
引言
在多线程编程出现之前,电脑程序的运行由一个执行序列组成,执行序列按顺序在主机的CPU中运行。无论是任务本身要求顺序执行还是整个程序是由多个子任务组成,程序都是按这种方式执行的。即使子任务相当独立,相互无关(即,一个子任务的结果不影响其他子任务的结果)。这样并行处理可以大幅度地提升整个任务的效率,这也就是多线程编程的目的。
什么是线程
线程(有时被称为轻量级进程)跟进程有些相似,不同的是,所有的线程运行在同一个进程,共享相同的运行环境。
线程有开始,顺序执行和结束三部分。它有自己的指令指针,记录自己运行到什么地方。线程的运行可能被抢占(中断),或暂时挂起(也叫睡眠),让其他的线程运行(也叫让步)。一个进程中的各个进程之前共享同一片数据空间,所以线程之间可以比进程之间更方便的共享数据和之间的互相通讯。
全局解释器锁(GIL)
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到在主循环中,同时只有一个线程在运行,就像在单CPU的系统中运行多个进程那样,尽管在内存中可以存放多个程序,但是在任意时刻,只有一个程序在CPU中运行。
对于Python虚拟机的访问由GIL来控制,正是这个锁能保证同一时刻只有一个线程在运行。在多线程的环境中,Python虚拟机按一下方式运行:
- 设置GIL
- 切换到一个线程中运行
- 运行: a. 指定数量的字节码的指令,或者线程主动让出控制(可以调用time.sleep(0))
- 把线程设置为睡眠状态
- 解锁GIL
- 重复以上所用步骤
编写扩展程序的程序员可以主动解锁GIL,不过Python的开发人员则不用担心在这个情况下你的Python代码会被锁住。
例如,对所有面向I/O的程序来说,GIL会在这个I/O调用之前被释放,以允许其他的线程在这个线程等待I/O的时候允许。如何某线程并未使用很多I/O操作,它会在自己的时间片内一直占用CPU和GIL,也就是说,I/O密集型的Python程序比计算密集型的程序更能充分利用多线程环境的好处
没有线程支持的情况
示例1
在单线程中顺序执行两个循环。一个循环结束后,另一个才能开始。总的时间是各个循环运行的时间之和。
#!/usr/bin/env python
from time import sleep, ctime
def loop0():
print 'start loop0 at: ', ctime()
sleep(4)
print 'loop0 done at: ', ctime()
def loop1():
print 'start loop1 at: ', ctime()
sleep(2)
print 'loop1 done at: ', ctime()
def main():
print 'starting at: ', ctime()
loop0()
loop1()
print 'all Done at: ', ctime()
if __name__ == '__main__':
main()
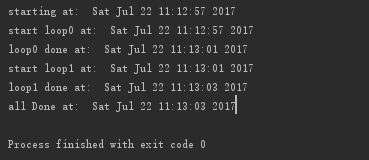
执行结果:loop0和loop1各自运行了4秒和2秒,整个程序耗时6秒,属于串行执行
Python的threading模块
Python提供了几个用于多线程编程的模块,包括thread,threading和Queue等。
- thread模块提供了基本的线程和锁的支持
- threading提供了更高级、功能更强的线程管理的功能
- Queue模块允许用户创建一个可以用于多个线程之间共享数据的队列数据结构。
示例2
#!/usr/bin/env python
import thread
from time import sleep, ctime
def loop0():
print 'start loop 0 at: ', ctime()
sleep(4)
print 'loop 0 done at: ', ctime()
def loop1():
print 'start loop1 at: ', ctime()
sleep(2)
print 'loop1 done at: ', ctime()
def main():
print 'starting at: ', ctime()
#start_new_thread()要求一定要有前两个参数,就算运行的函数不需要传参,也要传一个空元组
thread.start_new_thread(loop0,())
thread.start_new_thread(loop1,())
#睡6秒来确保2个子线程都运行结束,防止主线程过早退出
sleep(6)
print 'all Done at: ', ctime()
if __name__ == '__main__':
main()
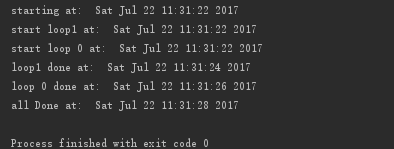
执行结果:loop0和loop1并行执行,2个函数执行耗时4秒
示例3
使用线程和锁
引入锁的概念是为了线程不用什么时候结束再做额外的等待,使用了锁,我们就可以在两个线程都退出后,马上退出。(线程管理)
#!/usr/bin/env python
import thread
from time import sleep, ctime
loops = [4, 2]
def loop(nloop, nsec, lock):
print 'start loop', nloop, 'at: ',ctime()
sleep(nsec)
print 'loop',nloop,'done at: ',ctime()
lock.release()
def main():
print 'starting at: ', ctime()
locks = []
nloops = range(len(loops))
for i in nloops:
lock = thread.allocate_lock()
lock.acquire()
locks.append(lock)
for i in nloops:
thread.start_new_thread(loop, (i, loops[i], locks[i]))
for i in nloops:
while locks[i].locked():
pass
print 'all Done at: ', ctime()
if __name__ == '__main__':
main()
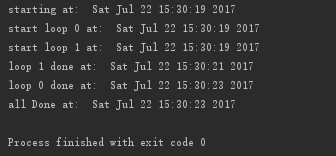
执行结果:
示例4
使用threading模块的Thread类的一个join(),允许主线程等待子线程的结束
#!/usr/bin/env python
import threading
from time import sleep, ctime
loops = [4,2]
def loop(nloop, nsec):
print 'start loop', nloop, 'at: ',ctime()
sleep(nsec)
print 'loop',nloop,'done at: ',ctime()
def main():
print 'starting at: ', ctime()
threads = []
nloops = range(len(loops))
for i in nloops:
t = threading.Thread(target=loop, args=(i, loops[i]))
threads.append(t)
for i in nloops: #start thread
threads[i].start()
for i in nloops: #wait for all
threads[i].join() #threads to finish
print ' all Done at: ', ctime()
if __name__ == '__main__':
main()
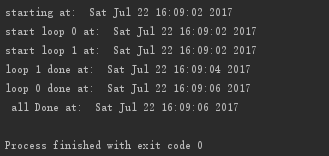
执行结果: 所有的线程先都创建好之后,再一起调用start()函数启动,而不是创建一个启动一个,而且不需要在管理一堆锁(分配锁、获得锁、释放锁、检查锁等),只需简单地对每个线程调用join()函数就可以了。
示例5
线程池threadpool模块
import time
from multiprocessing.dummy import Pool as ThreadPool
def printhello(str):
print "Hello ", str
time.sleep(2)
name_list =['world1', 'world2', 'world3', 'world4']
start_time = time.time()
pool = ThreadPool(10)
pool.map(printhello, name_list)
pool.close()
pool.join()
end_time = time.time()
print '%d second'% (end_time-start_time)
示例6
多线程爬取京东手机信息
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import time
import json
import requests
from lxml import etree
from pymongo import MongoClient
from multiprocessing.dummy import Pool as ThreadPool
reload(sys)
sys.path.append('..')
sys.setdefaultencoding('utf-8')
def request_html(url):
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
goodslist = selector.xpath('//ul[@class="gl-warp clearfix"]/li')
for goods in goodslist:
try:
sku_id = goods.xpath('@data-sku')[0]
comment_url = 'https://item.jd.com/{}.html'.format(str(sku_id))
get_comment_data(comment_url)
except Exception as e:
print e
def get_comment_data(url):
dict = {}
html = requests.get(url, headers=headers)
selector = etree.HTML(html.text)
product_infos = selector.xpath('//ul[@class="parameter2 p-parameter-list"]')
for product in product_infos:
product_name = product.xpath('li[1]/@title')[0]
product_number = product.xpath('li[2]/@title')[0]
product_price = get_product_price(product_number)
gross_weight = product.xpath('li[4]/@title')[0]
commodity_origin = product.xpath('li[3]/@title')[0]
dict["商品名称"] = product_name
dict["价格"] = product_price
dict["商品编号"] = product_number
dict["毛重"] = gross_weight
dict["产地"]=commodity_origin
save_to_mongodb(dict)
def get_product_price(sku): #直接xpath提取价格信息返回null,价格是js加载的
url = "https://p.3.cn/prices/mgets?&skuIds=J_%s" %str(sku)
html = requests.get(url, headers=headers).content
html_json = json.loads(html)
for info in html_json:
return info.get('p')
def save_to_mongodb(list):
client = mongoclient
db = client['goods']
posts = db.jd
posts.insert(list)
if __name__ == '__main__':
headers = {
'Cookie': 'ipLoc-djd=1-72-2799-0; unpl=V2_ZzNtbRZXF0dwChEEfxtbV2IKFQ4RUBcSdg1PVSgZCVAyCkBVclRCFXMUR1NnGFkUZgoZXkpcQxNFCHZXchBYAWcCGllyBBNNIEwHDCRSBUE3XHxcFVUWF3RaTwEoSVoAYwtBDkZUFBYhW0IAKElVVTUFR21yVEMldQl2VH4RWAVmBxVeS19AEHUJR1x6GFsBYQEibUVncyVyDkBQehFsBFcCIh8WC0QcdQ1GUTYZWQ1jAxNZRVRKHXYNRlV6EV0EYAcUX3JWcxY%3d; __jdv=122270672|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_e1ec43fa536c486bb6e62480b1ddd8c9|1496536177759; mt_xid=V2_52007VwMXWllYU14YShBUBmIDE1NVWVNdG08bbFZiURQBWgxaRkhKEQgZYgNFV0FRVFtIVUlbV2FTRgJcWVNcSHkaXQVhHxNVQVlXSx5BEl0DbAMaYl9oUmofSB9eB2YGElBtWFdcGA%3D%3D; __jda=122270672.14951056289241009006573.1495105629.1496491774.1496535400.5; __jdb=122270672.26.14951056289241009006573|5.1496535400; __jdc=122270672; 3AB9D23F7A4B3C9B=EJMY3ATK7HCS7VQQNJETFIMV7BZ5NCCCCSWL3UZVSJBDWJP3REWXTFXZ7O2CDKMGP6JJK7E5G4XXBH7UA32GN7EVRY; __jdu=14951056289241009006573',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
urls = ['https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page={}&click=0'.format(str(i)) for i in range(1, 200, 2)]
mongoclient = MongoClient('mongodb://172.16.110.163:27017/')
pool = ThreadPool(4)
start = time.time()
pool.map(request_html, urls)
pool.close()
pool.join()
end = time.time()
print 'Total Time:' + str(end - start) + 's'
