紧跟着上一节说的文章,虽然已经放出了所写的全代码,但还是再解释一下另外一个页面的请求和分析过程吧。
PS:又可以愉快的水一章了,咕嘿嘿。
页面分析
上回说到下载按钮的href属性是javascript:;伪协议,导致了新打开的页面链接携带#符号,但是我们通过了phantomjs已经解决了第一次跳转的问题。
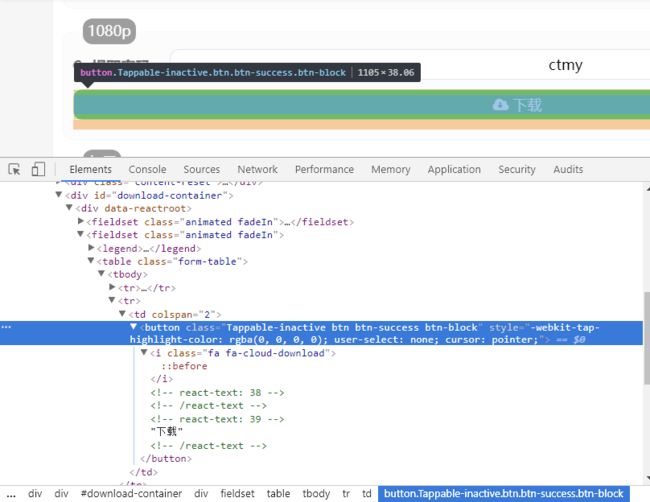
下载页面
事实证明,这里更加狠,连个伪协议都没有。不过没关系,我们还是沿用上回的那个方法,使用phantomjs来渲染页面并且将跳转的页面链接以响应返回给我们的客户端请求。
实现
采用上一节所说的让Phantomjs作为服务端,然后去请求它,让它把要爬取的结果反馈给.net。注意,这里的返回给客户端的响应结果可以是网页页面,也可以是Phantomjs进行HTML解析完的真实数据。
.Net Core代码
public async Task GetDownloadPageAsync(string url)
{
string result = string.Empty;
//请求phantomjs 获取下载页面
string dom = "Tappable-inactive animated fadeIn";
KeyValuePair url2dom = new KeyValuePair(url, dom);
var postData = JsonConvert.SerializeObject(url2dom);
CookieContainer cc = new CookieContainer();
HttpHelpers helper = new HttpHelpers();
HttpItems items = new HttpItems();
HttpResults hr = new HttpResults();
items.Url = this.PostUrl1;
items.Method = "POST";
items.Container = cc;
items.Postdata = postData;
items.Timeout = 100000;
hr = await helper.GetHtmlAsync(items);
var downloadPageUrl = hr.Html;
Console.WriteLine($"first => { downloadPageUrl }");
if(downloadPageUrl.Contains("http"))
{
//获取百度云下载地址和分享密码
//string code1 = "1";
dom = "Tappable-inactive btn btn-success btn-block"; // 下载链接
url2dom = new KeyValuePair(downloadPageUrl, dom);
postData = JsonConvert.SerializeObject(url2dom);
items = new HttpItems
{
Url = this.PostUrl2
};
items.Method = "POST";
items.Container = cc;
items.Postdata = postData;
items.Timeout = 1000000;
hr = await helper.GetHtmlAsync(items);
result = hr.Html; //返回json数据
Console.WriteLine($"second => { result }");
}
else
{
result = downloadPageUrl; //输出错误信息
}
return result;
}
这里包含了第一次在详情页获取下载页的那个请求,以及下载页面获取百度云链接和分享密码的请求。
JavaScript代码
"use strict";
var port = 8089;
var server = require('webserver').create();
server.listen(8089, function (request, response) {
//传入的参数有待更改,目前为
//{"Key":"https://acg12.com/download/#60e21d8417ab60fbfJfcqnT1BC8Qd20PehAIKv3J4ZO%2FJCo0htE9hP5IFZU",
//"Value":"Tappable-inactive btn btn-success btn-block"}的json字符窜
//第一个参数为经过第一次请求所返回的下载页面,第二个为下载按钮的Dom
var data = JSON.parse(request.postRaw);
var url = data.Key.toString();
console.log(url);
var dom = data.Value.toString();
console.log(dom);
var code = 200;
var pwdArray = new Array();
var result = new Array();
var page = require('webpage').create();
page.onInitialized = function() {
page.customHeaders = {};
};
page.settings.loadImages = false;
page.customHeaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36",
"Referer": url
};
response.headers = {
'Cache': 'no-cache',
'Content-Type': 'text/plain',
'Connection': 'Keep-Alive',
'Keep-Alive': 'timeout=40, max=100'
};
//根据Phantomjs的官网,这个回调在打开新标签页会触发
page.onPageCreated = function(newPage) {
//console.log('A new child page was created! Its requested URL is not yet available, though.');
page.onInitialized = function() {
newPage.customHeaders = {};
};
newPage.settings.loadImages = false;
newPage.customHeaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36"
};
//newPage.viewportSize = { width: 1920, height: 1080 };
//当百度云页面打开并渲染完成时触发
newPage.onLoadFinished = function(status) {
//console.log('A child page is Loaded: ' + newPage.url);
//newPage.render('newPage.png', {format: 'png', quality: '100'});
//console.log(pwdArray.length);
if(pwdArray.length > 0){
//console.log("enter");
//从数组中pop出密码,当无密码时pop的数据为null字符窜
var temp = {"url": newPage.url.toString(), "password": pwdArray.pop().toString()};
console.log(JSON.stringify(temp));
result.push(temp); // 将json数据push进返回结果
}
};
};
page.open(url, function (status) {
console.log("----" + status);
if (status !== 'success') {
code = 400;
response.write('4XX');
response.statusCode = code;
response.close();
} else {
code = 200;
window.setTimeout(function (){
//var dom = dom;
pwdArray = page.evaluate(function(dom) {
console.log(dom);
var pwdArray = new Array();
var btnList = document.getElementsByClassName(dom); // 百度云链接
for(var i = 0; i < btnList.length;i ++ ){
//猜测所有下载节点都有密码
var temp = document.getElementById("downloadPwd-" + i);
if(temp != undefined){
//console.log("****" + temp.value);
pwdArray.push(temp.value); // 有密码push进数组
}else{
//console.log("****null");
pwdArray.push("null"); // 无密码则push进null字符窜,这样做到和url的一一对应
}
}
for(var i = 0; i < btnList.length;i ++ ){
//console.log("click");
btnList[i].click(); // 点击下载,打开新标签页
}
return pwdArray;
}, dom);
}, 6000);
}
});
//设置等待20秒后才发送客户端的响应结果,这样保证上述方法都能成功运行结束
window.setTimeout(function(){
var rs = JSON.stringify(result)
console.log(rs);
response.write(rs);
response.statusCode = code;
response.close();
}, 20000);
page.onConsoleMessage = function(msg, lineNum, sourceId) {
console.log("$$$$$" + msg);
};
page.onError = function(msg, trace) {
var msgStack = ['PHANTOM ERROR: ' + msg];
if (trace && trace.length) {
msgStack.push('TRACE:');
trace.forEach(function(t) {
msgStack.push(' -> ' + (t.file || t.sourceURL) + ': ' + t.line + (t.function ? ' (in function ' + t.function +')' : ''));
});
}
console.log(msgStack.join('\n'));
phantom.exit(1);
};
});
phantom.onError = function(msg, trace) {
var msgStack = ['PHANTOM ERROR: ' + msg];
if (trace && trace.length) {
msgStack.push('TRACE:');
trace.forEach(function(t) {
msgStack.push(' -> ' + (t.file || t.sourceURL) + ': ' + t.line + (t.function ? ' (in function ' + t.function +')' : ''));
});
}
console.log(msgStack.join('\n'));
phantom.exit(1);
};
完整的源代码已经放在Github上了,里面有写好的bat文件,直接运行run.bat就行。当然前提,第一节的那些环境都配置完成了。大家下周见,下周可能可以尝试用用DotnetSpider,这是借鉴了WebMagic写的.net core地爬虫框架,有兴趣的可以先去尝试一下玩玩。
谢谢~~