
承接 【数学建模】2018全国大学生数学建模竞赛B题感悟(中)
四、解题流程
1.目标
在第一天时,我对第一组数据进行了CNC挨个调度,因为CNC工作的时间很长,导致RGV加料然后再回到位置1,就闲下来了,计算一下,给第一台机器上料28s,机器需要560s加工,第588s才能换料、下料,而RGV上料+移动也就(28+31)4+203 = 296s,到位置一移动需要48s,那还剩下244秒呢,就算第二步需要洗料,也才多25*8=200s,RGV小车很闲好吗?调度有什么用?根本不值得调度啊。可实际上,当CNC工作时间小的时候,RGV小车就很抢手了。
之前那样挨个调度,抛出一开始上料存在空的情况外,CNC的利用率都是100%,而RGV小车的利用率则低了些。由此看出,提高小车利用率什么用都没有,我们要的是CNC的利用率,这样CNC才能产出更多的产品。
2.穷举思想
如果说计算机专业出来的人和普通人做问题有什么区别的话,穷举一定在其中,大量无法用笔计算的问题,我的第一想法是穷举,其次才是相比办法优化,甚至是用笔能解决的问题也想写出一个通用程序,即使以后不再使用。
如果我能穷举出八小时内所有的可能,是不是就能找到一个最优的方案了?但是这就像一棵树啊,每次都会生成多种可能的岔路,我难道要写一个不知道多少叉的树对它进行深度遍历吗?这树又如何生成呢?先想想别的吧。
3.仿真
仿真程序是在无事的时候的无奈之举,没想到真的和后面的程序会有那么高的契合度。
仿真应该如何搭建呢?根据程序组织的方式,首先就应该写出一个类和大致所需要的接口。
从需求入手,我们的仿真项目是通过调度RGV进行的,主体就是RGV,而RGV能做什么呢?换料、移动、等待,这就是最基础的操作,因此最起码要完成这些操作,以及有能把当前CNC状态、生产产品的数量给打印出来的功能才行。而且单单是文字、数字的堆砌就写难看,用图来表达会好很多。
4.遗传算法
既然目标是产品的产量,希望产量达到最大,这显然是个优化问题了,然而目标函数、约束又是什么?只要列出式子来,就可以用线性规划、混合规划解决问题;理想情况下,把给的数据输入,就可以输出代表调度的结果。然而哪里来这么一个标准的函数呢?
此时我想起遗传算法,同样是优化算法,一开始我以为它解决的是和规划一样的事情。然而我想起那时看的几篇遗传算法论文,里面的编码、解码方式各有各的不同,遗传算法的编写方式竟然如此自由!遗传算法最重要的几个模块就是适应度函数(fitness function)、编码(encode)、解码(decode)方式,并随着编码形式生出的交叉、变异方式各有各的不同。如果我能把这些空缺都添上,是否就意味着我能使用遗传算法解决这个问题了!
那么来构建这个模型吧!
适应度函数:
如何构建适应度函数?我们需要适应度去做自然选择,常规遗传算法的适应度函数只是一个数学函数,通过输入变量得到值。这个适应度也是优化的目标,已经有了,就是产量,如何得到产量呢?产量是根据什么变化的呢?首先,毫无疑问,原题目中给的时间是作为输入变量。但一定不是只有这些,除了时间,是什么让产量不同的呢?
是调度!
又因为调度的不同,使产量不同,所以适应度函数应该是包含着输入时间变量,以及后续的调度组成!
如何知道一系列调度产生的结果呢?
是仿真!
通过仿真程序,即可通过调度函数,得到相应的结果,既产量。适应度函数解决!
编码:
如何编码?就像是如何将我们的外表还原成DNA一样,常规的编码就是二进制编码,或者格雷码编码,而对行为编码,最简单的,就是对行为进行编号。比如,RGV停止,编号为0。行为看起来只有三个,但是行为本身却不是相同的,例如向前走一步、向后走两步,给机器CNC#1加料等等,因此编码的并不只是行为,还有参数。我们想要最少的编码编出所有的行为,其一,需要最简化表示;例如向前走一二三步,向后走一二三步,需要六个编码,但走到位置1、2、3、4,只需要四个编码。其二,用大状态包含小状态,例如上料、下料、换料,在只有一道工序的时候完全可以整合为一个换料,内部通过当前位置的CNC状态,自动判断自己要做什么;因此CNC1#上料、CNC1#下料等就不需要了,给1~8号CNC的换料行为编码即可。注意,整合编码的前提是状态可以根据CNC准确地推测出来,如果含有歧义或随机性,便不可以整合为一个编码,就比如走到位置1和走到位置4,如果整合为一个编码,就会导致复现时无法确定的问题出现。
在编码中,我们将行为以及参数编码为数字。确定了如何编码,那么我选择多少个编码呢?我们在生成树核阶段再讨论。
解码:
如何解码?当前我们有一个参数,如何变为可以输入到适应度的变量(或者说调度)呢?
很简单,调查表法即可,将解码想象为一个列表,编码为0的参数放到下标为0的位置,编码为1的放到下标为1的位置,这样很容易就能完成译码操作。
选择:
在这个遗传算法中,只有这一步操作和常规遗传算法完全一样,适者生存,不适者被淘汰,用适应度决定种群是否生存下去即可。既根据变量以及一系列调度生成的最终结果作为该种群的适应度,将这个适应度作为分子,将所有种群的适应度加和作为分母,分子分母比值作为种群生存下去的概率,计算所有种群的概率,然后对生态圈做种群数量次数的重复抓取即可。
值得一提的是,常规遗传算法在选择阶段需要对适应度做出排负(让所有适应度减去所有适应度的最小值,可让所有种群不存在负概率),但本题中产品是不可能出现负生产的,因此排负处理不需要。
交叉:
交叉算法是我认为在我设计的这一套算法中最不合理的地方,先说说实现方法。
对生态圈进行遍历,检测种群是否符合交叉条件(随机出的数小于交叉率),符合便开始交叉,随意找到一个与其交叉的调度链条,从第一个调度开始检测,直到两者不同的位,随机从父母链的节点选择一条走,随后后面的选项重新随机。
为何说这种方法不好,因为交叉是为了得到父母中可能存在的优秀基因,然后得到更大的适应度,但我设计的交叉方法,只是在链条前和交叉位继承父母链条,后面的随机排更是有些扯。那为何这么设计呢?
因为这是调度。
常规遗传算法的输入变量是并行的,变量与变量之间无必要联系。但本题的调度与调度之间却是有明确的先后关系,事有先后之分,没有之前的操作,后面的调度都可能是其他可能,因此简单的将固定位交叉是完全不合理的。我也只能想出这种办法来交叉了。
变异:
生物的变异是无方向的。同样,我遍历生态圈所有种群看他们谁会交叉。如果交叉,随机找到一个变异点,这个变异点的调度重新随机,而后面的一系列调度也会重新随机生成。这是我最基础的想法。
但我想像中的变异算法不应该是这样简单的。想想生物中,熊猫是变异成猫更容易还是变异成熊更容易?自然是相近的熊更容易;小的变异一定会比大的变异更容易发生。回到我们的题中,那里的调度改变了会对最终适应度(产量)产生更大的影响?自然是越往前影响越大。以此看来,越往前,发生变异的可能越小,而后面的调度比前面的调度更可能变异。因此本题中的交叉概率应该由两部分组成,分别为:基础概率、权值。
例如:我的基础变异概率为0.03,变异概率应该会从100%向后往500%增大。假设当前位为第位,总长度为L,那么当前位置变异的概率为:
自此,遗传算法的架构已经搞清楚了,只是疑问还没有完全解开,例如:具体如何给行为编码?遗传算法的初始种群又该如何选取?请看生成树核。
5.生成树核
不要误会,这个生成树核和生成树没有任何关系!
我在数据结构或者离散数学中都接触到了生成树的概念。再次不将它的概念,诸位只需要记住两者没有任何概念即可。
那么生成树核到底是什么呢?首先说它英文名称:Generator Tree Kernel,学过Java、Python等语言的都应该了解Generator的概念。什么是生成器?在计算机中,内存是有限的,部分看似简单的事物却是无限的,再大的容量也难以承载起无限的东西,例如斐波那契数列。虽然无法存储简单的斐波那契数列,却可以选择存斐波那契数列的函数定义,等需要的时候,只需要继续向下取出一个新数即可,而这个函数的定义,就可以用生成器完成。
话说回来,如果我们存有之前的一系列调度以及调度所造成的当前状态,是否就可以知道下一步我们可以做什么?没错,这可以实现!它就像是生成器一样,通过当前状态,判断下一步的调度;而它又和生成器不是完全一样的,它每个状态都能推出多种可能,因此就像是树一样发散开来,因此可以叫生成树,而它像是状态与操作的集合,因此称作生成树核。
因为是树,我们对树的一系列操作也可对它进行,首当其冲的是上面的穷举思想,只要对它进行深度遍历,就可以做到将所有可能得到,进而得到最优解。但这种思想太过简单,为何不用一切其他方法与它相结合呢?
没错,说的就是遗传算法,利用生成树核,不用遍历,只需要随机生成N条路径作为初始种群,种群中的每条“DNA”都是调度,而解码、交叉、变异的方法在上面已经讲过了。
是时候该细化编码规则、状态转化了。让我们先研究一下,只有一工序的状态转化,以及它应该有的前因后果。
首先,对状态的约束应该分为两种。其一是无论如何都不应该去做的,例如给正在工作的CNC机器上料,在仿真程序上的表现就是:调用就出错;此为硬性约束。其二是身为编程者的我认为不应该做的,例如,如果当前位置存在空置CNC机器,RGV不应该抛下它乱跑;此为软性约束,区别在于,如果我在仿真上调用程序,并不会出错;此为软性约束。
在此我们放上硬性与软性共同约束下的状态转换方式:

于是产生了生成树核,如果对它进行深度为三的广度遍历,会出现以下结果:
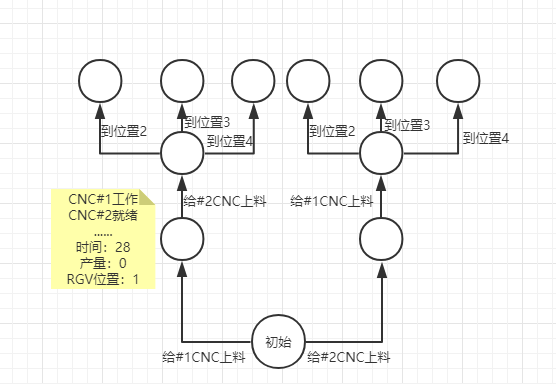
由此观测到,我们的状态总共13个,分别为编码为0的等待,编码为1~8的换料,编码为9~12的移动。其中等待为自适应行为,根据当前状态判断移动位置和等待时间;换料也为自适应操作,根据CNC状态判断是上料还是换料加洗料。
五、代码编写
说了这么多建模思想,身为编程手,编程实现模型才是我的首要任务,从编程速度来讲我还算合格,不过从程序员角度来讲,我的代码还是有不少冗余的地方。
1.仿真
(1)引入
仿真是我第一个实现的程序,在此之前引入需要引入的东西:
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import random
#自定义错误
from workerror import *
上面的是最基础的代码,不过我的代码(作图)是运行在jupyter上面的,所以要加一些东西:
%matplotlib inline
import pylab
pylab.rcParams['figure.figsize'] = (20.0, 8.0)
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
(2)错误类
别被workerror吓退了,也别去用pip安装什么的!!!那只是我自定义的错误!
来看看workerror.py文件:
# 超时错误
class TimeoutError(Exception):
def __init__(self, *args):
self.args = args
#无机器就绪、完成错误
class NoMachineFinishError(Exception):
def __init__(self, *args):
self.args = args
#位置错误
class PlaceError(Exception):
def __init__(self, *args):
self.args = args
#CNC工作错误
class CNCWorkError(Exception):
def __init__(self, *args):
self.args = args
不需要理解,到后面用到自然会明白
(3)CNC与CNC状态类
然后是CNC类:
#CNC状态
class CNC_Status:
ok = 0
working = 1
finish = 2
#CNC类
class CNC:
def __init__(self, id):
self.id = id
self.status = CNC_Status.ok
self.begin_time = 0
self.end_time = -1
self.work_id = 1
def work(self, begin, finish_time, work_id=1):
if work_id != self.work_id:
raise CNCWorkError('当前机器的作业与物料不符合')
self.status = CNC_Status.working
self.begin_time = begin
self.end_time = begin + finish_time
self.work_id = work_id
def finish(self):
self.status = CNC_Status.finish
self.begin_time = -1
self.end_time = -1
def change_work(self, work_id):
self.work_id = work_id
def info(self):
return str(self) + ('' if self.end_time == -1 else f' working begin in {self.begin_time}, end in {self.end_time}, do {self.work_id} work')
def __str__(self):
return f'CNC{self.id} Status:{self.status}'
def __repr__(self):
return str(self)
首先CNC_Status的作用相当于枚举,这里简略地用类代替一下,至于为何之前分析总共有:就绪、被RGV工作、工作、完成四个状态,此时却只定义了三个?因为RGV只有一个,当RGV对CNC工作时,自动会讲时间跳到RGV完成的时间,因此不需要被工作状态。
然后是CNC类,让我们来看构造方法,很普通,得到当前机器的机器号(id)、状态为就绪、开始时间为0,结束时间为-1,工序都为一工序。
再之后是工作(work)方法,得到开始时间、结束时间,工序默认为1。
完成方法,使状态变为完成,开始、结束时间置为-1。
再然后是改变工序(换刀具)方法、返回信息方法、显示字符串方法等等。
很普通对吧?
(4)RGV类
RGV只有一个,并且影响到CNC,因此RGV是程序的核心,不过编写仿真时还没意识到这个问题,所以类名取为Work
class Work:
colors = {'run':'#66ccff', 'wash':'#B481BB', 'stop':'#0C4842' ,'change':'#F6C555'}
#go_time: [一个单位时间,两个单位时间。。。]
#work_time: [第一道工序的时间, 。。。]
#up_down_time: [基数上下料时间, 偶数上下料时间]
#wash_time:洗涤时间
def __init__(self, go_time, work_time, up_down_time, wash_time, source=(2, 4), max_time=10**100):
self.encode = {'stop':{'num':0, 'func':self.RGV_stop, 'kwargs':{'no_move':False}}}
self.decode = [{'behavior':'stop', 'func':'RGV_stop', 'kwargs':{'no_move':False}}]
self.go_time = go_time
self.up_down_time = up_down_time
self.wash_time = wash_time
self.work_time = work_time
self.max_time = max_time
self.place = 1
self.source = [[CNC(row+1+(col)*2) for col in range(source[1])] for row in range(source[0])]
self.time = 0
self.machine_have = 0
# (start, end, what)
self.record = {'RGV':{'run':[], 'change':[],'wash':[],'stop':[]}}
self.record['CNC_finish'] = {}
for i in range(1, source[0]*source[1]+1):
self.record[f'CNC{i}'] = []
self.record['CNC_finish'][f'CNC{i}'] = []
for i in range(source[0]*source[1]):
self.encode[f'c{i+1}'] = {'num':len(self.encode), 'func':self.change_wash, 'kwargs':{'num':i+1, 'no_move':True}}
self.decode.append({'behavior':f'c{i+1}', 'func':'change_wash', 'kwargs':{'num':i+1, 'no_move':True}})
for i in range(source[1]):
self.encode[f'r{i+1}'] = {'num':len(self.encode), 'func':self.RGV_go, 'kwargs':{'x':0, 'num':i+1}}
self.decode.append({'behavior':f'r{i+1}','func':'RGV_go', 'kwargs':{'x':0, 'num':(i+1)*2}})
# save arg
# {'RGV':[(begin, end, what)]}
def change_max_time(self, time):
self.max_time = time
def encodeDNA(self, S):
return self.encode[S]
def decodeDNA(self, n):
return self.decode[n]
def source_num(self):
total = 0
for row in len(self.source):
for col in len(self.source[row]):
if self.source[row][col] is CNC_Status.ok:
total += 1
return total
def all_source(self):
return [self.source[col][row] for row in range(len(self.source[0])) for col in range(len(self.source))]
def all_source_info(self):
for cnc in self.all_source():
print(cnc.info())
def RGV_stop(self, no_move=False):
start = self.time
if not no_move:
next_finish = min(self.all_source(), key=lambda x: x.end_time)
if self.place != int(np.ceil(next_finish.id / 2)):
self.RGV_go(next_finish)
start = self.time
finish_time = next_finish.end_time
while True:
if finish_time <= self.time:
break
self.time += 1
self.check()
end = self.time
self.record['RGV']['stop'].append((start, end, 'RGV stop at {self.place}'))
# x = -3\-2\-1\1\2\3
# x = CNC object
# x = 0, num = [1, 8]
def RGV_go(self, x=0, num=None):
start = self.time
old = self.place
if isinstance(x, CNC):
num = x.id
new_place = int(np.ceil(num/2))
v = np.abs(new_place-self.place)-1
if v == -1:
raise PlaceError(f'{x}原地没动')
self.time += self.go_time[v]
self.place = new_place
elif num is not None:
new_place = int(np.ceil(num/2))
v = np.abs(new_place-self.place)-1
if v == -1:
raise PlaceError(f'CNC{num}原地没动')
self.time += self.go_time[v]
self.place = new_place
else:
self.time += self.go_time[np.abs(x)-1]
self.place += x
if self.place < 1 or self.place > 4:
raise PlaceError('跑出边界')
end = self.time
if end > self.max_time:
raise TimeoutError('RGV_go超时')
self.record['RGV']['run'].append((start, end, f'RGV {old} to {self.place}'))
self.check()
def up(self, num, work_id=1, no_move=False):
start = self.time
row = 0 if num / 2 - num // 2 != 0 else 1
col = int(np.ceil(num / 2) - 1)
if self.source[row][col].end_time != -1:
raise NoMachineFinishError('当前机器未完成')
if not no_move and int(np.ceil(num/2)) != self.place:
self.RGV_go(num=num)
start = self.time
elif int(np.ceil(num/2)) != self.place:
raise PlaceError('当前位置不可以上料')
self.time += self.up_down_time[0 if num / 2 - num // 2 != 0 else 1]
self.source[row][col].work(self.time, self.work_time[work_id-1], work_id=work_id)
self.machine_have = 0
end = self.time
if end > self.max_time:
raise TimeoutError('up超时')
finish_start = self.time+self.work_time[work_id-1]
self.record['CNC_finish'][f'CNC{num}'].append([finish_start, finish_start, ''])
self.record['RGV']['change'].append((start, end, f'RGV up in CNC{num} work: {work_id}'))
self.record[f'CNC{num}'].append((self.time, self.time+self.work_time[work_id-1], f'CNC{num} work: {work_id}'))
self.check()
def change(self, num, no_move=False):
start = self.time
row = 0 if num / 2 - num // 2 != 0 else 1
col = int(np.ceil(num / 2) - 1)
if self.source[row][col].end_time != -1:
raise NoMachineFinishError('当前机器未完成')
if not no_move and int(np.ceil(num/2)) != self.place:
self.RGV_go(num=num)
start = self.time
elif int(np.ceil(num/2)) != self.place:
raise PlaceError('当前位置不可以上料')
work_id = self.source[row][col].work_id
self.machine_have = work_id
self.time += self.up_down_time[0 if num / 2 - num // 2 != 0 else 1]
self.source[row][col].work(self.time, self.work_time[work_id-1], work_id=work_id)
end = self.time
if end > self.max_time:
raise TimeoutError('umax_time超时')
finish_start = self.time+self.work_time[work_id-1]
self.record['CNC_finish'][f'CNC{num}'].append([finish_start, finish_start, ''])
self.record['RGV']['change'].append((start, end, f'RGV change in CNC{num} work: {work_id}'))
self.record[f'CNC{num}'].append((self.time, self.time+self.work_time[work_id-1], f'CNC{num} work: {work_id}'))
try:
if self.record['CNC_finish'][f'CNC{num}'][-2][0] == start:
self.record['CNC_finish'][f'CNC{num}'].pop(-2)
else:
self.record['CNC_finish'][f'CNC{num}'][-2][1] = start
self.record['CNC_finish'][f'CNC{num}'][-2][2] = f'CNC{num} finish in {self.record["CNC_finish"][f"CNC{num}"][-2][0]}, end of {start}'
except:
print(str(self.record)+f' in CNC{num}_finish')
raise Exception('超出数组边界')
self.check()
def wash(self):
start = self.time
self.time += self.wash_time
self.machine_have = 0
end = self.time
if end > self.max_time:
raise TimeoutError('wash超时')
self.record['RGV']['wash'].append((start, end, f'RGV wash'))
self.check()
def check(self):
for cnc in self.all_source():
if cnc.end_time <= self.time and cnc.begin_time != 0:
self.finishCNC(cnc.id)
@property
def value(self):
i = 0
for start ,end, what in w.record['RGV']['wash']:
if end < max_time:
i+=1
return i
def finishCNC(self, num):
row = 0 if num / 2 - num // 2 != 0 else 1
col = int(np.ceil(num / 2) - 1)
self.source[row][col].finish()
def change_wash(self, **kwargs):
p = self.place
if self.all_source()[2*p-1].status == CNC_Status.ok or self.all_source()[2*p-2].status == CNC_Status.ok:
self.up(**kwargs)
else:
self.change(**kwargs)
self.wash()
# 制作甘特图
def plot(self):
h = 10
height = 30
for i in range(1, len(self.source)*len(self.source[0])+1):
plt.broken_barh([(start, end-start) for start, end, what in self.record[f'CNC{i}']], [h, height], color='#EB7A77')
plt.broken_barh([(start, end-start) for start, end, what in self.record[f'CNC_finish'][f'CNC{i}']], [h, height], color='#4E4F97')
h+=40
ticks_axis = [25+40*i for i in range(len(self.source)*len(self.source[0]))]
ticks = [f'CNC{i}' for i in range(1, len(self.source)*len(self.source[0])+1)]
ticks_axis.append(25+40*(len(self.source)*len(self.source[0])))
ticks.append('RGV')
for k, v in self.record['RGV'].items():
plt.broken_barh([(start, end-start) for start, end, what in v], [h, height], color=self.colors[k], label='RGV_'+k)
plt.yticks(ticks_axis, ticks)
plt.legend()
plt.xlim(0, self.time + 10**(len(str(self.time))-1)/4)
# plt.axvline(3600, ls='--', color='#000000')
比之前长了不少,不急,慢慢分析。
首先是colors字典表,这个是作图时各个行为的表示颜色,上面的颜色还是在日本的设计师找色彩灵感的网站上面找的,是我学板绘时老师推荐给我们的。逐渐偏离标题
往下看,encode(编码)和decode(解码),按理来说应该是封装成方法,没错,是这样,后面就是这样实现的,不过内部其实也是通过查找这两个数据结构实现的。按照常理来说,编码与解码应该是放在遗传算法中,但我感觉放在RGV类中更好组织代码。不过这个代码设计是有缺陷的;其一,业务逻辑不是这样,看起来不但心中有梗,而且还可能导致同一实验编码数量不同,不过我这个只用于建模中,也不存在其他人调用这个代码,因此不会出现这种问题;其二,编码这种东西是共有的,就算是给RGV类也应该是类变量而非成员变量,这么做会导致每次构建新对象时多占用空间、多出生成时间,不过同样的道理,建模时我的组织代码能力是很差的,希望不要深究。其三,encode的数据类型储存冗余,看下去就知道了。
这里encode是字典类型,理想中是{'stop':0, 'c1':1, 'c2':2,...,'r1':9,...,'r4':12},其中c意为change,换料,r意为run,既移动。如果问:开头只有stop啊,其他的呢?请看构造函数结尾的那三个for语句。这里说一下第三个编码解码的设计缺陷,就在编码这里,编码只需要把行为和参数编码为数字就好,例如r是行为,1是参数,一起形成一个调度,而我还将方法和参数存了起来,事实上,对编码这一步是不需要的,我后面复现步骤是用新的对象而不是老的对象,self的方法bound方法自然是无用的,不过这不影响代码的使用。
相比起来,decode就没有问题了,前面提到过decode是调查表法,数据结构是[{'behavior':'', 'func':'','kwargs':{.....}}, ...],其中,behavior是行为,就是上面的stop、c1等等,func是调用方法的名称,kwargs是字典,里面是{参数名: 参数值}的格式,如果说还是有冗余的话,behavior是多余的,不过加上了可以更方便调试。如果问:怎么译码呢?为没看到编号'1'什么的啊,前面已经提到过了,decode用的是调查表法,第一个就是编号为0的行为,第二个是编号为1的行为,以此类推。如果问:decode存的是方法的字符串啊,我怎么通过字符串调用方法?这个看到后面的调度自然就明白了,如果着急了解的话,给个提示:去看看python的魔术方法__dict__方法,具体的后面再说(我没用eval)。
然后是对各成员变量的初始化,machine_have是机器抓手中的素材,在只有一工序的情况下没用。recode是记录功能,其中包括RGV的行为,CNC的行为,CNC还有两个,这同样是设计的失误,和RGV设计的一样就好了,不过一样不影响使用。最后的三个for是完善encode和decode。
方法change_max_time,顾名思义,改变默认最大时间,这有什么有用?我后面写的的所有行为方法的结尾,都有时间检测函数check,然而有些事情已经发生了,也会记录下来,就导致时间结束,工作却没停下来,直到停下才检测之间直到时间到了,而有了最大时间的检测,检测到时间到了,就会抛出TimeoutError错误。
encode和decode方法,对之前的编码、译码进行封装,实际没卵用。source_num是检查就绪机器的数量,实际上没卵用,根本没用上。
all_source方法倒是很常用,原题的CNC排列方式是两行四列,我也是这么存的,但实际上操作特恶心,有了这个方法,把二维列表转为一维列表,舒服多了,返回结果数据结构为[CNC1, CNC2, ...]这样。而all_source_info是打印所有CNC的详细信息方便调试,可惜在调试过程中还是被冷落了。
RGV_stop的起名是一个失误,我一开始管这一状态叫停止,实际上是等待。no_move参数意为:是否不移动,默认是False,也几乎都是False,毕竟我设计的等待就包括与移动到最近要完成的机器这一选项。因此程序里一个bug我没发现,如果是True就会出现finish_time not defind这种,不过好解决,只要把判断是否移动的if条件只包含移动方法的调用就好了,还不影响我使用,就暂时不改了。下面的while True就是慢慢检测,一直到完成时间,然后调用check检测,让到时间的机器完成,并将等待这一过程记录在record中。
RGV_go,即为RGV移动,虽说有两个参数,但实际上同时只有一个起效,首先,如果x有值,num为None的情况,为x有效,检测类型,如果是{-3, -2, -1, 1, 2, 3}中,即为向前向后移动,如果是CNC对象,则自动移动到CNC所在位置。否则num不为None,则num有效,num代表同样代表CNC的id,取值为[1, 8]。了解这三个情况,就知道后面三个if条件判断是怎么回事了。同样最后记录在record中,并check。
up与change为上料和换料,内部逻辑很像,有很多重复代码,可以说是设计的失误。其中上料三个参数,num为上料的机器,work_id是工序,默认为1,我感觉这个参数是多余的,完全可以通过机器手中是否有一工序熟料与CNC机器的类型来判断,no_move同样是看是否自动移动的,相比与RGV_stop,这个no_move通常为True,因为我希望将移动和换料操作分开。change相比起来没有work_id,毕竟如果换料,工序一定是一样的。
在一工序中,wash和change是绑在一起的,但二工序就不同了;值得提的是,我一开始是让洗料后自动加一,但会造成时间过后没完成的洗料操作继续进行,因此我将统计交给了value属性方法(在下面)。
check,检测到时间的机器变为完成状态。
value属性方法,根据record记录,如果工作超时不计产数。
finishCNC,完成工作。
chang_wash,将换料、上料、洗料结合,内部逻辑判断自己应该做什么
通过record记录,做出甘特图。
我将写好的文件打包放入work.py中以供其他程序调度。
(5)用法
仿真程序已经完成,但没有生成树核自动判断状态,需要用户自行判断。例如我选择顺序调度:
# 调用规则
# series = [2,1,4,3,6,5,8,7]
series = [1,2,3,4,5,6,7,8]
# series = [1,8,3,6,5,4,7,2]
# series = [1,4,5,8,7,6,3,2]
w.change_max_time(3600)
try:
for i in series:
w.up(i)
while w.time < 3600:
w.RGV_stop()
for i in series:
try:
w.change(i)
w.wash()
except:
w.RGV_stop()
except TimeoutError:
print(w.value)
#output: 41
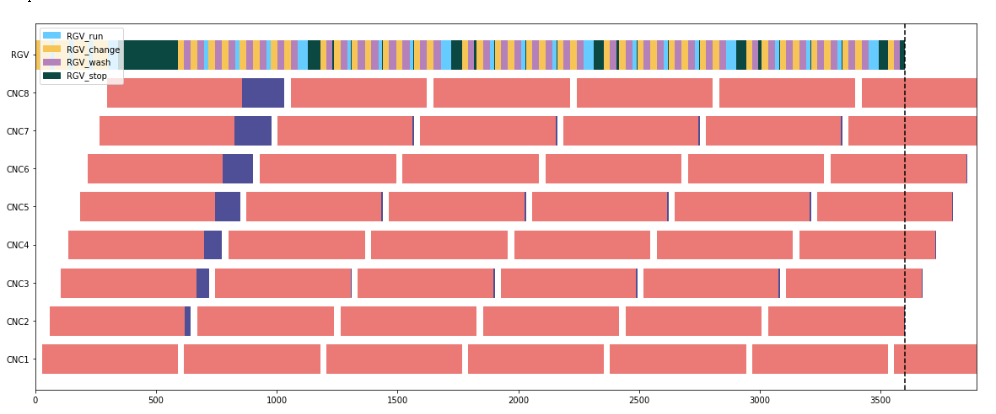
作图:
pylab.rcParams['figure.figsize'] = (20.0, 8.0)
w.plot()
plt.axvline(3600, ls='--', color='#000000')
2.生成树核
生成树核的概念是在遗传算法之后讲的,但它的功能却是遗传算法生成随机种群所必要的,因此我们先放出生成树核的代码。
先说一下,生成树核并没有写一个新类,我将它看成是RGV类的一部分。因此定义生成树核为RGV类的成员方法。
先放出代码:
# return [(func, args), (func2, args)]
def enable_to(self):
# stop?
stop = True
all_source = self.all_source()
for cnc in all_source:
if cnc.status != CNC_Status.working:
stop = False
break
if stop:
return [{'func':self.RGV_stop, 'kwargs':{'no_move':False}, 'encode':self.encode['stop']['num']}]
# run?
go = False
if (all_source[self.place * 2-1].status == CNC_Status.working) and (all_source[self.place * 2 - 2].status == CNC_Status.working):
go = True
if go:
result = []
a = [1, 2, 3, 4]
a.pop(self.place-1)
for p in a:
if all_source[p * 2-1].status == CNC_Status.working and all_source[p * 2-2].status == CNC_Status.working:
continue
result.append({'func':self.RGV_go, 'kwargs':{'x':p-self.place}, 'encode':self.encode[f'r{p}']['num']})
return result
result = []
if all_source[self.place * 2-1].status == CNC_Status.ok:
result.append({'func':self.up, 'kwargs':{'num':self.place*2, 'work_id':all_source[self.place * 2-1].work_id, 'no_move':True}, 'encode':self.encode[f'c{self.place*2}']['num']})
if all_source[self.place * 2-2].status == CNC_Status.ok:
result.append({'func':self.up, 'kwargs':{'num':self.place*2-1, 'work_id':all_source[self.place * 2-1].work_id, 'no_move':True}, 'encode':self.encode[f'c{self.place*2-1}']['num']})
if all_source[self.place * 2-1].status == CNC_Status.finish:
result.append({'func':self.change_wash, 'kwargs':{'num': self.place*2, 'no_move':True}, 'encode':self.encode[f'c{self.place*2}']['num']})
if all_source[self.place * 2-2].status == CNC_Status.finish:
result.append({'func':self.change_wash, 'kwargs':{'num': self.place*2-1, 'no_move':True}, 'encode':self.encode[f'c{self.place*2-1}']['num']})
return result
def retry(self, collection):
for n in collection:
d = self.decodeDNA(n)
Work.__dict__[d['func']](self, **d['kwargs'])
return self
看起来是两个方法,没错就是两个方法,其中enable_to意为可做的事,既是生成树核;而retry是重做(复现),传入的参数collection为调度编码序列,可以按照编码将所有步骤复现。让我们看看代码。
enable_to没有参数传入,返回的类型为可做调度组成的列表,按照我们之前分析的三状态挨个判断。
首先是stop(wait)?逻辑就是简单的检测是否所有机器都在工作。其次是run(move)?检测当前所在的位置的CNC机器是否都在工作,是的话,将可以工作的位置都返回。最后是判断:上料还是洗料;不过最后这一代码属于冗余代码,因为后写的change_wash方法会自动判断是上料还是换料+洗料;不过不影响功能。一工序的生成树核的逻辑看起来还算简单。
后面的retry是重做方法,原理很简单,遍历collection编码序列,通过decode解码得知方法名与方法参数,至于如何知道方法的字符串来调用方法?前面提示了魔术方法__dict__,这里详细说一下。
__dict__为python内置的魔术方法,以python万物皆对象的特性,几乎所有变量(对象、方法、类)都能通过__dict__得到当前对象所有成员的字典,格式是{变量名的字符串: 变量值};而代码中为何是Work调用__dict__呢?因为对象调用__dict__返回的字典是不包含成员方法。类调用的方法不能无视第一个参数,因此对象的引用一定要传进去,在类定义的时候传入self就好,而在外面调用时,一定要对象的变量名。通过字典映射,返回的function对象,第一个参数传入对象引用,后面的参数decode中有存,只要将其解包就好。
生成树核的代码解析完毕。然后是实验环节。
随机生成一条调度路径:
#引入
import numpy as np
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import random
import pylab
pylab.rcParams['figure.figsize'] = (20.0, 8.0)
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
import work
# 参数构建
go_time= [20,33,46]
work_time= [200]
up_down_time= [28, 31]
wash_time= 25
w = work.Work(go_time, work_time, up_down_time, wash_time)
#随机生成
collection = []
while w.time < 3600:
choose_set = w.enable_to()
next_index = random.randint(0, len(choose_set)-1)
next_behavior = choose_set[next_index]
next_behavior['func'](**next_behavior['kwargs'])
collection.append(next_behavior['encode'])
#作图
w.plot()
注:import的work文件是前面的仿真代码导出的包
3.遗传算法
先上代码:
import numpy as np
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import random
import copy
import pylab
pylab.rcParams['figure.figsize'] = (20.0, 8.0)
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display
import work
from workerror import *
import csv
引入的代码,其中csv是为了输出结果用的
class GA:
def __init__(self, pop_size, total_time, cross_rate, mutation_rate, wp, go_time, work_time, up_down_time, wash_time, source=(2, 4), max_time=10**100):
self.populations = []
self.pop_size = pop_size
self.total_time = total_time
self.cross_rate = cross_rate
self.mutation_rate = mutation_rate
# (min,max)
self.wp = wp
self.go_time = go_time
self.work_time = work_time
self.up_down_time = up_down_time
self.wash_time = wash_time
self.source = source
self.max_time = max_time
for i in range(pop_size):
self.populations.append({'scheduler':[], 'value':0})
w = work.Work(go_time, work_time, up_down_time, wash_time, source, max_time)
try:
while w.time <= total_time:
choose_set = w.enable_to()
next_index = random.randint(0, len(choose_set)-1)
next_behavior = choose_set[next_index]
next_behavior['func'](**next_behavior['kwargs'])
self.populations[-1]['scheduler'].append(next_behavior['encode'])
except TimeoutError:
self.populations[-1]['value'] = w.value
continue
def get_fitness(self):
return np.array([pop['value'] for pop in self.populations])
def select(self):
fitness = self.get_fitness()
populations = []
for index in np.random.choice(np.arange(self.pop_size), size=self.pop_size, replace=True, p=fitness/np.sum(fitness)):
populations.append(copy.deepcopy(self.populations[index]))
self.populations = populations
def crossover(self):
for pop in self.populations:
if np.random.rand() < self.cross_rate:
i_ = int(np.random.randint(0, self.pop_size, size=1))
new_pop = []
pop_len = len(pop['scheduler'])
cro_len = len(self.populations[i_]['scheduler'])
w = work.Work(self.go_time, self.work_time, self.up_down_time, self.wash_time, self.source, self.max_time)
next_to = None
crosspoint = -1
for index in range(min([pop_len, cro_len])):
if pop['scheduler'][index] == self.populations[i_]['scheduler']:
d = w.decode(pop['scheduler'][index])
work.Work.__dict__[d['func']](w, **d['kwargs'])
else:
crosspoint = index
new_pop.extend(pop['scheduler'][:index])
if np.random.rand() > 0.5:
next_to = pop['scheduler'][index]
else:
next_to = self.populations[i_]['scheduler'][index]
break
if next_to is not None:
try:
while w.time <= self.total_time:
d = w.decode[next_to]
new_pop.append(next_to)
crosspoint += 1
work.Work.__dict__[d['func']](w, **d['kwargs'])
enable_to = w.enable_to()
next_index = random.randint(0, len(enable_to)-1)
next_to = enable_to[next_index]['encode']
except TimeoutError:
pop['value'] = w.value
pop['scheduler'] = new_pop
continue
def mutation(self):
for pop in self.populations:
for index, sche in enumerate(pop['scheduler']):
if np.random.rand() < self.mutation_rate * index * (self.wp[1]-self.wp[0]) / len(pop['scheduler']):
new_pop = []
new_pop.extend(pop['scheduler'][:index])
w = work.Work(self.go_time, self.work_time, self.up_down_time, self.wash_time, self.source, self.max_time)
for s in new_pop:
d = w.decode[s]
work.Work.__dict__[d['func']](w, **d['kwargs'])
try:
while w.time <= self.total_time:
enable_to = w.enable_to()
next_index = random.randint(0, len(enable_to)-1)
next_to = enable_to[next_index]['encode']
d = w.decode[next_to]
work.Work.__dict__[d['func']](w, **d['kwargs'])
new_pop.append(next_to)
except TimeoutError:
pop['scheduler'] = new_pop
pop['value'] = w.value
break
def evolution(self):
self.select()
self.crossover()
self.mutation()
def get_work(self):
return work.Work(self.go_time, self.work_time, self.up_down_time, self.wash_time, self.source, self.max_time)
这就是遗传算法的主类了。先看构造方法。传递参数其实只是比在RGV类的前面加上了:种群大小、总时间、交叉概率、变异概率、变异加权这些参数。与常规遗传算法比较,只是限制变成了总时间,变异加权倒是新增的。后面的逻辑便是随机种群,只不过随机次数要多一些,将每个调度链记录下来。正常情况下求适应度应该是重新调度一遍试试,但这样太麻烦浪费时间没有意义,因此我选择将适应度(产品数)记录下来,所生成的数据结构是这样的:[{'scheduler':[], 'value':n}, ...],其中scheduler是调度序列,value是适应度值。
然后是得到适应值序列,遍历一遍pop序列中所有字典的value值即可。
选择和常规遗传算法没有不同,要注意的是,为了引用的安全性,我复制序列的时候都是深度复制(deepcopy),防止改一个,相同的种群都被更改。
crossover和mutation看起来很长很多,但实际上的算法都是之前说的。而evolution是进化,既把选择、交叉、变异都执行一遍。
最后的get_work方法是为了方便复现,返回一个参数完全相同的初始状态RGV对象。
接下来就是实验了。
#构建参数
pop_size = 20
total_time = 3600*8
cross_rate = 0.5
mutation_rate = 0.003
wp = (1, 3)
go_time= [18,32,46]
work_time= [545]
up_down_time= [27, 32]
wash_time= 65
max_time = 8*3600
ga = GA(pop_size, total_time, cross_rate, mutation_rate, wp, go_time, work_time, up_down_time, wash_time, max_time=max_time)
for i in range(15):
values = [pop['value'] for pop in ga.populations]
print([pop['value'] for pop in ga.populations], sum(values))
ga.evolution()
m = max(ga.populations, key=lambda x: x['value'])
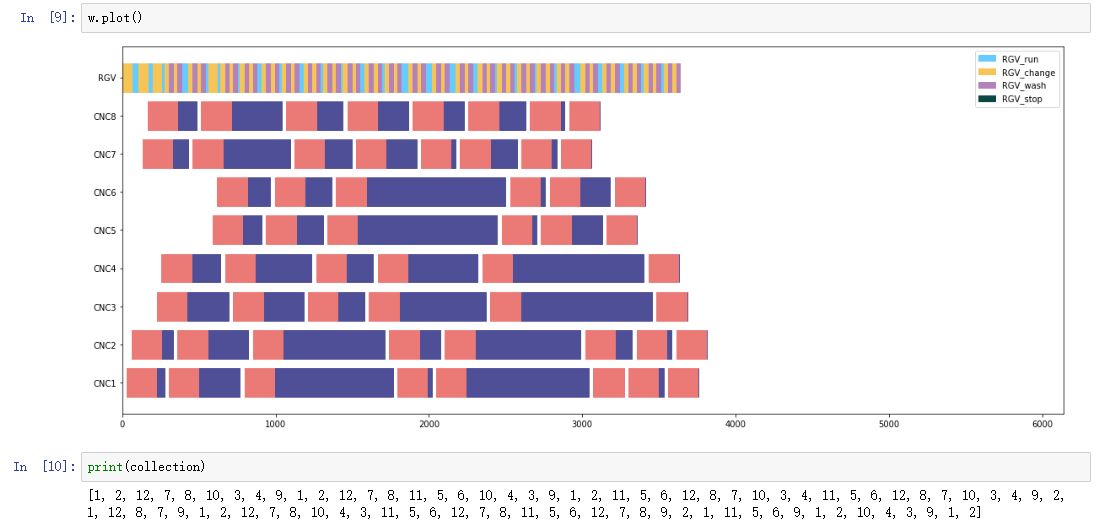
其中m是value值最大的种群,接下来只要复现加作图就好:
ga.get_work().retry(m['scheduler']).plot()
plt.axvline(3600*8, ls='--', color='#000000')

最后是输出为题目所需要的支撑材料的csv格式文件:
with open('第一种情况第一组数据.csv', 'w', encoding='gbk', newline='') as f:
writer = csv.writer(f)
writer.writerow(['加工物料序号','加工CNC编号','上料开始时间','下料开始时间'])
i = 1
for start, end, cnc in l:
if end > 8*3600:
break
for row in l[i:]:
if row[2] == cnc:
end = row[0] - w.up_down_time[0 if int(row[2][-1]) / 2 != int(row[2][-1]) // 2 else 1]
break
writer.writerow([i,cnc[-1],start-w.up_down_time[0 if int(cnc[-1]) / 2 != int(cnc[-1]) // 2 else 1],end])
i+=1
4.其他情况
至此第一种情况看起来已经完美解决了,接下来是第二种情况:双工序。我同样列出状态转换的文字描述:
不抛弃任何一二工序熟料
才加工完的一工序熟料不可以立刻放到刚刚加工这个熟料,且换完刀片的二工序机器上
等待规则:
前提①:手上无熟料,CNC全工作
应对①:到最近要完成的机器等到可工作
前提②:手上有一工序熟料,且全局没有就绪/完成的二工序机器(不计刚换完刀片的机器)
应对②:到最近要完成的二工序机器处等待
移动规则:
前提①:手上有一工序的熟料,当前无就绪/完成二工序机器
应对①:移动到就绪/完成的二工序机器的位置
前提②:手上无料,且当前位置机器都在工作
应对②:移动到可工作的位置
CNC操控规则:
上料:
前提①:手上为空,当前位置有就绪的一工序机器
应对①:该机器工作
前提②:手上有一工序熟料,且当前位置存在就绪的二工序机器(不计刚换完刀片的机器)
应对②:该机器工作,手上为空
换料:
换料总前提:
不换刀片
· 前提①:手上为空,当前位置有一工序完成机器
· 应对①:该机器工作,且手上存在一工序熟料
前提②:手上有一工序熟料,当前位置有二工序完成机器
应对②:该机器工作,清洗二工序熟料,手上为空
下料:
前提①:手上为空,当前位置有二工序完成机器
应对①:该机器空闲
下料总应对:
检测是否要换刀片
如何换刀片呢?在调度执行了n次时(例如10次)检测两种机器的利用率占比,利用率的公式为,其中为工作时间,为完成后等待的时间,如果差距达到一定程度(例如0.3),就需要把利用率低的机器换成利用率高的机器。
看上边一堆判断逻辑是不是感觉很乱?在写第二问的时候,生成树核、仿真、遗传算法都要变。
首先是仿真,多到工序在程序中的record已经不一样了,而且从输出结果来看,还要多存一个下料开始时间。我又增加了CNC类的复杂度,加上了持有(have)属性,严谨了work_id参数,同时增加了几个错误类以及物料类(可以不用)。
状态转变了,生成树核也要改,同时编码方式也研究过是否需要改,我认为是不需要改的,主体还是等待、换料、移动,只是每个主状态的内部逻辑判断要难很多了,但需要增加一些编码,我当时增加的是ct1~8,意思是change tool,换刀片状态。还有一点,之前的换料之分成了上料 和 换料+洗料的绑定,然而这次换料+洗料未定是绑定的,一工序换料的产出不用洗,现在想想或许还要加上内部的逻辑就好,但当时想的很多,甚至洗料都能拿出来单做一个状态,因此当时还想增加一个绑态的概念,既同时做出两个绑定的调度,在代码上体现的就是调度列表中不但只有单独的调度,还有多个绑定的调度组成的元组。
既然有了绑态,调度就不是那么简单了,而遗传算法中的随机逻辑就又要重新写。
再思考第三种情况,我没有深入思考,当时想的是,既然CNC工作会有几率错误,那么每次上料、换料时都检测一下概率,以及发生错误的时间,并想到,CNC的利用率越高,出错的概率可能会越大,利用率对出错概率会有加成。
5.编程总结
我考虑了很多,如今已经无法复现出当时的所有想法了。或许就是如此多冗余的代码结构和不统一、通用的代码,才使得当时焦头烂额吧。
当时第二种情况完成了仿真代码的编写,但生成树核的代码出现了各种BUG,这些BUG已经无力更改,不但是程序结构混乱,而且还有精神疲惫,时间压力等因素的制约,使自己无法静下心来思考逻辑。我有信心再给我一天能理清楚逻辑,不过这种话说什么都晚了。
六、最终感悟
这次比赛,我个人的决策出现不少失误,结果好坏掺半。
1.不完全确定的错误:
(1)择题
所谓选择比努力更重要,选一个更好的题比什么都重要。事后老师跟我们说,我们如果选A题应该会得到更好的成绩,因为A题只需要推导热力学公式,再让我跑一下代码,很容易就得到很好的结果。
我不确定是否真是这样,至少B题我拿出了一个可用的模型,而A题是我完全没接触过的领域。(听说有些人这两天学了两章热传导233)
(2)休息
之前我一直主张:不要熬夜,好好休息,第二天才有最好的精力去建模,困的时候根本想不出什么好的模型。
然而在最后一天我却自己打破了这个“清规戒律”,直接导致结果最后一天精神不佳,纵使没有那种半睡半醒的姿态,也可能是我无法写出第二种情况生成树核的“凶手”。
我不清楚如果我好好睡觉,最后一天会是什么样子,因此我不确定这个抉择是否是错误的。
(3)建模步骤
同样是老师说的,他认为建模正确的步骤应该是:先将大问题划分为小问题,再找出对应小问题的解法,然后再编程。而我是直接上手编程,再选择建模方法。
这么说也没错,不过我也并非是无脑编程,当时的情况是队友想不出合适的模型,而我闲着又不想看论文。我选择的方法是仿真,无论是什么样的模型,最后都需要一个很好的展示,因此我认为这个步骤也没错,至于之后的生成树核与遗传算法都是已经想出了细节步骤才去动手实现的。因此这一步也不能完全确定对错。
(4)建模分工
按理来说,建模手想模型,编程手实现,论文手编撰论文是最常规的配置,但我却去建模。本来是没什么,我也感觉很好,毕竟题目这么难,只要有合适的模型就好了,但实际上,直接导致了后面发生的论文悲剧,我不确定插手建模这件事是否真的正确。
2.完全确定的错误:
(1)应该审核论文***
这是我在这次比赛中犯的最大的错误!!!
正常比赛中,建模手想出了模型,和编程手交流具体步骤,然后和论文手交流具体步骤,甚至是看着论文手写论文。然而这次比赛中编程手是我,但模型是我想出来的!我和建模手、论文手讨论具体步骤后,去实现代码,然后两个队友都去写论文了,并要求我将大致思想写出来。
我以为是怕中间有具体步骤不清晰需要对照、修改、完善的参照物,没想到基本是复制粘贴,然后对着原文去修改,不成想将愿意完全变了。例如生成树核的英文是Generator Tree Kernel,而队友附上的英文是Spanning tree nuclear;生成树核的原理上文写了,而当时队友照着改的时候写成了“记录成千上万个斐波那契数列的定义”,这和我的原意完全不符,论文中这样的例子很多很多。
这是我的决策失误,和队友没有好好的沟通,毕竟概念是我提出的,而队友不清楚,之间没有交流,就有了误会,造成论文很多地方词不达意,如果是之前,我一定会理一遍论文内容。
(2)应该参与论文编撰
同样的原因,原文只配了甘特图,而其他都靠文字和数学公式描述,看起来很是晦涩,而作为建出模型的我本应该画几个易懂的图,例如上面的生成树核,我却没去关注……同时老师也提到了让我们在文中放上伪代码,我完成了工作,却没有督促队友去实现,最终论文篇数过少,我有不可推卸的责任。
3.结语:
最终,感谢我的队友、老师们的陪伴,或许建模的成绩不会很理想,但积累了这些经验后,我不会再犯下类似的错误了。并且在这个建模中也有很多收获,用最短的时间理解了元胞自动机的原理并应用于实践,会了一种调度的优化方法,更深刻地理解了遗传算法的用途。
感谢你们的陪伴,下次比赛再见。