此我们处理完了第1页的源代码,获得了20个我们想要的次级网页链接。
实际上每页的源代码都适用同样的提取处理规则,因此我们只需要将同样的命令对每个页面的源代码都 run 一遍,就能得到50*20共1000个公报的链接了。但是我们不想跑二十遍命令,我们想要一次将50个页面一起处理掉。
而50页的源代码分散在50个txt文档中,因此只要将50个txt文档合并不就好了吗,如何合并呢?这里使用一种简单方法,需要调用计算机 dos 命令:
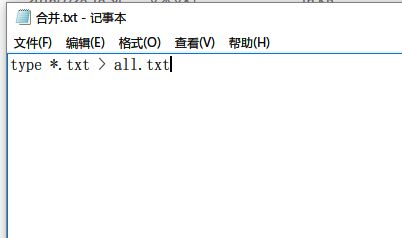
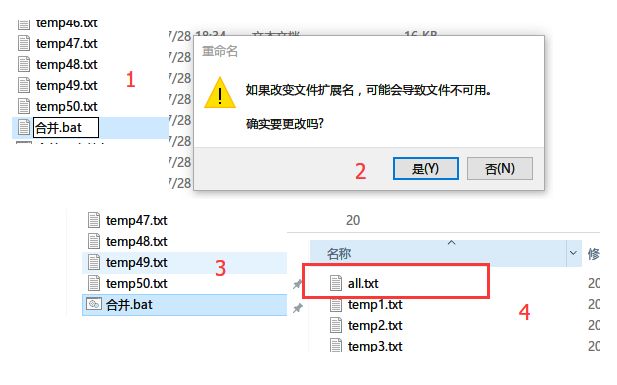
用记事本编写 .bat 批处理文件。先右键新建一个 txt 文本文档,输入type *.txt > all.txt,表示将任意 txt 类型的文件全部合并成一个 all.txt,注意type 和 *之间有空格。写完保存。然后将该 txt 文档的格式后缀 txt 改为 bat,在弹出的对话框中选 “是”。文件图标会变成两个小齿轮一样的就对了,下图所示。
如要合并文件,只需要双击 “合并.bat” 文件即可在 dos 中执行写好的合并命令,黑色dos窗口闪现一下,就会发现文件夹中已经多了一个合并好的 all.txt,可以用记事本直接打开查看。效果是将50个txt 按顺序上下拼接,可以理解成 stata 的 append。【这个bat小文件我们后面还会用到】
注意:合并用的 bat 文件必须与待处理的50个 txt 文档位于同一目录下,否则没有执行结果。
既然得到了50页的所有源代码,那么我们只需要以同样的方式将 all.txt 读进 stata ,用刚才处理第一页的命令再跑一遍就好了。命令与上面一致,唯一区别只是将读入的文件改为了 all.txt,运行一下即可得到1000个地区公报的链接。

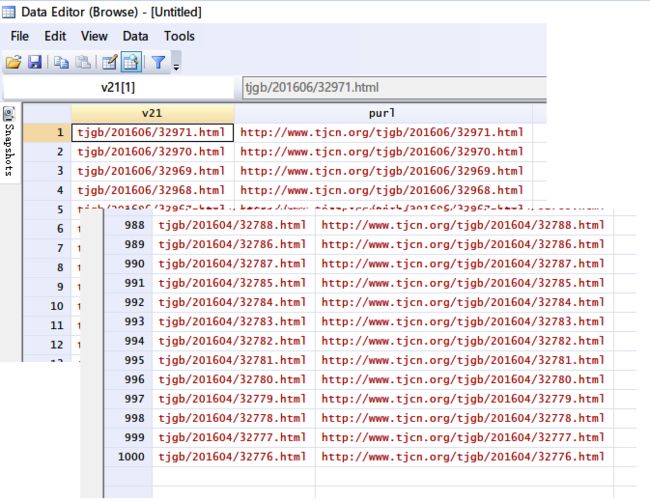
至此,我们已经完成了第一轮抓取及相关工作,等待开始第二轮抓取,即根据得到的1000个公报的链接,去抓取1000个公报所在网页的源代码。
接下篇:详解 stata 爬虫抓取网页上的数据 part 2