参考
java提高篇(二三)-----HashMap
HashMap vs. TreeMap vs. Hashtable vs. LinkedHashMap
Java之美[从菜鸟到高手演变]之HashMap、HashTable
hashmap方法摘要
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。而链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。有没有一种数据结构来综合一下 数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”,如下图:
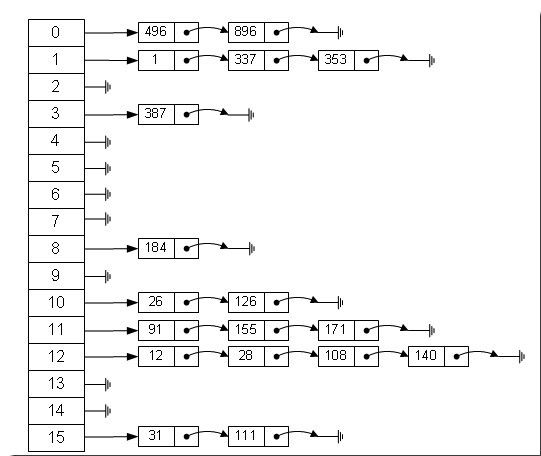 数组里全是链表结构
数组里全是链表结构
从上图中,我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则 存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表 中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。它 的内部其实是用一个Entity数组来实现的,属性有key、value、next。
一、HashMap内部结构
1、初始化
static final int DEFAULT_INITIAL_CAPACITY = 16;// 初始容量:16
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量:2的30次方:1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f; //装载因子,后面再说它的作用
其中Entry为HashMap的内部类,它包含了键key、值value、下一个节点next,以及hash值,这是非常重要的,正是由于Entry才构成了table数组的项为链表。
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
}
2.构造方法
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY]; //默认开辟16个
init();
}
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
capacity <<= 1表示实际的开辟的空间要大于传入的第一个参数的值。举个例子:new HashMap(7,0.8),loadFactor为0.8,capacity为7,通过上述代码后,capacity的值为:8.(1 << 2的结果是2,2 << 2的结果为4)。所以,最终capacity的值为8,最后通过new Entry[capacity]来创建大小为capacity的数组。
3.put操作
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table
//第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode()); ------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2)
//从i出开始迭代 e,找到 key 保存的位置
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
static int indexFor(int h, int length) {
return h & (length-1);
}
就是说,获取Entry的第一个元素table[0],并基于第一个元素的next属性开始遍历,直到找到key为null的Entry,将其value设置为新的value值。如果没有找到key为null的元素,则调用如上述代码的addEntry(0, null, value, 0);增加一个新的entry,代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
先获取第一个元素table[bucketIndex],传给e对象,新建一个entry,key为null,value为传入的value值,next为获取的e对象。如果容量大于threshold,容量扩大2倍。如果key不为null,这也是大多数的情况,重新看一下源码:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());//---------------2---------------
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {//--------------3-----------
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}//-------------------4------------------
modCount++;//----------------5----------
addEntry(hash, key, value, i);-------------6-----------
return null;
}
看源码中2处,首先会进行key.hashCode()操作,获取key的哈希值,hashCode()是Object类的一个方法,为本地方法,内部实现比较复杂,我们会在后面作单独的关于Java中Native方法的分析中介绍。hash()的源码如下:
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
int i = indexFor(hash, table.length);的意思,相当于int i = hash % Entry[].length;得到i后,就是在Entry数组中的位置,上述代码5和6处是如果Entry数组中不存在新要增加的元素,则执行5,6处的代码,如果存在,即Hash冲突,则执行 3-4处的代码,此处HashMap中采用链地址法解决Hash冲突。具体方法可以解释为下面的这段文字:
上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。如, 第一个键值对A进来,通过计算其key的hash得到的i=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其i也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,i也等于0,那么C.next = B,Entry[0] = C;这样我们发现i=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起,也就是说数组中存储的是最后插入的元素。
到这里为止,HashMap的大致实现,我们应该已经清楚了。当然HashMap里面也包含一些优化方面的实现,这里也说一下。比 如:Entry[]的长度一定后,随着map里面数据的越来越长,这样同一个i的链就会很长,会不会影响性能?HashMap里面设置一个因素(也称为因子),随着map的size越来越大,Entry[]会以一定的规则加长长度。
4.get操作
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
意思就是:当key为null时,调用getForNullKey(),源码如下:
private V getForNullKey() {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
当key不为null时,先根据hash函数得到hash值,在更具indexFor()得到i的值,循环遍历链表,如果有:key值等于已存在的key值,则返回其value。如上述get()代码1处判断。
总结下HashMap新增put和获取get操作:
//存储时:
int hash = key.hashCode();
int i = hash % Entry[].length;
Entry[i] = value;
//取值时:
int hash = key.hashCode();
int i = hash % Entry[].length;
return Entry[i];
5.遍历
参考
简单分析Java的HashMap.entrySet()的实现
keySet 与entrySet 遍历HashMap性能差别
对于keySet其实是遍历了2次,一次是转为iterator,一次就从hashmap中取出key所对于的value。而entryset只是遍历了第一次,他把key和value都放到了entry中,所以就快了。
(1)keySet
Iterator keySetIterator =
keySetMap.keySet().iterator();
while (keySetIterator.hasNext()) {
String key = keySetIterator.next();
String value = keySetMap.get(key);
}
(2)entrySet
Iterator> entryKeyIterator =
entrySetMap.entrySet().iterator();
while (entryKeyIterator.hasNext()) {
Entry e = entryKeyIterator.next();
String value=e.getValue();
}
entrySet()方法返回的是一个特殊的Set,定义为HashMap的内部私有类
private final class EntrySet extends AbstractSet>
HashMap的entrySet()方法返回一个特殊的Set,这个Set使用EntryIterator遍历,而这个Iterator则直接操作于HashMap的内部存储结构table上。通过这种方式实现了“视图”的功能。整个过程不需要任何辅助存储空间。从这一点也可以看出为什么entrySet()是遍历HashMap最高效的方法,原因很简单,因为这种方式和HashMap内部的存储方式是一致的。
二、hashmap hashtable treemap
Java SE中有四种常见的Map实现——HashMap, TreeMap, Hashtable和LinkedHashMap。如果我们使用一句话来分别概括它们的特点,就是:
- HashMap就是一张hash表,键和值都没有排序。
- TreeMap以红-黑树结构为基础,键值按顺序排列。
参考红黑树(一)之 原理和算法详细介绍 - LinkedHashMap保存了插入时的顺序。参考【Java集合源码剖析】LinkedHashmap源码剖析
- Hashtable是同步的(而HashMap是不同步的)。
public static void main(String args[]){
System.out.println("map");
testHash(new HashMap(),"HashMap");
testHash(new Hashtable(),"Hashtable");
testHash(new TreeMap(),"TreeMap");
}
private static void testHash(Map map,String typeStr){
map.put("a","aaa");
map.put("b","bbb");
map.put("c","ccc");
map.put("d","ddd");
Iterator iterator = map.keySet().iterator();
while(iterator.hasNext()){
Object key = iterator.next();
System.out.println(typeStr+map.get(key));
}
System.out.println("---------");
}
三、如果HashMap的键(key)是自定义的对象,那么需要按规则定义equals和hashCode
- public boolean equals(Object o)
- public int hashCode()
class Dog {
String color;
Dog(String c) {
color = c;
}
public String toString(){
return color + " dog";
}
}
public class TestHashMap {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
Dog d1 = new Dog("red");
Dog d2 = new Dog("black");
Dog d3 = new Dog("white");
Dog d4 = new Dog("white");
hashMap.put(d1, 10);
hashMap.put(d2, 15);
hashMap.put(d3, 5);
hashMap.put(d4, 20);
//print size
System.out.println(hashMap.size());
//loop HashMap
for (Entry entry : hashMap.entrySet()) {
System.out.println(entry.getKey().toString()
+ " - " + entry.getValue());
}
}
}
//结果:
4
white dog - 5
black dog - 15
red dog - 10
white dog - 20
注意,我们错误的将”white dogs”添加了两次,但是HashMap却接受了两只”white dogs”。这不合理(因为HashMap的键不应该重复),我们会搞不清楚真正有多少白色的狗存在。
class Dog {
String color;
Dog(String c) {
color = c;
}
public boolean equals(Object o) {
return ((Dog) o).color == this.color;
}
public int hashCode() {
return color.length();
}
public String toString(){
return color + " dog";
}
}
//现在输出结果如下
3
red dog - 10
white dog - 20
black dog - 15
输出结果如上是因为HashMap不允许有两个相等的元素存在。默认情况下(也就是类没有实现hashCode()和equals()方法时),会使用Object类中的这两个方法。Object类中的hashCode()对于不同的对象会返回不同的整数,而只有两个引用指向的同样的对象时equals()才会返回true。
另外,关于这两个方法,可以参考java中正确使用equals和hashCode
三、hashtable实际使用
1.参考现在搞java的人,还有用vector和hashtable的嘛?
一直很好奇。感觉这俩是只在教科书上出现过的东西。实际中从没见过有人使用。但很多人面试时候总会问这俩东西。如果从深入理解的角度来说了解一下无妨。但是从应用角度来说意义不大。
不需要线程同步有 ArrayList / HashMap,需要线程同步有 java.util.concurrent 的 ConcurrentHashMap / CopyOnWriteArrayList 或者根据代码行为进行手工同步 [1] 。这种被淘汰的东西当然不应该用。
2.嵌套使用
参考java Map集合嵌套,value为Map和value为List
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class MapDemo {
public static void main(String[] args) {
System.out.println("Map集合的值为Map");
oneToMap();
System.out.println("Map集合的值为List,特别常用!必须会!");
oneToList();
}
/*
* 这种是把班级和学生作为映射
* 而且又把学号和姓名做了映射
*/
public static void oneToMap() {
Map> jiSuanJi =
new HashMap>();
Map ruanJian = new HashMap();
Map wangZhan = new HashMap();
/*
* 千万不要每次都new一个进去,这样就不是原来的集合了
* 结果yingyong这个key对应的value集合是null
* 遍历Map的时候还会出现空指针错误
*/
//jiSuanJi.put("yingyong", (Map)
//new HashMap().put("01", "haha"));
//jiSuanJi.put("yingyong", (Map)
//new HashMap().put("02", "xixi"));
/*
* 要使用下面这种方式,先把集合定义好,
* 把映射关系设置好,再去给集合添加元素
*/
jiSuanJi.put("ruanJian", ruanJian);
jiSuanJi.put("wangZhan", wangZhan);
ruanJian.put("01", "zhangsan");
ruanJian.put("02", "lisi");
wangZhan.put("01", "zhaoliu");
wangZhan.put("02", "zhouqi");
Set keySet = jiSuanJi.keySet();
for(Iterator it = keySet.iterator();it.hasNext();) {
String key = it.next();
System.out.println(key);
Map map = jiSuanJi.get(key);
Set> entrySet = map.entrySet();
for(Iterator> it2
= entrySet.iterator();it2.hasNext();) {
Map.Entry me = it2.next();
System.out.println(me.getKey() + ".." + me.getValue());
}
}
}
/*
* 这种把班级和学生做了映射
* 学生类中封装了学号和姓名
*/
public static void oneToList() {
Map> jiSuanJi =
new HashMap>();
List ruanJian = new ArrayList();
List wangZhan = new ArrayList();
jiSuanJi.put("ruanJian", ruanJian);
jiSuanJi.put("wangZhan", wangZhan);
ruanJian.add(new PersonDemo("01","zhangsan"));
ruanJian.add(new PersonDemo("02","lisi"));
wangZhan.add(new PersonDemo("01","wangwu"));
wangZhan.add(new PersonDemo("02","zhaoliu"));
Set keySet = jiSuanJi.keySet();
for(Iterator it = keySet.iterator();it.hasNext();){
String key = it.next();
System.out.println(key);
List list = jiSuanJi.get(key);
for(Iterator it2 = list.iterator();it2.hasNext();) {
PersonDemo pd = it2.next();
System.out.println(pd);
}
}
}
}
class PersonDemo {
private String id;
private String name;
public PersonDemo(String id, String name) {
super();
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return this.id + "..." + this.name;
}
}