摘要:昨天我做了一个关于人工智能中的偏见的12分钟演讲。首先需要指出,我并不是这方面的专家,其中大部分是通过阅读相关方面的研究文章的总结。 而这篇文章就是对这个演讲的文字描述。
昨天我做了一个关于人工智能中的偏见的12分钟演讲。首先需要指出,我并不是这方面的专家,其中大部分是通过阅读相关方面的研究文章的总结。而这篇文章就是对这个演讲的文字描述。
自动决策已经成为我们生活的一部分
人工智能主要是对机器自动决策的研究。近些年,相关领域的投资在以惊人的速度增长。
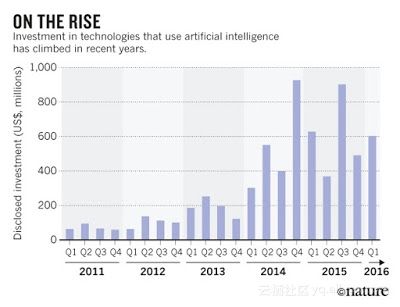
情况会越来越糟
如果你关注一下过去几年的新闻头条,和机器自动决策相关的新闻数量有了明显的增加。它越来越多的涉及到了人们的健康,安全和权利。其中就包括:
•奥克兰的预防性治安系统
•无法识别女性的汽车系统
•涉及种族歧视的姓名搜索引擎广告
•交通服务
•房屋歧视(直接违法)
•犯罪预测
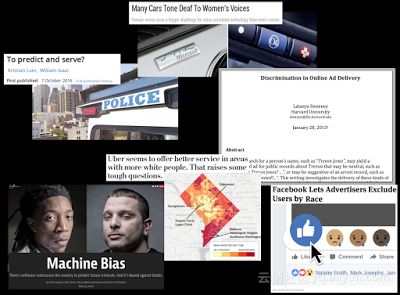
这些虽然只是个案,在今天它们的影响看似并不大,但在不久的将来,我相信会是一系列重大的社会问题。
三个产生偏见的根源
这里,我想集中在三个具体的导致偏见的原因。这主要是因为,它们和我过去十几年的工作密切相关,我对它们相对比较了解。 这三点是:
1.数据收集
2.目标函数
3.反馈回路
样品选择偏差
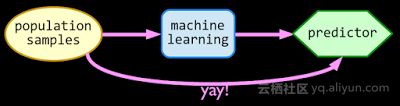
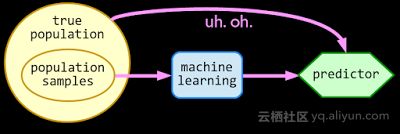
机器学习的标准方法是从你关心的对象集中取出一些样本,通过机器学习算法学习他们,从而产生一个预测机。然后基于统计学原理,你从类似的一个目标集中采取新的样本,那么,这个预测机将做出一个比较准确的预测。 这基本上适用于所有机器学习模型。当你的样本来自于目标集的子集(或不相关的目标集),而你仍旧使用之前的预测机,这时问题就产生了。
我的父母都是从事市场营销研究工作的,并已经用了很长时间进行焦点小组和调查的工作。 几年前,我父亲为一家欧洲公司做一个项目。这家公司是从事护肤品制造的。 他们想进入美国市场,并雇佣我父亲研究美国的护肤品市场。 父亲告诉他们,他需要进行四到五个不同区域的研究来得出结论。他们感到很惊讶,因为他们觉得一个就够了,比如只做中西部(克利夫兰或芝加哥)区域就够了。 但问题是皮肤护理的需求在西南地区(气候更潮湿)和西北地区(不那么潮湿),与东北和东南地区非常不同。 在芝加哥做的研究,不能适用于亚利桑那州或佐治亚州。
这个问题在统计学领域通常被称为样本选择偏差,或者称为协变量位移(Covariate Shift),域匹配依赖(domain adaptation depending)

这一领域最有影响力的成果是1979年James Heckman发表于《经济计量学》上的论文,为此他赢得了2000年诺贝尔经济学奖。 如果你没有读过这篇论文,你应该去读一下:它大概只有7页。在过去的二十年里,机器学习领域已经有了大量的成果,其中大部分是基于Heckman的研究。 这里还要特别提一下Corinna Cortes,她是谷歌纽约研究院的负责人,在过去十年里,她撰写了许多关于这方面的优秀论文。 特别是她在2013年理论计算机科学上的论文中深入地进行了概述和提出了新的算法。
这不只是错误率上升
当你从一个样本空间(如美国西南部)移到另一个(如美国东北部)时,你应该预见到错误率会有所上升。
这里我做了一些简单的实验来验证我的观点。我收集了一些取自亚马逊网站上评论的数据,它们涵盖了四类商品(书籍,DVD,电子产品和厨房电器),并且我们需要认为这些评论来自美国的不同区域的消费者。
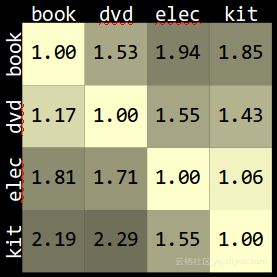
如图,显示了在一类商品(列)上的训练并在另一个类商品(行)上测试时的错误率。误差率被归一化,因此对角线(相同商品类)上的数字是标准1(实际误差率约为10%)。非对角线显示了由于样本选择偏差而导致测试的错误。特别是,如果你用其他商品类的预测值对厨房电器商品进行预测,那错误率可能有两倍之多。
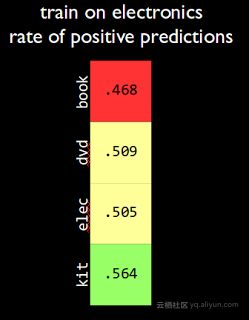
我还发现,这些数据是平衡的:50%成正偏差,50%负偏差。然而,如果你在电子产品上进行训练并对其他商品类进行预测,你会得到不同的误报率。它的期望值是50%,如图,这个期望值出现在电器商品和DVD类商品的预测中。然而,如果你用它预测书类商品,预期值是被低估的;而如果你预测厨房电器,则预测值又过于乐观。
所以不仅仅是错误率上升的问题,而且它们的误报率也同样会出现问题。许多专家已经意识到这些问题并开始对它们进行研究,例如Feldman,Friedler,Moeller,Scheidegger和Venkatasubramanian。
优化的目的
我一直在让我的学生思考,在人工智能领域中,优化的目的是什么,优化是否能真正更好地为我们所用。
在数据结构学习过程中我们学的第一件事往往是如何使用简单的方法(如广度优先搜索)进行图搜索。而人工智能的学习中,我们往往会学习更复杂的事情,如A*搜索。比如,如何在地图上规划路线,像上图所示是我从家到办公室的路线(我从来没有按照这个路线走过,因为我没车而且乘坐地铁更便捷)。
我们花费大量时间来证明算法在最短路径成本方面的最优性。在课上,我向学生们提出了一个具有挑战性的问题,让他们找出其中可能的成本构成。随后,他们从相对明显的因素开始:道路的长度,等待红灯的时间,沿途的平均速度,是否是单行道等等。然而我并不满意,于是他们又有了其他想法,比如:每英里油耗(出于保护环境或者省钱的原因),是否是“事故易发”区域(这个充满了偏见),道路的质量(需要修整的还是全新的等等)。
可以看出学生的想法都是不错的。然后,我让他们变得‘邪恶点’。我让他们假设作为一个‘邪恶’的公司会想出怎么样的路径成本。然后,他们给出了他们的回答:可能因为某个商家付了钱,这个路径规划会使更多的用户经过他们的商店。也可能因为用户正在驾驶我们公司拥有或投资的汽车品牌,这个路径规划会选择更好(或更坏)的道路路线。再比如这个路径规划会绕开竞争对手的广告牌等等。

我们可以发现,问题的关键是:普通人无法了解到,这类人工智能系统优化目的是否能使其利益最大化。(这里需要声明一下,我绝对不是说Google或任何其他公司正在做这些事情,只是我们不应该假设他们没有。)
我强烈推荐《版本控制》(Version Control,作者Dexter Palmer)这本书,特别是对那些从事或将要从事人工智能教学的人。

书中,有一对工程师夫妇,他们开发了一个约会服务系统,比如Crrrcuit,不过是针对个人用户。在训练其中的人工智能系统时,系统的目标是帮助人们找到真爱。他们取得了成功,因此也得到了投资人的投资。但是随后投资人却意识到,一旦这个系统成功,他们就会失去大量的业务。而这也导致了另一个更微妙的系统目标,用户能找到大多数人基本符合自己要求的对象(以维持人们对系统的信任),但这些对象或多或少又不那么完美(维持客户使用该系统)。随后,为了赚钱,公司开始向广告商贩卖他们的数据。特殊人群的数据更有价值:特别地,广告商愿意为那些比较特立独行的人付更多的钱。因此,系统对这样的人提供的选择就非常的不令人满意,以保证他们始终使用这个系统。在这本书中,这种假想是通过人类推理进行的,但很容易看出,如果建立一个强化学习算法来以公司长期利润作为目标函数的话,人们就无法知晓机器到底在以什么为学习目标了。
反馈循环
Ravi Shroff最近访问了CLIP实验室,谈到了他在纽约关于警察盘查法规政策相关的工作(与Justin Rao和Shared Goel有关)。这个“盘查”法规是指(在2011年,超过68.5万人被警察在纽约街头被拦下,进行盘查,随后该规定在纽约被宣布违宪)警察有权在街上拦下他们认为可疑的人们以进行盘查,试图找到违禁武器或毒品。Shroff和他的同事专注于武器方面的问题。
他们考虑了以下模式:警察看到有人举止可疑,想要决定拦下或激怒那个人。 在正式行动之前,他们在计算机中输入一些数据,计算机会给出一个竖起的大拇指(需要盘查)或一个向下的大拇指(不需要盘查)。 这里的问题是:如何在较少的拦截次数(对个人有好处)下,同时仍然找到大多数违禁武器(对社会有好处)?
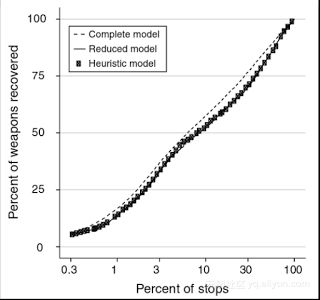
在这个图中,我们可以看到,如果系统将警察的非拦停率设为90%(因此只有10%的概率,警察会得到竖起的大拇指),他们仍然能够找出大约50%的武器。 如果只盘查约1/3的人,他们能够找出75%的武器。 这大大降低了对个人隐私的侵犯,同时仍然成功地保证街头的安全。
问题是,如果在实践中部署这样的系统,会发生什么?
警察也是普通人,不是一成不变的,他们的行为会随时间而变化,并且我们有理由相信一旦该系统被使用,他们的行为会因为有了这个系统而改变。 他们可能会向系统中提供更多或更少人的信息输入系统。 这就像人们对网络搜索引擎的使用随着时间而发生了变化,在这个过程中人们学会了更有效地使用搜索引擎,并通过自身学习而不依赖于它,因为我们知道通过它搜的内容有些并不是我们真正想要的 。
现在,一旦我们部署了这个系统,它收集了数据,这将是从根本上不同于最初训练时的数据。它也许可以不断适应新的学习对象,但我们需要更好的技术来让机器认识到它的学习对象是善变的人类。
总结和讨论
还有些重要内容,在上面我还没有提及,这里是一些例子:
1. 上面我说提到的所有的人工智能“失败”案例都与种族或性别有关。除此之外还有其他需要考虑的事情,如宗教,政治观点,残疾人群,家庭和孩子的地位,第一语言等等。虽然我没有找到相关的例子,但我很欢迎有人能提供给我类似的例子。
2.我比较少的关心那些貌似很“明显”的问题,因为我们甚至不知道它是否存在。比如:社交媒体平台是否可以通过推送,来帮助竞选中某一特定政党的候选人?普通人怎么可能发现背后的真相?
3.我们需要开始考虑更好地对人工智能研究进行资格审查。当我们使用人工智能解决一个问题时,我们需要知道这个方案到底在为谁服务?当我们选择一个数据集来训练机器时,哪些样本空间被遗漏了?更一般的来说,当我们说“解决”任务X时,是否真的意味着普遍性的任务X,或者是某些我们并没有意识到的某个特定人群的任务X?并且我们需要问自己是否“数据越多越好”---更多的数据是不是等于有效数据?
4.我还担心人工智能用循环决策作为全自动决策。只是因为人做出最终决定并不意味着系统不能偏袒那个人。对于复杂的决策,一个系统(即使只是网络搜索!)必须为人们提供帮助信息,但是我们怎么能保证这些信息不会有意或无意的带着某种偏见(我也听说过,在某个预测累犯系统中,人工智能的循环预测的结果比完全自动化的决定更糟糕,我想大概是因为那些我们不了解的一些人为偏见)。
本文由阿里云云栖社区组织翻译。
文章原标题《Bias in ML, and Teaching AI》,作者:Hal Daumé III
文章为简译,更为详细的内容,请查看原文