Java集合类
1.简介:
java集合类包含在java.util包下
集合类存放的是对象的引用,而非对象本身。
集合类型主要分为Set(集),List(列表),Map(映射)。
1.1 java集合类图
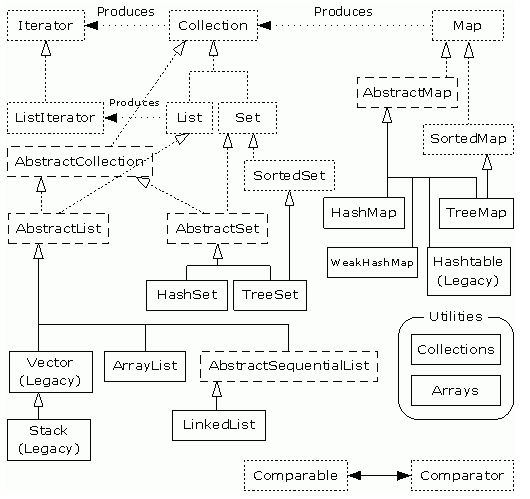
从上述类图,自己整理出主要内容是如下:

2.集合详解
2.1 HashSet
HashSet是Set接口的一个子类
主要的特点是:
- 里面不能存放重复元素,元素的插入顺序与输出顺序不一致
- 采用散列的存储方法,所以没有顺序。
代码实例:HashSetTest
package cn.swum;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class HashSetTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("f");
//插入重复元素,测试set是否可以存放重复元素
set.add("a");
set.add(null);
//插入重复null,看结果是否可以存放两个null
set.add(null);
Iterator iter = set.iterator();
System.out.println("输出的排列顺序为:");
while (iter.hasNext()){
System.out.println( iter.next());
}
}
}
输出结果:
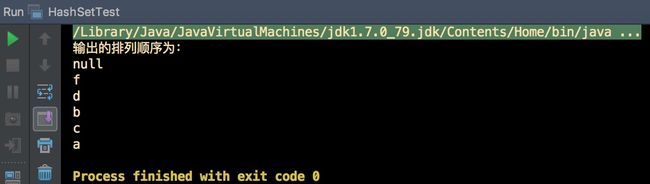
小结:
HashSet存放的值无序切不能重复,可以存放null,但只能存放一个null值
HashSet 继承AbstractSet,有两个重要的方法,其中HashCode()和equals()方法,当对象被存储到HashSet当中时,会调用HashCode()方法,获取对象的存储位置。
HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相等。
2.2 LinkedHashSet
- LinkedHashSet是HashSet的一个子类
- 只是HashSet底层用的HashMap,
而LinkedHashSet底层用的LinkedHashMap
LinkedHashSet代码实例:
package cn.swum;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetTest {
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
set.add("e");
System.out.println("LinkedHashSet存储值得排序为:");
for (Iterator iter = set.iterator();iter.hasNext();){
System.out.println(iter.next());
}
}
}
输出结果:
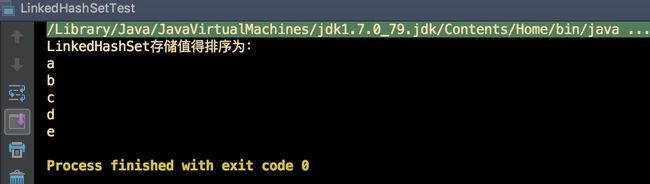
小结:
此时,LinkedHashSet中的元素是有序的
2.3 SortedSet(接口)
- SortedSet是一个接口,里面(只有TreeSet这一个实现可用)的元素一定是有序的。
- 保证迭代器按照元素递增顺序遍历的集合,
可以按照元素的自然顺序(参见 Comparable)进行排序, 或者按照创建有序集合时提供的 Comparator进行排序
其源码如下:
public interface SortedSet extends Set {
//返回与此有序集合关联的比较器,如果使用元素的自然顺序,则返回 null。
Comparator comparator();
//返回此有序集合的部分元素,元素范围从 fromElement(包括)到 toElement(不包括)。
SortedSet subSet(E fromElement, E toElement);
//用一个SortedSet, 返回此有序集合中小于end的所有元素。
SortedSet headSet(E toElement);
//返回此有序集合的部分元素,其元素大于或等于 fromElement。
SortedSet tailSet(E fromElement);
//返回此有序集合中当前第一个(最小的)元素。
E first();
//返回此有序集合中最后一个(最大的)元素
E last();
}
2.4 TreeSet
TreeSet类实现Set 接口,该接口由TreeMap 实例支持,此类保证排序后的 set 按照升序排列元素,
根据使用的构造方法不同,可能会按照元素的自然顺序 进行排序(参见 Comparable或按照在创建 set 时所提供的比较器进行排序。Set 接口根据 equals 操作进行定义,但 TreeSet 实例将使用其 compareTo(或 compare)方法执行所有的键比较
代码实例TreeSetTest:
package cn.swum;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetTest {
static class Person{
int id;
String name;
int age;
public Person(int id, String name, int age){
this.id = id;
this.name = name;
this.age = age;
}
public String toString(){
return "id:"+ this.id + " " + "name:" + this.name +" " + "age:" + this.age;
}
}
static class MyComparator implements Comparator {
@Override
public int compare(Person p1, Person p2) {
if(p1 == p2) {
return 0;
}
if(p1 != null && p2 == null) {
return 1;
}else if(p1 == null && p2 != null){
return -1;
}
if(p1.id > p2.id){
return 1;
}else if(p1.id < p2.id){
return -1;
}
return 0;
}
}
public static void main(String[] args) {
MyComparator myComparator = new MyComparator();
TreeSet treeSet = new TreeSet<>(myComparator);
treeSet.add(new Person(3,"张三",20));
treeSet.add(new Person(2,"王二",22));
treeSet.add(new Person(1,"赵一",18));
treeSet.add(new Person(4,"李四",29));
//增加null空对象
treeSet.add(null);
System.out.println("TreeSet的排序是:");
for (Person p : treeSet){
if(p == null){
System.out.println(p);
}else {
System.out.println(p.toString());
}
}
}
}
实例用TreeSet保存对象引用,并且实现Comparator中compare方法进行比较和排序
输出结果:
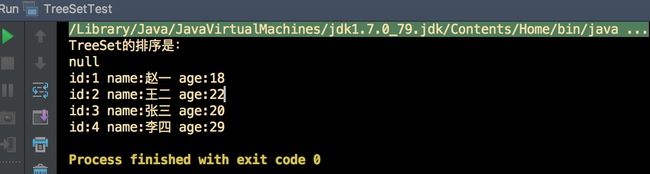
- 表明TreeSet是可以按照自定义方法中的比较进行排序的,且可以有空值。
2.5 Vector
- Vector 类也是基于数组实现的队列,代码与ArrayList非常相似。
- 线程安全,执行效率低。
- 动态数组的增长系数
- 由于效率低,并且线程安全也是相对的,因此不推荐使用vector
2.6 Stack
Stack 是继承了Vector,是一个先进后出的队列
Stack里面主要实现的有一下几个方法:
| 方法名 | 返回类型 | 说明 |
|---|---|---|
| empty | boolean | 判断stack是否为空 |
| peek | E | 返回栈顶端的元素 |
| pop | E | 弹出栈顶的元素 |
| push | E | 将元素压入栈 |
| search | int | 返回最靠近顶端的目标元素到顶端的距离 |
代码实例StackTest:
package cn.swum;
import java.util.Stack;
public class StackTest {
static class Person{
int id;
String name;
int age;
public Person(int id, String name, int age){
this.id = id;
this.name = name;
this.age = age;
}
public String toString(){
return "id:"+ this.id + " " + "name:" + this.name +" " + "age:" + this.age;
}
}
public static void main(String[] args) {
Stack stack = new Stack();
stack.push(new Person(1,"赵一",18));
stack.push(new Person(2,"王二",19));
stack.push(new Person(3,"张三",20));
stack.push(new Person(4,"李四",21));
System.out.println("栈顶元素是:(" + stack.peek() + ")");
System.out.println("目标元素离栈顶多少距离:" + stack.search(stack.get(0)));
System.out.println("栈元素从栈顶到栈底的排序是:");
//此处先用size保存是因为pop时,size会减1,
// 如果直接stack.size放在循环中比较,只能打印一半对象
int size = stack.size();
for (int i = 0; i < size ; i++) {
Person p = (Person) stack.pop();
System.out.println(p.toString());
}
}
}
输出结果:
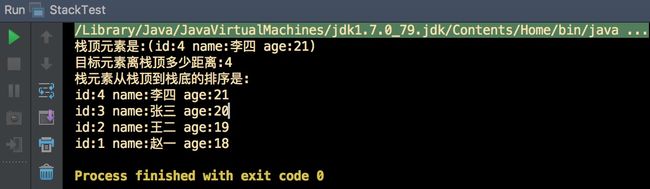
- Stack 是一个有序的栈,遵循先进后出原则。
2.7 ArrayList
ArrayList是List的子类,它和HashSet相反,允许存放重复元素,因此有序。
集合中元素被访问的顺序取决于集合的类型。
如果对ArrayList进行访问,迭代器将从索引0开始,每迭代一次,索引值加1。
然而,如果访问HashSet中的元素,每个元素将会按照某种随机的次序出现。
虽然可以确定在迭代过程中能够遍历到集合中的所有元素,但却无法预知元素被访问的次序。
代码实例:ArrayListTest
package cn.swum;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class ArrayListTest {
public static void main(String[] args) {
List arrayList = new ArrayList();
arrayList.add("a");
arrayList.add("b");
arrayList.add("c");
//添加重复值
arrayList.add("a");
arrayList.add("d");
arrayList.add("e");
//添加null
arrayList.add(null);
System.out.println("arrayList的输出顺序为:");
for (int i = 0; i < arrayList.size(); i++) {
System.out.println((i+1) + ":" +arrayList.get(i));
}
}
}
输出结果:

- ArrayList是一个有序且允许重复和空值的列表
2.8 LinkedList
LinkedList是一种可以在任何位置进行高效地插入和删除操作的有序序列。
代码实例:LinkedListTest
package cn.swum;
import java.util.LinkedList;
/**
* @author long
* @date 2017/2/28
*/
public class LinkedListTest {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.add("a");
linkedList.add("b");
linkedList.add("c");
linkedList.add("d");
linkedList.add("e");
linkedList.add(2,"2");
System.out.println("linkedList的输出顺序是:" + linkedList.toString());
linkedList.push("f");
System.out.println("push后,linkedList的元素顺序:" + linkedList.toString());
linkedList.pop();
System.out.println("pop后,linkedList的所剩元素:" + linkedList.toString());
}
}
输出结果:

- LinkedList是有序的双向链表,可以在任意时刻进行元素的插入与删除,读取效率低于ArrayList,插入效率高
- pop和push操作都是在队头开始
2.9 HashMap
- HashMap的数据结构:
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
哈希表结合了两者的优点。
哈希表有多种不同的实现方法,可以理解将此理解为“链表的数组”
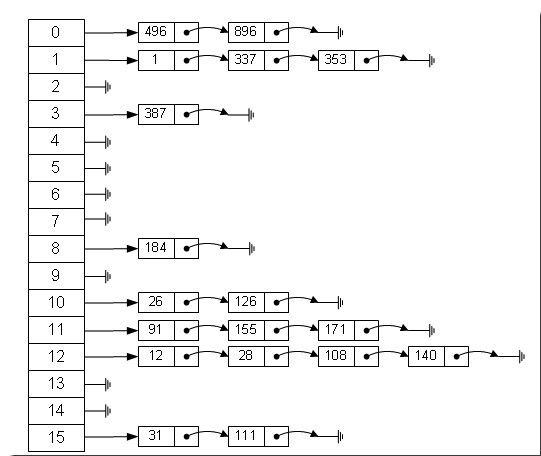
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中:
12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。然后每个线性的数组下存储一个链表,链接起来。首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean.我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
HashMap的存取实现:
//存储时:
int hash = key.hashCode();// 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
//取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
- 疑问:如果两个key通过hash%Entry[].length得到的index相同,会不会有覆盖的危险?
这里HashMap里面用到链式数据结构的一个概念。上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。打个比方,第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?
HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起。所以疑问不用担心。也就是说数组中存储的是最后插入的元素。
HashMapTest代码实例,自我实现HashMap:
Entry.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class Entry {
final K key;
V value;
Entry next;//下一个结点
//构造函数
public Entry(K k, V v, Entry n) {
key = k;
value = v;
next = n;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Entry))
return false;
Entry e = (Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
MyHashMap.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class MyHashMap{
private Entry[] table;//Entry数组表
static final int DEFAULT_INITIAL_CAPACITY = 16;//默认数组长度
private int size;
// 构造函数
public MyHashMap() {
table = new Entry[DEFAULT_INITIAL_CAPACITY];
size = DEFAULT_INITIAL_CAPACITY;
}
//获取数组长度
public int getSize() {
return size;
}
// 求index
static int indexFor(int h, int length) {
return h % (length - 1);
}
//获取元素
public V get(Object key) {
if (key == null)
return null;
int hash = key.hashCode();// key的哈希值
int index = indexFor(hash, table.length);// 求key在数组中的下标
for (Entry e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k)))
return e.value;
}
return null;
}
// 添加元素
public V put(K key, V value) {
if (key == null)
return null;
int hash = key.hashCode();
int index = indexFor(hash, table.length);
// 如果添加的key已经存在,那么只需要修改value值即可
for (Entry e = table[index]; e != null; e = e.next) {
Object k = e.key;
if (e.key.hashCode() == hash && (k == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;// 原来的value值
}
}
// 如果key值不存在,那么需要添加
Entry e = table[index];// 获取当前数组中的e
table[index] = new Entry(key, value, e);// 新建一个Entry,并将其指向原先的e
return null;
}
}
MyHashMapTest.java
package cn.swum.cn.swun.hash;
/**
* @author long
* @date 2017/2/28
*/
public class MyHashMapTest {
public static void main(String[] args) {
MyHashMap map = new MyHashMap();
map.put(1, 90);
map.put(2, 95);
map.put(17, 85);
System.out.println(map.get(1));
System.out.println(map.get(2));
System.out.println(map.get(17));
System.out.println(map.get(null));
}
}
输出结果:

2.10 WeekHashMapTest
package cn.swum.cn.swun.hash;
import java.util.WeakHashMap;
/**
* @author long
* @date 2017/2/28
*/
public class WeekHashMapTest {
public static void main(String[] args) {
int size = 10;
if (args.length > 0) {
size = Integer.parseInt(args[0]);
}
Key[] keys = new Key[size];
WeakHashMap whm = new WeakHashMap();
for (int i = 0; i < size; i++) {
Key k = new Key(Integer.toString(i));
Value v = new Value(Integer.toString(i));
if (i % 3 == 0) {
keys[i] = k;//强引用
}
whm.put(k, v);//所有键值放入WeakHashMap中
}
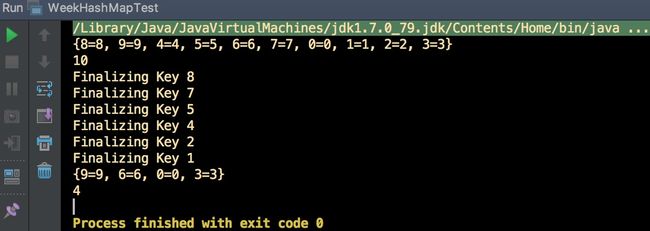
System.out.println(whm);
System.out.println(whm.size());
System.gc();
try {
// 把处理器的时间让给垃圾回收器进行垃圾回收
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(whm);
System.out.println(whm.size());
}
}
class Key {
String id;
public Key(String id) {
this.id = id;
}
public String toString() {
return id;
}
public int hashCode() {
return id.hashCode();
}
public boolean equals(Object r) {
return (r instanceof Key) && id.equals(((Key) r).id);
}
public void finalize() {
System.out.println("Finalizing Key " + id);
}
}
class Value {
String id;
public Value(String id) {
this.id = id;
}
public String toString() {
return id;
}
public void finalize() {
System.out.println("Finalizing Value " + id);
}
}
输出结果:
2.11 HashTable与HashMap的区别
- HashTable和HashMap存在很多的相同点,但是他们还是有几个比较重要的不同点。
我们从他们的定义就可以看出他们的不同,HashTable基于Dictionary类,而HashMap是基于AbstractMap。Dictionary是什么?它是任何可将键映射到相应值的类的抽象父类,而AbstractMap是基于Map接口的骨干实现,它以最大限度地减少实现此接口所需的工作。
HashMap可以允许存在一个为null的key和任意个为null的value,但是HashTable中的key和value都不允许为null。如下:当HashMap遇到为null的key时,它会调用putForNullKey方法来进行处理。对于value没有进行任何处理,只要是对象都可以。
Hashtable的方法是同步的,而HashMap的方法不是。所以有人一般都建议如果是涉及到多线程同步时采用HashTable,没有涉及就采用HashMap,但是在Collections类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的Map对象,并把它作为一个封装的对象来返回,所以通过Collections类的synchronizedMap方法是可以我们你同步访问潜在的HashMap。
遍历不同:HashMap仅支持Iterator的遍历方式,Hashtable支持Iterator和Enumeration两种遍历方式。