

MegaWise x Mapbox
周四晚 ZILLIZ 与 Mapbox 联手的《亿级地理信息数据实时交互》线上直播圆满结束。直播中干货满满,不仅仅有顾钧老师倾力的技术分享,更有与群友们丰富的互动问答。
哪怕你错过了本次直播也无需担心,我们为大家准备了直播回顾。此外,我们首次尝试将整个直播转化为文字实录版本,从老师的技术讲解, 到最后的问答环节内容,每一个细节都清晰呈现。无论你在地铁上,还是办公室中,都可以直接而快速得获取干货信息。
•如果你想回看直播:点击这里回顾线上直播:https://live.vhall.com/room/watch/993515689?invite=&from=singlemessage&isappinstalled=0
•如果你想获得直播 PPT:请添加微信zilliz-tech 进入直播交流群领取
•想直接看文字实录,就在下方哦!
分享嘉宾介绍
本次技术大餐的主讲人,是来自面向海量时空数据的可视化交互分析平台 ZILLIZ 首席架构师顾钧老师,他本人也是一枚忠实的 Mapbox 开发者。

顾钧 - ZILLIZ 首席架构师
毕业于北京大学,15年数据库相关工作经验。目前在 ZILLIZ 从事异构众核数据分析引擎的产品化工作。加入 ZILLIZ 之前,曾就职于 IBM,Morgan Stanley,华为等跨国公司。
文字实录
Max:今天非常开心能够在特殊的时期跟大家来做分享。然后我们今天的分享的主题是在 Mapbox 地图上进行一个亿级的大数据实时交互,然后现在就先有请我们的顾老师,如果大家没有问题能看清的话,有请顾老师来给大家做正式的讲解。
注:以下均为顾老师分享
顾钧老师:今天非常高兴能够有机会跟大家一起共分享我们这一套关于时空数据分析的一个工具集,然后在这个过程当中,我会跟大家简单介绍一下我们的技术栈是什么样子的,我们的方案的架构是什么样子的,然后我们 ZILLIZ 的这一套时空大数据分析的一个现实的展示是什么样子的?那么今天非常的高兴,本来因为之前是约了去 Mapbox 的办公室跟大家做这样一个分享,但在特殊情况下,我们现在在稍微简单一点的会议室跟大家做这样的分享。
首先我跟大家简单介绍一下我们 ZILLIZ 公司,我们是一家科技类的创业公司,我们聚焦在研发一个新一代的数据科学平台,我们现在主要有两个开源的项目。就主要我们这样的一种科技公司,在现在这个时代的话,我们都是通过一种开源的方式去运作我们的项目的。我们的一个项目是针对于A.I.领域的一个向量搜索引擎叫做Milvus,也是在去年10月份上开源的。然后另一块也就是我今天要给大家介绍我们针对时空大数据分析的一套解决方案,它也会在我们今年4月份正式的去开源,所以如果大家听完今天的讲解,对这个东西非常感兴趣的话,是希望大家最后扫我们的二维码,关注我们的公众号,然后持续跟进我们这个项目的进度。
3:30——为什么要做这样一个平台
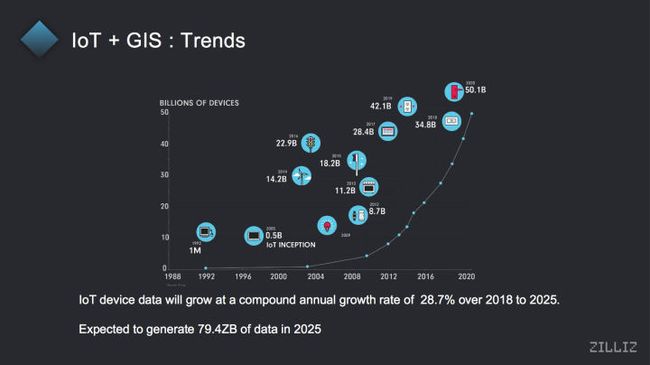
对,首先为什么我们要做这样一个所谓针对海量的时空数据的分析的平台?其实这一页最初我们准备这一页的话,都是这是非常经典的一套数据,当时是在一个硬盘厂商叫做希捷,他请了 IDC(注:全球著名的科技市场研究机构)帮他做的一套咨询报告,当时是叫做 Data age2025 那篇报告当中,他去描绘了全球数据圈的长期的愿景,包括他会有各种门类的数据,它会有一些什么样的增长。其中有提到说像这种 IOT 的设备,包括这些智能传感器和这些时空相关的信息,在未来是会有一个比较高速的成长。当从咨询公司角度来说,他们给出的一个复合增长率在年化是有28.7%,到2025年的话可以到达将近80GB,但这些数字原来我们也只是就是说我个人在做这些东西的研究的时候,也就是引用这些咨询报告,然后其实并没有一个特别感性的概念。
像现在我们这种特殊时期的情况下,其实对这种时空数据的理解,我现在突然之间有点开始明白为什么数据这么的重要,然后为什么像传统的比较粗的讲,按照区域或者按照大类的方式去进行数据分析,可能在这个时代已经有点不够用的一个原因。就像我们这次的疫情,你可以看到说大家都休息,大家都怎么说还在家里工作,或者说尽量避免出门之后对整个社会的影响,其实是怎么讲,肉眼可见,小朋友都能看得到的。因为怎么说人类社会的发展本质上就是人和人之间的沟通和交流和流动所造成的一个结果,在这个过程当中其实就产生了大量的数据,而且这些数据都是会和时间、地理信息这些属性相关的。在过去我们可能并没有觉得它有那么的重要。但是像现在,我们要知道有一些人他患了新冠肺炎的话,你会去追踪他过去的路径,然后去分析,所有和他会有交集的人,其实都是一些和时空、时间、空间有关系的一些信息,再进行分析。
所以针对这样一种我们认为新一代的这种 IOT 类的时空数据分析类的分析平台,他其实会需要具备的一些关键的功能特性。一个是我们刚才反复来讲是时空的,一个是地理信息的空间上的概念,一个是时间上的概念的混合的一种数据分析模式。然后另外一个第 2 点很重要的就是它的数据量会非常的巨大。通常来讲我们人类正常生活它所产生的这些时空数据,稍后我会给大家展示一个案例当中,我们是下载了是一个深圳市政府提供的一个开放数据集,它是某一天的深圳市的运营车辆,它运行的过程当中所上报的 GPS 的轨迹的信息,你可以看到在那个案例当中,一天他就有 2000 将近 800 万条的时空相关的数据。(注:这个案例在之后的*37:00——Demo 4 深圳运营车辆位置分析* )
第 3 个重要特点就是它需要一种实时的交互性。因为数据量非常巨大的过程当中,你需要一种当你还不知道怎么去发现这其中的规则的时候,因为当如果我们知道它能够说出一个什么样的故事,它背后蕴含着一种什么样的规则的时候,通常都是我们已经把模型建好了,或者说有一些基本的思路去构建这些分析模型之后,我们才有可能说非常的批量化的去处理这些东西,然后期待得到一些阅读。这些分析报告,在之前最初始的分析阶段,其实大量的会采用一种交互式的手段,那么它的实时性就会变得非常重要。最终的最后一点是它的成本上的一个经济性,因为其实如果不计成本的话,很多的分析也许从技术上是可行的,但是必须要考虑到一个说这个技术它所带来的业务的价值究竟是什么样子的,包括他所付出的成本是什么样子的,如果这东西没有成本优势的话,基本来说也是不太可能被用户所采用。
好的,那么在接下来我先跟大家分享一下我们一个简单的示例,因为我们今天的讲解主要会是通过 PPT 和我们的前端的界面去做一些结合的讲解,在首先介绍一下这一个演示其实是一个 Uber 开放的纽约出租车的一个公开数据集,当然它最多的整个数据集应该是有 11 亿条,当然我们今天的 demo 的机器并没有那么高的配置,所以我们是选取了一个月 50 万个数据点的一个示例,后面另外一个比较大型的示例是一个 2700 万,
10:50——采用的技术方案
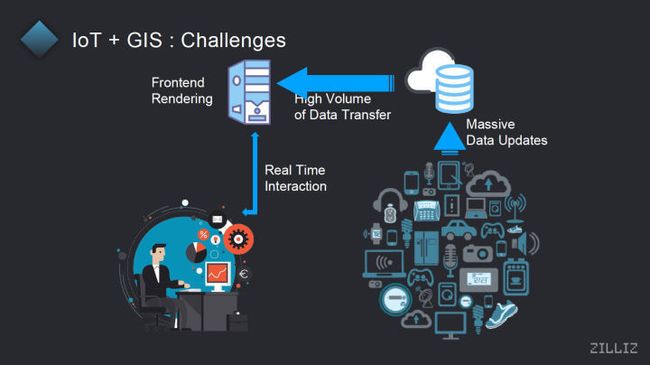
那么我们这一套分析的一个方案,它所采用的一个技术,就是说我们看到的挑战是说,因为海量的这些智能的传感器也好,智能的移动的终端也好,他都会产生大量的时空的数据,所以说有什么问题吗?会有,因为现在我们所使用到的智能传感器和移动设备越来越多,所以说首先一个数据量会非常的巨大,那么在这个数据量的前提下,像我们现在的方案、未来的方案的话,都是会首先针对类似 Spark 这样的一个大数据的分析处理平台,去做一个时空数据的存储,因为从我们了解的过程当中,我们也发现说,其实很多用户还是把一些时空数据存储在 Spark 这样的集群当中,然后我们会把我们的整个分析的套件作为一个类似于 SparkSQL 那样的扩展。
首先我们会提供一些 OpenGIS 的一些 API。在 OpenGIS 下这种开放的 API 做的最好,相对来说是目前的 postGIS 这一套标准。这 postGIS 它主要还是和 postgreSQL 绑定的比较深,你如果要使用 postGIS 比较良好的一个实现的话,你必须要使用 postgreSQL 这个数据库,但其实 postgreSQL 数据库可能本身它并不是能够支撑到海量数据的这样的一种状态,所以我们首先会去把 postGIS 这一套 API,能够实现在 Spark 这样的一种针对大数据的一个集群上面,然后其次我们会提供一种所谓服务器端渲染的一种方式,因为像一些传统的时空数据分析的平台的话,他们可能会更多的使用 WebGL 的方式,去把这些 GIS 数据露到前端的浏览器当中,然后使用 WebGL 去进行一些渲染和展示,它的好处就是他对于后端服务器的压力相对会小一点,因为你大量的渲染的一些操作都是在你的浏览器当中发生的。
但是它的一个相对来说的劣势,就是说,因为所有的数据要传输到你的浏览器,再去进行 WebGL 的这些渲染的话,首先它数据的传输量会比较大,所以他的如果你分析的数据量比较大的话,那么它的初始的传输的延迟会有点高。另一方面也是 WebGL 的话,它会对于浏览器的内存消耗有一个比较大的一个可能会有比较大的影响,尤其你需要特别大的情况下,所以如果是在一些,比如说你想通过 iPad,或者想通过手机的浏览器,其实相对来说轻量级的移动端的浏览器去访问他的话,可能会有一些困难。
所以我们是通过一种服务器端渲染的方式,首先我们在渲染服务器上面把所有的那些技术的交互的、API 的查询结果再渲染成一张图片,它可以是个点图,也可以是个热力图,然后叠加在我们后端所使用的一个类似于像 Mapbox 这样的地图上面,相当于在 map 上叠加一个图层的方式去给用户展示这样的一种查询的一个结果。
16:00——服务器端渲染与传统渲染方式的区别
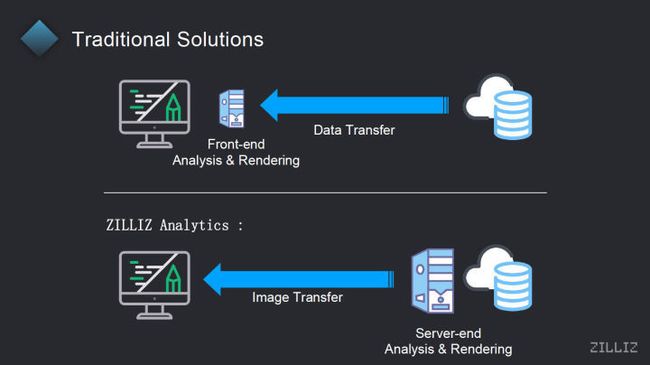
所以对这就是我们刚才提到的我们的这种方式和传统的基于前端的 webGL 的方式的一个区别,就是传统方式当中,他传的是数据从 server 端传到前端,然后在前端去进行渲染和计算分析。在我们的这套模式下面,我们传的主要是图片,就是我们其实是在后台的服务器上进行了分析和渲染之后,将图片再发送到前端的浏览器,这样的话对浏览器的资源的要求和开销就会比较小,然后不单单是在 PC 的浏览器上可以去进行访问,在 iPad 或者说在一些手机的浏览器上面也是可以去展示,因为它毕竟只是一个图片,所以在这种情况下,这套架构其实是可以去支撑一些移动端的应用场景。
17:00——GPU加速引擎
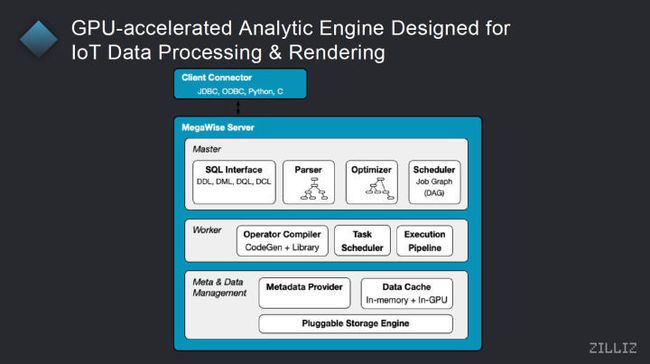
所以在这边的话跟大家再具体的介绍一下,我们的后端的 GPU 加速的一个 GIS 分析引擎,它是什么样子的?因为刚才提到说像这些时空数据因为量比较大,所以说他其实在大量的计算的时候,之后它是一种其实列式的计算和处理,是会对他有更好的一个性能的表现和一个加速的效果。而列式的一些操作其实是比较适合 GPU 这样一种硬件去进行处理的。
通过 GPU 加速的选项,主要也是因为我们在 GPU 加速异构计算的加速,大数据分析这个领域有比较多的一些积累。这边是一个例子,就是我们的一个 GPU 加速的引擎,MegaWise 的整体架构,因为怎么讲传统的数据仓库,因为它只使用到了 CPU 一种计算资源,所以当然数据仓库本身就是一个相对来说比较复杂的系统,但 GPU 加速的数据仓库其实或者说数据分析平台,它会在相比单纯只使用 CPU 的数据分析的方案会带来更多的复杂性,主要是因为 CPU 和 GPU 的一些高性能算法上的一些不同,所以造成了 SQL 的一些解析器和分析器,包括它的优化器的设计,都会需要有一些针对不同的平台的处理器的一些相应的优化,包括整个的调度器,在 CPU 当中所就习以为常或者说已经形成一定共识的一个执行的路径,可能在 GPU 的场景下并不是一个最优的方式!所以其实在这一部分,我们是做了比较多的工作在上面,包括在一些动态运行时的编译,包括一些任务的调度器等等,也都会和传统的一些 CPU 的引擎会有些不一样,所以这也是为什么我们的项目在4月份开源之后会先做一个 CPU 层面的一个时空数据分析的一个库,然后在未来在持续的把 GPU 的能力加到里面。
20:20——前端能提供的功能(如数据可视化的组件)
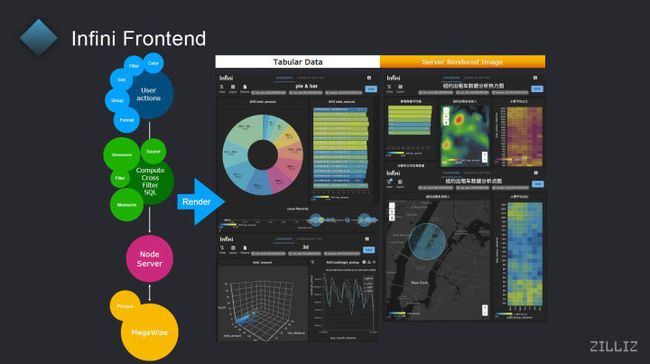
对,这个家好可以大家看一下,说因为一般任何一个数据分析的后端的话,其实都会比较的抽象,比较难向用户去解释它究竟是一个能够达到一个什么样的效果。所以其实在我们的例子当中是有一些前端,我们的自己的前端去搭配了数据分析的引擎,能够提供一些什么样的功能,基本上一些主流的数据可视化的组件,在我们当中都是有提供的,包括这些像这种饼图 chart,包括一些热力图,一些堆垛的图,包括三维空间,包括这种允许用户自行去编辑一个区域,进行区域过滤的功能,在我们的前端当中都是有提供的。
21:30 ——如何在Mapbox上叠加图层
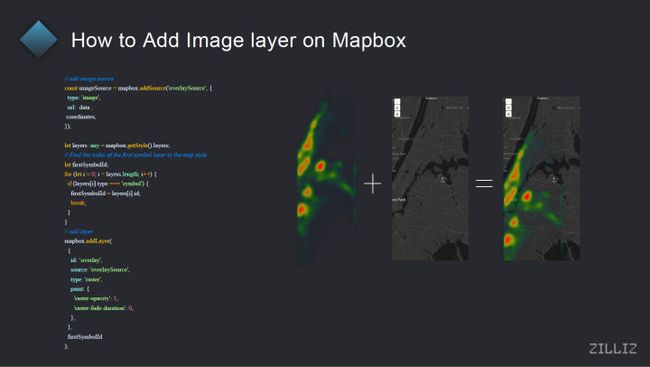
对这一部分其实主要介绍说我们是,因为刚才有讲到说,其实我们的分析结果,比如说这里就是我们的分析结果,一张热力它其实是在服务器端渲染生成,然后发送到用户这边的,其实我们是需要把它叠加在 Mapbox 的地图上面,然后叠加在地图上面,最终形成一个给用户的一个可视化的结果。在用户看到的是一个在地图上还有热力信息的图,所以在这边其实就是在 Mapbox 当中,因为 Mapbox 的 API 提供的比较好,我们是比较容易的可以去把一些图层添加在 Mapbox 本身的地图上面的。
22:30 ——最近的工作

所以这是我们现在正在在这个项目上做的一些工作,包括我们的开源的前端的交互的工具上面,首先也是在把整个的框架做得更好,然后再增加一些新的图表的类型,包括我们也是希望说能够因为业界其实已经有一些比较成熟的比较优秀的图表库,我们希望也是能够做成一些可插拔的一种模式,去容易的去集成别人,也可以很容易地被别人去继承。包括这一部分是可能相对来说我们比较特殊的,我们会有一个渲染引擎,因为他是在服务器端做渲染,所以它多了这么一个部件。
另外一块就是我们的整个的开源的时空数据的一个分析和渲染的部分,我们把它叫做 Arctern Project,它是一个基于列的空间信息的一个分析的平台,然后我们会同时在 CPU 的 GPU 上去做计算,同时可以去支持 CPU 的计算,也可以去支持 CPU 加 GPU 混合的计算。包括我们的渲染引擎的话,其实渲染这一部分工作量,它的负载量其实并不是特别的大,所以它是可以在 CPU 上也相对来说比较快的去完成的,当然 GPU 去渲染图片的话是会更擅长一些。
然后我们是会去和因为是这样,就说发在 3.0 开始,它会逐渐的去往 GPU 的加速和使用 GPU 的调度框架那边去做一些转型,或者说做一些尝试。所以我们的 GPU 的部分也会去尝试和整合到 Spark 3.0 新的 GPU 的调度框架里面。当然我们理解说可能 Spark 3.0 现在还只是非常早期的一个阶段,可能绝大多数用户都还是在用 Spark 2.4、2.6 这些版本,那么在这种情况下,其实可能更多的这也是为什么我们想要先把 CPU 的版本能够做出来,因为这样的话在用户的环境当中能够最快的能够使用起来,包括我们也在尝试做一些 Python pandas 的 binding,你这样的话可以大幅的降低用户去使用我们分析 SDK 的一个成本。
因为就是说一般来说可视化交互的时候,你可能需要一个前端去做一些交互,但是也其实会有很多情况下,你并不想要做一个数据可视化,你可能只是简单的想要得到一个结果。这个时候我们去和 Python pandas 做一个 binding,就比较容易被用户去调用,可能他在自己的就在 note book 当中就可以去做一些数据的分析,去利用我们这个平台好。主要的PPT部分在这边,然后稍等一下,让我再回到我刚才那个地方看一下。现在网络状况有所改善。
26:30——Demo 1 纽约出租车数据
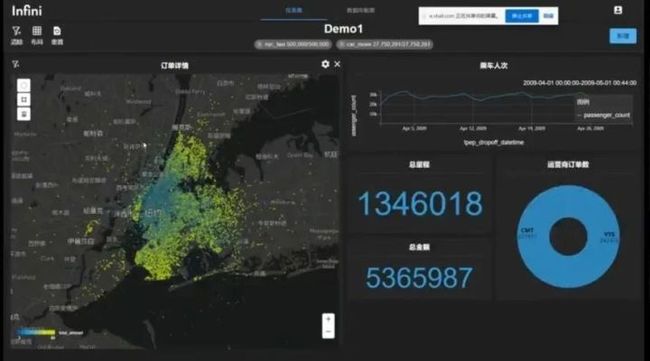
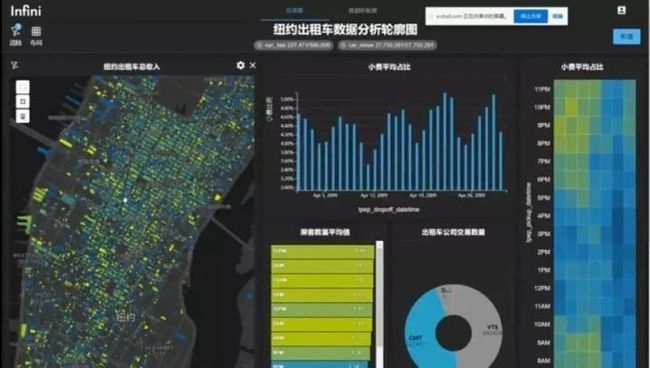
先让我打开我的第 1 个 demo,首先这是一个基于 web 的前端,然后我们刚才也讲到说我们的第 1 个示例当中,它其实使用的是 Uber 开源的纽约出租车的一个开源数据,在当中我们是截取了一个月,也就是 2009 年 4 月这一整个月的 50 万条记录,我们其实在这张图当中,它就是一个服务器端渲染的图片。你可以看到其实他是在 Mapbox 的图层上叠加了我们这个服务器渲染出来的这个点图的图层,然后虽然可能你觉得说一个渲染出来的图片叠加上去可能交互性会有影响,但其实你可以看到我们在每一个点上,其实它也是可以做弹窗,然后显示着每一个点的信息。然后因为你可以看到说 50 万个点,其实如果我们在前端做危机而渲染的话,其实对于浏览器的压力还是比较大的,但是因为是在服务器端做渲染,所以说它的整个的流畅度可以保证到比较好的状态。所以你可以看到说当我们去做这些缩放的时候,其实在 50 万点的级别上面,它是要比 WebGL 的效果会有比较明显的一个优势。包括我们可以做一些区域的过滤,这些绘制区域的过滤。包括在整个前端当中。
刚才我还忘提了这一点,我们的整个的前端的图表当中是做了一个是可以联动去做交互。比如说在这个示例当中,我选取的数据,其实最左边最主要的部分是可视化的 GIS 的一个结果,在右边其实我们就会有一些线图饼图,包括这些汇总的数字,其实这些线图上都是可以去交互。左边的服务器端渲染图片,它是会重新去做渲染,然后所有的当然右边的这些东西也都会去做相应的一些刷新,然后我们也可以去做时间窗口的一些过滤。现在的话,我选择的时间窗口就是 4 月 1 号到 2 号那一天,然后做一些时间窗口的播放的时候,你就可以看到所有的区域都会去做一个协同的更新,所以在这个情况下,就是说在服务器端渲染去分析这种相对来说海量的这些信息的情况下,它的整个的性能就会比较的有优势。
29:40——Demo 2 纽约出租车数据
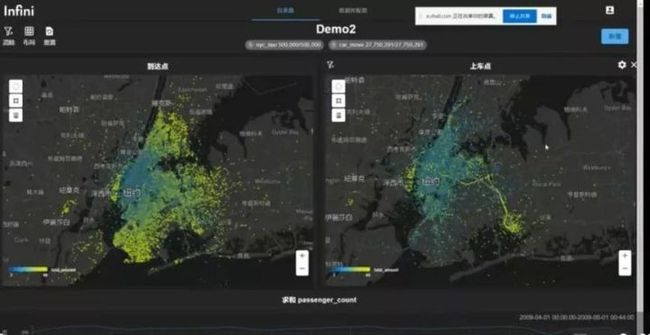
好的,让我来打开第2个 demo,其实在 demo 当中和刚才用的数据是一样的,也是 50 万条的一个纽约出租车的信息,他也是在 2009 年 4 月的一个信息,它只是说不同的维度,就是在这边是以到达的地点为 GIS 的坐标去显示的数据,然后在右边的图上我是以出发的这个位置为坐标去显示的 GIS 的信息,越偏向黄色的部分,就是说明出租车的订单的金额就越高,越偏向蓝色,就是说它金额越低,所以为什么同时有这两个图,因为你从出发点和从到达点的角度去看,其实它是会两种不同的一个数据的分布的情况,在很多情况下我知道说大家可能有一些那种连线图,它是会把起点和终点连接在一起,然后同时集中显示一张图片上,但是在那种情况下,其实尤其当你数据量特别大的情况下,其实它是非常的壮观,但是给到的信息会有让人会有一些困惑,但是如果说你再一个因为服务器端渲染这只是两张图片而已,你打开两份,并不会说对你的网页浏览器造成双倍的外交当中数据的一些负担,或者说渲染的压力。
那只是两张图片,其实我们就可以比较清晰地看到说,从到达点的角度来看,越去城市外围的地方的金额就越高,这个也是 make sense 的,因为大多数都是市中心打车,那么他到了市中心的地方肯定就是相对来说金额低一点,那道越远的地方金额就越高。从上车地点的角度来看的话,其实最明显最显眼的这些区域就是纽约的一些机场,从机场出发要到市区,因为机场一般都会离市区比较远,从机场出发到市区,他的订单金额比较高,这也是比较 make sense 的一个部分。
然后也是我们可以在这边设置一些时间窗口的过滤,然后让他去做一个比较,怎么讲就是一个时间播放,然后看每一天它的一些情况的变化。有的时候觉得还蛮有意思的。
35:50——Demo 3: 纽约出租车热力图
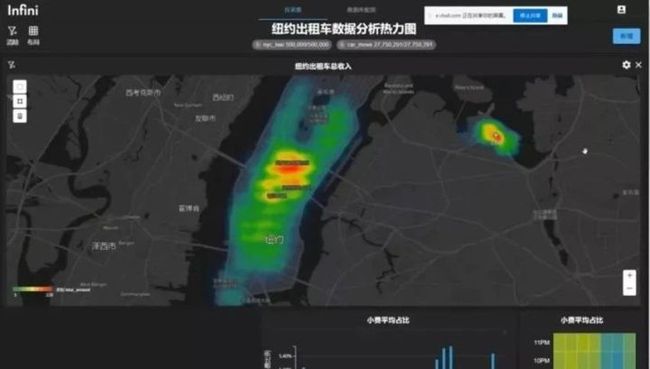
再给大家看一下,我刚才在我们叠加图层当中提到热力图。对,热力图的话稍等一下,把它调小一点,他有点太大了。所以这是一个热力图叠加在一个 Mapbox 上的例子,它始终会显示在我可见的这个区域当中最火热的区域,它会以最深的颜色去做一个显示。所以我们聚焦在曼哈顿的纽约曼哈顿岛上东区这个部分的话,应该来说它都是始终会把最热点的区域去做一个颜色最深的一个着色。它其实就是我们渲染出的图,然后叠加在 Mapbox 的地图上的一个示例。然后其实我们还有一个因为纽约出租车数据相对来说比较经典一点,所以它有很多配套的东西,当然我们也找了一些,比如说像这个是曼哈顿岛上的建筑物的一些地理信息,在这种情况下稍等我改一下它的,我改一下它汇总的指标,我觉得改成订单的总金额会比较会比较会比较有说服力一点。
对吧?对,所以这是他是把所有的订单的信息,按照建筑物的的GIS的数据,经纬度的信息去进行了一个汇总,当然这部分的信息的话,因为开源的数据集的话可能相对比较有限一点,我们只找到了曼哈顿岛上的绝大多数建筑物的地理信息,所以成本所以我们主要的展示都是集中在曼哈顿岛上。纽约市的反而建筑信息不是那么多,在开源的数据集当中。刚才我跟 Mapbox 工作人员有聊到说,其实 Mapbox 也会提供所有这些地图上的建筑物的一些地理信息,所以其实接下来的话我们也会考虑说能不能去把这些 Mapbox 已经有的这些信息都结合在这些分析的过程当中,它其实就会从某种角度来说带来更多更直观的一些结果。因为不然的话,如果我们是按照点去着色的话,就是散落在街道两边的点,现在我们都按照建筑物的外形去进行着色的话,它其实从某种程度上来讲,它会带来更多的一些商业上的价值和理解的。
37:00——Demo 4: 深圳运营车辆位置分析

好,最后给大家看一下,我刚才说这是我们这机器上支撑的相对来说数据量比较多的一个例子,它是一个现在中国很多的地方政府都会提供一个开放的数据,提供大家去进行下载。当中,其实是有很多挺有意思的数据的。这个例子,我们用到的是深圳的一个运营车辆的一个位置的公开的数据集,也是在深圳市政府的网站上面去下载到了,他是 2018 年 10 月 8 号那一天的数据可以看到,虽然只是那一天的数据,但是他有 2700 万条信息,基本上就是每个运营车辆它隔30秒都会上报一次 GPS 的位置,所以你可以看到说这个数据量其实是相当恐怖的。
我们是按照这些数 GPS 上报的 GPS 点为坐标,然后按照它 GPS 上报的时候,他通常也会带一个速度,虽然 GPS 上报的速度有的时候也很恐怖,有的时候会很搞笑的出现什么 1000 公里每小时这种信息,但我们基本上是,因为觉得市区 80 公里差不多,所以我就按照 80 公里上限,然后我们可以看一下说他其实也挺有意思,在我们整个深圳的话,你可以看到他那些主干道看起来它的交通状况还是可以的,车速还是可以的。所以这些全部都是运营车辆,就包括了出租车、货车,包括公交车这些车辆,当然确实因为这个数据集是国内的,叠加到Mapbox上似乎有点偏移。
我们可以给大家来做一个 cross filter 的演示,虽然它是一个深圳市政府提供的运营车辆的数据,但其实深圳的车其实很明显,也不单单只在深圳运行,就是说比较活跃的一个可能是长途车,从深圳一直能够开到广州去。其实配合这些时间窗口过滤的话,我们能够比较直观的看到说这辆车子运行的轨迹,它是每一个小时是一格,他也挺快,应该是一辆长途车,从深圳到广州的一个长途车,在那边停了好久。
今天的演示就差不多到这边,我们的这一个海量时空数据的分析平台,基本上会在 4 月份做一个正式的开源,所以如果大家对这个东西很有兴趣的话,建议大家扫描我们的二维码,关注我们的公众号,然后第一时间能够获取到我们的开源的进展,我们也会把我们的一些整个方案背后的一些技术的原理,一些技术的文章定期的在我们的公众号上进行推送。
40:00——开始QA环节(总共22个问题)
http://weixin.qq.com/r/ASnK0rbEkevurfKx93wT(二维码自动识别)
Q1: 上下车的点怎么附着在建筑物上?
A:是这样的,因为每个建筑物它都会有一个 GPS 的轮廓。其实附着在建筑物上面是这样子的,因为本身像在我们的分析的过程当中,你可以看到说在我们是有一些标准的操作,比如说你是可以去指定一个区域去进行分析的,其实具体到建筑物上面的话,其实就是说一个建筑物就是这么一个小区域,然后数据库中的时空数据,根据这个区域去进行聚合计算。将这个区域当中所有的订单信息汇总后,着色在建筑物上。
Q2: 能谈一下 Megawise,Infini,Arctern 等的关系呢?
A:就是说 megawise 是我们的一个 gpu 加速的一个类似于数据分析的引擎,它其实相对来说是一个通用的引擎。对,刚才您看到说我给大家演示的界面上有个 infini 的字样,它其实是一个我们基于 megawise 去做的一套时空数据分析的一个平台,但是它因为相对来说会比较完整,但也比较重一点,所以对很多用户在使用的过程当中,他们会觉得说我的时空数据其实已经在 spark 上面了,我有自己的存储,我想再有一个新的存储,那么所以在这种情况下,我们就把时空数据分析的一层,以及服务器端渲染的这一层的功能抽离出来,然后形成一个单独的开源项目,我们把它叫做 arctern,因为 arctern 其实是一个北极燕鸥的名字,因为北极燕鸥他每年往返于南北极之间超过 4 万公里,是一种非常有方向感的鸟,所以也是就是说我们也是一个时空数据分析平台,所以给大家一个寓意,就是能给大家带来很多的方向感。
Q3: 刚刚切换数据类型时, 是后台服务动态渲染还是预处理渲染?
A:这个都是在后台去做的渲染,因为前台其实我们这是一个浏览器,没有太多的图上没有任何的一个渲染功能的。
Q4: 无人驾驶中高精地图及前端poc可以使用做前端展示?这里面接入实时数据是如何处理的?
A:是这样的,因为在整个这套 arctern 的这套东西去对接 spark 以后,其实我们的实时数据注入就可以利用 spark 的 stream 去做实时数据的注入,包括后续 spark 做完之后我们去对接。
Q5: 你这个是历史数据,如果是实时数据呢?这么大的数据量会有问题吗?
A:是这样的,就是说实时数据要注入到 spark 的话,它其实怎么讲?就是说因为海量的数据,因为我们能够看到这么大量的数据都是,因为它是有一定的时间去积累起来,才会有这么大量的数据,如果实时数据的话,比如说像运营车辆 30 秒才上报一次 GPS,信息的话,其实你每 30 秒能看到的一些新的信息并不会太多,这部分增量的信息,因为在做一个数据分析的过程当中,性能最好的时候,肯定是把它们全部都放到内存当中了,所以其实增量的信息加载到内存其实并没有很多,所以它加载到内存的速度相对来说是会比较快的。
Q6:后端渲染的地图瓦片是实时渲染的吗?
A:对,所有的图片在后端渲染的时候都是实时渲染出来的。
Q7: 如果是服务器端渲染图片,能否满足你刚才说的场景“按照时间筛选要素”的实时性要求?
A:是的,刚才所有的 demo 都是一个在线的 live demo,所以它是一个我的时间窗口,它播放的时候,它是把这个时间窗口滑动到这个小时之后,他会把新的时间段作为一个SQL当中的查询条件发送到后端,然后在用后端去进行处理完之后再生成图片,再把图片发送到前端。
因为其实像我笔记本电脑的话,它也只是 1080P 的一个分辨率的显示器,所以你可以想哪怕是把我整个显示器的图片都填满,也就 1920×1080 这么大小的图片,所以他其实图片的传输的速度和生成的速度其实是很快的。
Q8: Zillizanalytics 和 megawise 的关系是什么?他们都是开源的吗?
A:是这样的,megawise 是一个数据仓库,但是整个 Zillizanalytics 套件,他会给更多提供一种端到端的能力和一个功能。相对来说我们接下来开元的部分是一个偏向于 Zillizanalytics 套件的这部分的东西,当然我们未来是会把我们更多的东西都去输出到开源社区上面的。这一点其实也可以参考我们另外一个项目 Milvus。我们基本上所有的我们到目前为止,Milvus 当中全部都是开源的。在时空数据分析这一块,其实我们以后也会走相同的道路。
Q9: 后台服务器渲染能讲一下吗?什么技术实现的?
A:后台服务器渲染其实就是用 openGL 形成的一些图片,怎么讲,就是说要跟我们开源之后,你可以我们会输出一些技术文章去进行更多的讲解,但其实它就是把生成的结果,然后通过 openGL 的方式去生成的一些图片。
Q10:如果是空间分析模型,支持复杂空间计算?
A:复杂的空间计算这个的话,是这样的,我们现在在做的开源的这部分的东西,就是把所有的技术处理的这些一些比较标准的一些API先做到做出来,然后开源出来,然后如果说复杂的一些计算的话,可能到时候您可以提一些 issue 在 github 上,详细描述一下,你到底要做的是一个什么样的复杂的操作,然后我们可以看一下,如果他是一个常用的操作的话,我们肯定是很愿意把它加入到这样一个开源项目当中的。
Q11:是针对服务器端的吗?
A:对,这个产品是一个针对服务器端的产品,但是它的前端是可以在 PC 的浏览器或者移动端的应用当中集成去做显示的。点击型选整个图片。
Q12:渲染按瓦片还是真的图片?我看你是在 Mapbox 中通过 image 类型添加的。
A:渲染的是整个图片,这是我的显示区有多大,它就会生成整个显示区域的图片,然后再叠加在 Mapbox 的地图上面。
Q13:按区域进行筛选也是同理去实时渲染吗?空间查询是如何做优化的?
A:对,也是去做的实时的渲染,因为怎么讲就是说我一定要生成一个新的图片,我才能把原来叠在 map 上的地图上的图片去替换掉,所以它都是新生成的,不然的话信息就会越来越乱,所以查询的优化话主要是我们在试题当中用到的都是一些 gpu 服务器做了一些查询的优化,因为就像刚才讲到,因为 gpu 服务器的话,我们对它的整个的执行路径的,包括它的执行的任务调度,都做了相应的一些不同于 CPU 的模式下的一些调整和优化。
Q14:实时查询也是效率问题吗?
A:实时查询效率也是效率问题,对没错,大家可以看到在刚才的演示当中,其实整个的查询效率还是再一个就是说荷载,就是说实时交互的过程当中延迟还是比较可以接受的一个状态。
Q15:和 Geomesa 的优缺点?
A:这一部分的话,我需要去了解一下,因为 geomesa 的话确实我还真的不是特别的了解,我可以把这个记下来,然后后续我们也会去做一些比较方便大家去理解。因为如果有人提问的话,我觉得这应该是一个大家已经在用的一个方案。
Q16: 要改 style 从后端配吗?
A:是的。和渲染图片有关的东西的话,都是需要在渲染引擎上面去做一些调整,当然我们现在会给到一些基础的功能,就是说比如说这种点的大小,我们是可以去配,就是说你要多大的点,然后我们也可以去配说你想要多大多少个点的数量,因为当你点特别多的时候,就是你穷尽所有的屏幕的每一个像素,其实也显示不了那么多点,其实就是说你可以去通过减少一下你的点的数量来提高性能。然后另外一部分就是这个色带,我们现在也是做了一个怎么讲可配置的选项,我们有一些预设的一些色带可以供用户去做选择,但其他的部分的话,如果你还想改其他的 style 的话,可能就要在源码层面去做一定的调整。
Q17:会不会是大量数据加载在 openGL上
A:数据库的目的,并不是把大量的数据加载到了 openGL 当中,因为我们知道它只负责出图,所以他只是把怎么讲?这是前端在后一层的分析处理引擎,先进行一些基础过滤和分析之后,把结果提供给 openGL 的渲染引擎,然后让他去根据要求去出图,并不是说直接把所有的东西全部都丢过去。
Q18:属性信息是通过鼠标选取位置查询然后前端显示吗?
A:其实也很简单,就是说因为在这一个显示的区域当中,其实我们可以知道说他的几个点的经纬度,他的 4 个角的经纬度,我鼠标在这一点的时候,他其实是可以知道说我鼠标点击的经纬度是什么,然后他会向后台发送一条查询去说我要查在经纬度上的订单的信息,返回过来的就是在经纬度上的订单的信息,所以它其实并就是说不是像前端那样子,所有都在浏览器当中完成,它,其实背后对应的是我生成了一条查询的语句,发送到后端,然后在后端查询到结果,再形成弹出窗口。
Q19:什么时候用到 GPU?
A:主要是做一些聚合操作的时候最典型!比如说做一些聚合操作的时候,类似于像这种怎么讲,数据库当中 SQL 当中的那些求和求平均值这些劣势的操作,他会需要去读取,比如说这张表中所有的列靠在一上面,我想要求一个合,他就会在比如说这张表当中有 1000 万数据的话,他就去 1000 万个数据的 column,然后做一个求和,在这个情况下,其实用列式存储的数据库配合GPU去做一个批量计算效果是最好的。
Q20:支持 Mapbox 的矢量切片吗?
A:这个的话我需要去了解一下,因为这部分确实因为我们的前端现在的话,主要聚焦在做服务器端渲染的那些图片的那些出图的上面,是不是支持矢量切片,我要看一下,可能是我们可以去扩展的一个功能的。
Q21: 有个项目是实时数据传输的,想用放实现大概每秒 10 万个 GPS 点...
A:这个的话我们可以在群里面继续去进行交流。
Q22: 数据量大,或者图层多会有浏览器内存不够的情况吗?
A:是这样的,就是说图层多的话,你想 1019、1920×1080,其实就这么多个像素点,它一张图图片其实并不大,并不会造成浏览器的内存不足,主要是为不需要的情况下,浏览器内存不足的情况会更加常见一点。好,所以如果大家有什么后续有什么问题的话,我们都可以在群里面进行进一步的交流。
注:本文内容由科大讯飞软件转制而成,如有疑问,请参照线上直播。
文字总结不过瘾,直接回看线上直播点击这里回看线上直播:https://live.vhall.com/room/watch/993515689?invite=&from=singlemessage&isappinstalled=0
这个项目即将在4月开源,有兴趣的朋友们可以多多关注,也欢迎加微信zilliz-tech加入我们技术讨论群喔~