简介
实际上是对开源代码的学习。毕竟水平有限,能搞懂轮子的原理就不错了,不指望能造个更好的轮子。按自己的理解把代码重写了一遍,添加了中文注释。下面放链接。
- 原始项目
- 我的项目
原理
一般而言,我们使用 malloc 或者 new 来动态管理内存。 然而,这些函数由于牵涉到系统调用,效率很低。于是,如果我们使用很少的系统调用,申请一大块内存自己管理,就非常好了。这就是内存池的思想。内存池向系统申请大块内存,然后再分为小片给程序使用。每次我们请求内存,其实是在内存池里拿而非通过系统调用。它的优势体现在:
- 它从原理上比
malloc以及new快 - 分配内存时不存在 overhead
- 几乎不存在内存碎片
- 无须一个一个释放对象,只需要释放内存池即可
内存池也有缺陷:
- 需要知道对象的大小
- 需要根据应用的情况来调节
源码阅读笔记
= delete 用法
/*******
* 赋值 *
*******/
// 使用 = delete 禁用拷贝赋值,只保留移动赋值
MemoryPool& operator=(const MemoryPool& mp) = delete;
MemoryPool& operator=(const MemoryPool&& mp) noexcept;
参考 stackoverflow 上的相关问题。一句话总结就是禁用函数。
以上代码实际上就是禁用拷贝赋值,仅使用移动赋值。这是显然的,内存池拷贝代价太大。
static_assert 用法
// static_assert: 编译期断言检查
static_assert(BlockSize >= 2 * sizeof(Slot_), "BlockSize too small.")
在编译期间执行检查,如果不通过条件 arg1,则报错 arg2。
由于是编译期间运行,因此只能用于编译期间就确定了的常量。尤其常用于模板类的检查。
使用 union 的理由
union Slot_ {
value_type element;
Slot_* next;
};
一个奇怪的构造函数
// MemoryPool.h
MemoryPool(const MemoryPool& mp) noexcept; // 拷贝构造函数
// MemoryPool.cpp
template
MemoryPool::MemoryPool(const MemoryPool& mp) noexcept:
MemoryPool() {
}
推测其意思就是调用无参数构造函数。
析构函数中的强制类型转换
template
MemoryPool::~MemoryPool()
noexcept
{
slot_pointer_ curr = currentBlock_;
while (curr != nullptr) {
slot_pointer_ prev = curr->next;
operator delete(reinterpret_cast(curr));
curr = prev;
}
}
比较费解为什么要强制转为 void* 指针。源码中多次使用了 reinterpret_cast,具体可以参考 static_cast 和 reinterpret_cast 。
内存池实现细节
直接上图,这个图说明了内存池的运作原理:
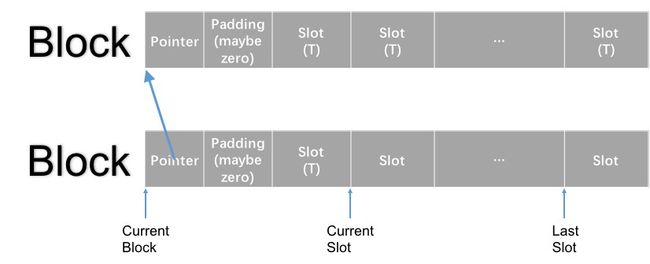
首先定义了一个 union,非常值得注意的是,这不是一个链表。这个 union 的本质是复用,一个 slot 里,既可能存的是数据,也可能存的是指向另一个 slot 的指针。这样的设计有助于节省空间,在某个对象不再需要时,直接放入 freeSlots_ 链表中,并改写 next 指针。
union Slot_ {
T element;
Slot_ *next;
};
为了实现内存池,我们需要四个指针:
Slot_ *currentBlock_;
Slot_ *currentSlot_;
Slot_ *lastSlot_;
Slot_ *freeSlots_; // 这是一个比较让人疑惑的名字,实际是指的 deallocate 之后空闲出来的 slots
结合上面图中的位置,可以大概理解其运作方式。注意图中没有标出 freeSlots_,因为这个指针如果没有进行 deallocate,就保持为 nullptr。
下面分析最关键的两个函数。
- 内存池向系统申请内存
template
void MemoryPool::allocateBlock() {
// 头插链表
// A->B->C 插入 X
// X->A->B->C
char *newBlock = reinterpret_cast(::operator new(BlockSize));
reinterpret_cast(newBlock)->next = currentBlock_;
currentBlock_ = reinterpret_cast(newBlock);
// 这里需要作一个内存对齐,因为第一个区域存放的是指向上一个 Block 的指针,而不是 Slot
// 而之后的都是Slot
char *body = newBlock + sizeof(Slot_ *);
size_t bodyPadding = padPointer(body, alignof(Slot_));
currentSlot_ = reinterpret_cast(body + bodyPadding);
lastSlot_ =
reinterpret_cast(newBlock + BlockSize - sizeof(Slot_) + 1);
}
里面的注意点都用中文注释出来了。
- 在内存池中为对象分配内存
inline T *allocate(size_t n = 1, const T *hint = nullptr) {
if (freeSlots_ != nullptr) {
// 存在 freeSlots
T *result = reinterpret_cast(freeSlots_);
freeSlots_ = freeSlots_->next;
return result;
} else {
// freeSlots 还未初始化或者已经耗尽
if (currentSlot_ >= lastSlot_) {
allocateBlock();
}
return reinterpret_cast(currentSlot_++);
}
}
这里尤其需要注意的是,在本文的实现中,freeSlots_只在释放对象时才会被赋值。如果只进行了分配没有释放,那么会一直执行 else 中的代码。
inline void deallocate(T *p, size_t = 1) {
if (p != nullptr) {
// 也是头插链表
// 空闲链表 A->B->C,现在释放了 X 的空间,需要将 X 加入空闲链表
// X->A->B->C
reinterpret_cast(p)->next = freeSlots_;
freeSlots_ = reinterpret_cast(p);
}
}
在释放中,体现了 union 的作用。传入的指针本来指向一个对象,将其强制转为 union Slot,再将 next 指针赋值为空闲链表头。此时就覆盖对象的前 8 字节内容(64 位机器),对象失效。只留下前 8 字节指针被使用。
内存池的效果
运行测试函数可以得到:
Copyright (c) 2013 Cosku Acay, http://www.coskuacay.com
Provided to compare the default allocator to MemoryPool.
Default Allocator Time: 7.3624
MemoryPool Allocator Time: 1.23673
Here is a secret: the best way of implementing a stack is a dynamic array.
Vector Time: 2.14202
The vector implementation will probably be faster.
可以看出,在 OS X 下,明显快于原始的 allocator。奇怪的是我在 Linux 操作系统下并没有跑出这么大的差距,并且 vector 实现确实快于内存池。