How to receive a million packets per second 16 Jun 2015 by Marek Majkowski.翻译:auxten
标题图:CC BY-SA 2.0image by Bob McCaffrey
之前在360工作,有同事做360安全DNS,和CloudFlare遇到了类似的问题
今天看到CF的blog发出了这篇文章,特此翻译一下,原文地址:How to receive a million packets per second
上周在一次闲聊中,我听一个同事说:“Linux的网络栈实现真是糟透了,单核50k packets/s就是极限了!”
于是我就想了,也许单核50kpps是普通Linux上运行的程序的极限,那么,Linux网络栈的极限是多少呢?所以就引出了我们的问题:
在Linux环境下实现一个能接收1000k UDP包的程序有多难?
我希望解答这个问题,可以给大家上一堂生动的《现代操作系统的网络栈设计》

首先我们假设:
测试 packets per second (pps) 比测试 bytes per second(Bps)更有意义。你可以通过pipeline和发送更大的包来达成更高的Bps,提高pps更加有挑战性。
既然我们关心的是pps,我们将会用UDP消息进行测试。更精确的说:32 bytes的UDP payload,也就是网络层的74 bytes。
为了测试,我们会用到两台物理机,我们暂且称作:“receiver”和“sender”。
两台物理机的配置为:2颗6 core 2GHz Xeon处理器,开启了超线程,也就是每台机器有24个逻辑处理器;网卡为Solarflare的10G多队列网卡,开启了11个接收队列,这点我们在后续会展开描述。
源代码参见这里:
dump/udpsender.c at master · majek/dump · GitHub ,
dump/udpreceiver1.c at master · majek/dump · GitHub.
准备工作
我们用4321端口作为UDP的端口。在我们开始之前,我们需要确保流量不被 iptables影响:
receiver$ iptables -I INPUT 1 -p udp --dport 4321 -j ACCEPT
receiver$ iptables -t raw -I PREROUTING 1 -p udp --dport 4321 -j NOTRACK
设定网卡IP
receiver$ for i in `seq 1 20`; do \
ip addr add 192.168.254.$i/24 dev eth2; \
done
sender$ ip addr add 192.168.254.30/24 dev eth3
1. 简单实现版
我们先实现一个最简单版本的sender和receiver,看看能抗住多少包
sender的伪代码如下:
fd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
fd.bind(("0.0.0.0", 65400)) # select source port to reduce nondeterminism
fd.connect(("192.168.254.1", 4321))
while True:
fd.sendmmsg(["\x00" * 32] * 1024)
我们本可以使用最常见的 send 调用,但是它的效率比较低. 内核态和用户态的上下文切换将会是一个很大的我们需要尽量避免的开销。幸运的是最近有一个很好用的系统调用sendmmsg加入了内核。用它我们可以一调用发送很多数据包。这里,我们一次发送1024个数据包。
receiver的伪代码:
fd = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
fd.bind(("0.0.0.0", 4321))
while True:
packets = [None] * 1024
fd.recvmmsg(packets, MSG_WAITFORONE)
类似的,我们用recvmmsg这个比 recv 更为高效的系统调用。
实验结果如下:
sender$ ./udpsender 192.168.254.1:4321
receiver$ ./udpreceiver1 0.0.0.0:4321
0.352M pps 10.730MiB / 90.010Mb
0.284M pps 8.655MiB / 72.603Mb
0.262M pps 7.991MiB / 67.033Mb
0.199M pps 6.081MiB / 51.013Mb
0.195M pps 5.956MiB / 49.966Mb
0.199M pps 6.060MiB / 50.836Mb
0.200M pps 6.097MiB / 51.147Mb
0.197M pps 6.021MiB / 50.509Mb
最简单的实现能达到197k~350k pps。还算不错。但是这里其实还有一定的变数在里面。由于内核随机的在CPU的核上移动我们的程序。把程序和CPU进行绑定会有帮助:
sender$ taskset -c 1 ./udp
sender 192.168.254.1:4321
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.362M pps 11.058MiB / 92.760Mb
0.374M pps 11.411MiB / 95.723Mb
0.369M pps 11.252MiB / 94.389Mb
0.370M pps 11.289MiB / 94.696Mb
0.365M pps 11.152MiB / 93.552Mb
0.360M pps 10.971MiB / 92.033Mb
从结果中可以看出来,内核将进城绑定在我们制定的CPU核上。这样提高了处理器cache的本地命中率,从而让测试数据更加稳定,这正是我们所期望的。
2. 发送更多的包
虽然370k pps对于一个普通的用户态程序是一个不错的成绩,但这仍然离我们的1M pps相去甚远。为了接受更多的包,首先我们必须发送更多的包。如果我们用两个线程独立去发包:
sender$ taskset -c 1,2 ./udpsender \
192.168.254.1:4321 192.168.254.1:4321
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.349M pps 10.651MiB / 89.343Mb
0.354M pps 10.815MiB / 90.724Mb
0.354M pps 10.806MiB / 90.646Mb
0.354M pps 10.811MiB / 90.690Mb
但是接收端的数据没有提升。 ethtool -S 将会展示我们的数据包实际上去了哪里:
receiver$ watch 'sudo ethtool -S eth2 |grep rx'
rx_nodesc_drop_cnt: 451.3k/s
rx-0.rx_packets: 8.0/s
rx-1.rx_packets: 0.0/s
rx-2.rx_packets: 0.0/s
rx-3.rx_packets: 0.5/s
rx-4.rx_packets: 355.2k/s
rx-5.rx_packets: 0.0/s
rx-6.rx_packets: 0.0/s
rx-7.rx_packets: 0.5/s
rx-8.rx_packets: 0.0/s
rx-9.rx_packets: 0.0/s
rx-10.rx_packets: 0.0/s
通过这些stats,这个NIC报告在#4的RX queue上成功的发送了350kpps的数据。rx_nodesc_drop_cnt 是一个Solarflare的计数器表示有450kpps的数据在传送给内核的时候失败了。
有时候排查这种问题是比较困难的。但是在我们这,原因是很明了的:RX queue #4把包发给了CPU #4。CPU #4已经不能承受更多的工作—读取350kpps的数据包已经让CPU打满。下图是Htop中的展示,红色表示的是sys time,也就是系统调用的CPU时间占比:
多队列网卡
很久以前,网卡都是用单队列在硬件和内核中进行数据包的传输的。这个设计有十分明显的缺陷:如果数据包超过单核的处理能力,那么吞吐量就不能提升了。
为了更好的利用多核系统,网卡开始支持多接受队列。多队列的设计是非常简单的:每一个RX queue都被绑定到一个单独的CPU,这样,通过把数据包分散在多个RX queue就可以利用上多CPU的处理能力。但是这也带来一个问题:对于一个数据包,如何决定由哪个RX queue去处理?
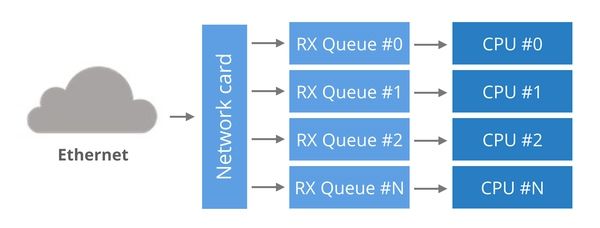
Round-robin轮询是不可接受的,因为这样会导致在同一个连接的数据包乱序。所以一个替代方案就是利用基于数据包的哈希来决定RX queue。哈希的输入一般是IP四元组(源IP、目的IP、源端口、目的端口)。这就确保了一个在一个连接上的数据包始终保持在一个RX queue,这样也就杜绝了数据包的乱序。
用伪代码表示:
RX_queue_number = hash('192.168.254.30', '192.168.254.1', 65400, 4321) % number_of_queues
多队列哈希算法
我们可以用 ethtool来配置多队列哈希算法。我们的配置步骤如下:
receiver$ ethtool -n eth2 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
这便是对于IPv4的UDP数据包,网卡将会对 源IP、目的IP进行哈希,例如:
RX_queue_number = hash('192.168.254.30', '192.168.254.1') % number_of_queues
这个是相当有局限性的一种算法。许多网卡可以自定义哈希算法。所以我们可以用ethtool 把哈希算法的输入改成 源IP、目的IP、源端口、目的端口:
receiver$ ethtool -N eth2 rx-flow-hash udp4 sdfn
Cannot change RX network flow hashing options: Operation not supported
But,不幸的是,我们的网卡不支持这种模式,所以我们这里只能采用对源IP、目的IP进行哈希的算法。
NUMA对于性能的影响
目前为止,我们的数据包只使用了一个RX queue和一个CPU。我们正好利用这次机会讨论一下NUMA对于性能的影响。在我们的receiver主机上有两组独立的CPU,每一组都属于一个独立的
NUMA node Non-uniform memory access.
我们可以把我们的单线程receiver绑定到4个我们感兴趣的CPU中的一个。4个选项如下:
把receiver运行在和RX queue同一个NUMA node,但是不同的CPU上。我们观测到的性能大概是 360kpps。
把receiver运行在和RX queue同一个CPU上,我们可以得到 430kpps的性能峰值。但是波动很大。当网卡被数据包打满的时候性能会跌到0。
把receiver运行在处理RX queue的CPU的HT对应的逻辑核上,性能会是平时性能的一半左右:200kpps。
把receiver运行在和处理RX queue不同的NUMA node上,性能大概是 330kpps,但是数值不太稳定。
这么看来,运行在不同NUMA node上带来的10%的性能损失不是很大,损失似乎是成比例的。在某些试验中,我们只能从每个核上压榨出 250kpps的性能极限。跨NUMA node带来的性能影响只有在更高的吞吐量的情况下才会变得更加明显。在某一次测试中我们把receiver运行在一个比较差的NUMA node上,性能损失了4倍左右。
3. 多个接受端IP
由于我们的网卡的哈希算法非常局限,想要把数据包分布到多个RX queue上的唯一方法就是使用多个IP地址。下面就是我们实际操作的方法:
sender$ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321
ethtool 可以用来查看各个RX queue的状态
receiver$ watch 'sudo ethtool -S eth2 |grep rx'
rx-0.rx_packets: 8.0/s
rx-1.rx_packets: 0.0/s
rx-2.rx_packets: 0.0/s
rx-3.rx_packets: 355.2k/s
rx-4.rx_packets: 0.5/s
rx-5.rx_packets: 297.0k/s
rx-6.rx_packets: 0.0/s
rx-7.rx_packets: 0.5/s
rx-8.rx_packets: 0.0/s
rx-9.rx_packets: 0.0/s
rx-10.rx_packets: 0.0/s
接收端的情况:
receiver$ taskset -c 1 ./udpreceiver1 0.0.0.0:4321
0.609M pps 18.599MiB / 156.019Mb
0.657M pps 20.039MiB / 168.102Mb
0.649M pps 19.803MiB / 166.120Mb
哈哈!用两个核去处理多个RX queue,用第三个去运行我们的receiver,我们可以达到 ~650kpps!
我们可以简单地通过把数据发送给3个、甚至4个RX queue去增加吞吐量,但是很快我们就会触碰到另外一个瓶颈。这个时候的表现是rx_nodesc_drop_cnt 不再提升,但是 netstat 的"receiver errors”在增加:
receiver$ watch 'netstat -s --udp'
Udp:
437.0k/s packets received
0.0/s packets to unknown port received.
386.9k/s packet receive errors
0.0/s packets sent
RcvbufErrors: 123.8k/s
SndbufErrors: 0
InCsumErrors: 0
这就表明,网卡可以把数据持续不断的发送给内核,但是内核没能把所有数据包发送给receiver程序。在我们的场景下,内核只能把 440kpps的数据包发送成功,剩下的 390kpps + 123kpps 就被丢弃了,原因在于receiver没有足够的快的接受速度。
4. 多线程receiver
我们需要扩展我们的receiver。我们最原始的实现,在多线程情况下工作的不理想:
sender$ taskset -c 1,2 ./udpsender 192.168.254.1:4321 192.168.254.2:4321
receiver$ taskset -c 1,2 ./udpreceiver1 0.0.0.0:4321 2
0.495M pps 15.108MiB / 126.733Mb
0.480M pps 14.636MiB / 122.775Mb
0.461M pps 14.071MiB / 118.038Mb
0.486M pps 14.820MiB / 124.322Mb
和单线程的receiver相比,我们的多线程版反而有所下降。这其中的原因在于,在UDP接受缓存上有锁的争抢。两个线程在使用同一个socket文件描述符,它们都花费了相当大比例的时间在激烈争抢UDP接收缓存的锁上。这篇论文更详细的描述了这类问题的细节:
http://www.jcc2014.ucm.cl/jornadas/WORKSHOP/WSDP%202014/WSDP-4.pdf。
在多线程中使用一个文件描述符去接收数据是很糟糕的实现方式。
5. SO_REUSEPORT
幸好,现在针对这个问题有了一个解决方案:The SO_REUSEPORT socket option [LWN.net]。当SO_REUSEPORT这个flag在socket上被标记打开,Linux将会允许多个进程同事绑定在同一个端口上。所以我们可以启动任意数量的进程绑定在同一个端口上,这样这个端口的负载将会在它们之间得到均衡。(译者注:其实没有原作者说的这么复杂,bind、listen完fork就可以实现类似效果,nginx上早就用滥了)
在 SO_REUSEPORT 的帮助下每个进程将会有自己独立的socket文件描述符。这样,它们就会有自己独立的UDP接收缓存。这就避免了我们之前遇到的抢锁的问题。
receiver$ taskset -c 1,2,3,4 ./udpreceiver1 0.0.0.0:4321 4 1
1.114M pps 34.007MiB / 285.271Mb
1.147M pps 34.990MiB / 293.518Mb
1.126M pps 34.374MiB / 288.354Mb
这就对了,现在的吞吐量总算像回事了。
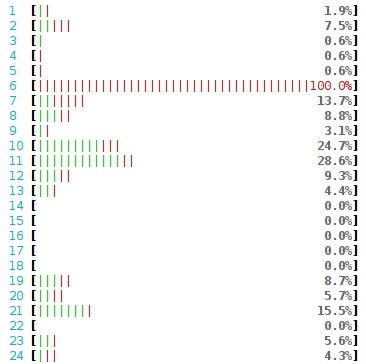
其实做到这里,我们的程序还是有进一步的提升空间的。如下图所示,四个线程的负载并不均衡:

两个线程把所有的包处理了,另外两个线程没有收到任何的数据包。这里的原因在于“哈希碰撞”,但这次是 SO_REUSEPORT 这个层面导致的。
后记
我做了进一步的测试,在RX queue和receiver线程完美对齐在同一个NUMA node的情况下,我们可以达成 1.4Mpps的吞吐量,把receiver运行在不同的NUMA node上最好成绩会下滑到 1Mpps。
总结一下,如果你想达到完美的性能表现,需要做的事情有:
确保流量平均分布在多个RX queue上,在每个进程上启用SO_REUSEPORT。在实践中,由于连接数会非常的多,负载一般都会较为均衡的分布在多个进程上。
需要有足够的CPU资源从内核中读取数据包。
为了达到更高的吞吐,RX queue和receiver需要在同一个NUMA node上。
由于我们上面做的都是技术探索,接受的进程甚至连接受的数据包“看都没看一眼”,这样才在一台Linux机器上能达成1Mpps的成绩。在实际的程序中由于有很多额外的逻辑要做,所以不要指望能达到这个性能。