一、Seq2Seq 模型
1. 简介
Sequence-to-sequence (seq2seq) 模型,顾名思义,其输入是一个序列,输出也是一个序列,例如输入是英文句子,输出则是翻译的中文。seq2seq 可以用在很多方面:机器翻译、QA 系统、文档摘要生成、Image Captioning (图片描述生成器)。
2. 基本框架
第一种结构
[参考1]论文中提出的 seq2seq 模型可简单理解为由三部分组成:Encoder、Decoder 和连接两者的 State Vector (中间状态向量) C 。

上图中 Encoder 和 Decoder 可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU 。Encoder 和 Decoder 具体介绍请见第三部分。
第二种结构
该结构是最简单的结构,和第一种结构相似,只是 Decoder 的第一个时刻只用到了 Encoder 最后输出的中间状态变量 :

应用:
-
在英文翻译中,将英文输入到 Encoder 中,Decoder 输出中文。
参考1:-原创翻译- 基于RNNEncoder–Decoder的机器翻译L(earning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation)
-
在图像标注中,将图像特征输入到 Encoder 中,Decoder 输出一段文字对图像的描述。
参考2:-原创翻译- 图像标注生成器 (Show and Tell: A Neural Image Caption Generator)
在 QA 系统中,将提出的问题输入 Encoder 中,Decoder 输出对于问题的回答。
……
注:确保你对所有模型都有所了解后再阅读应用后面的参考链接。
二、RNN 结构
1. 为什么在这里提及 RNN 及 RNN 变种?
接下来要介绍的 Encoder-Decoder 模型中,Encoder 和 Decoder 两部分的输入输出可以是文字、图像、语音等等,所以 Encoder 和 Decoder 一般采用 CNN 、RNN 、LSTM 、GRU 等等。这里,我们只介绍经典 RNN 的结构。
如果对 LSTM 感兴趣的话,请参考 -原创翻译- 详解 LSTM(Understanding LSTM Networks)
2. 图解 RNN 结构
RNN 大都用来处理像一串句子、一段语音这种的序列化数据。展开的 RNN 结构图如下:

由图可见,其当前时间 t 的输出依赖两部分:前一时刻的隐层 和当前的输入 。
下面主要介绍经典的三种 RNN 结构:
(1) n VS 1

注:圆圈代表给定的输入,箭头代表运算,矩形代表隐层,也就是箭头运算后的结果。其中参数 都是一样的。在自然语言处理问题。 可以看做是第一个单词, 可以看做是第二个单词…
这种结构可应用于情感分析、文本分类等等。
(2) 1 VS n
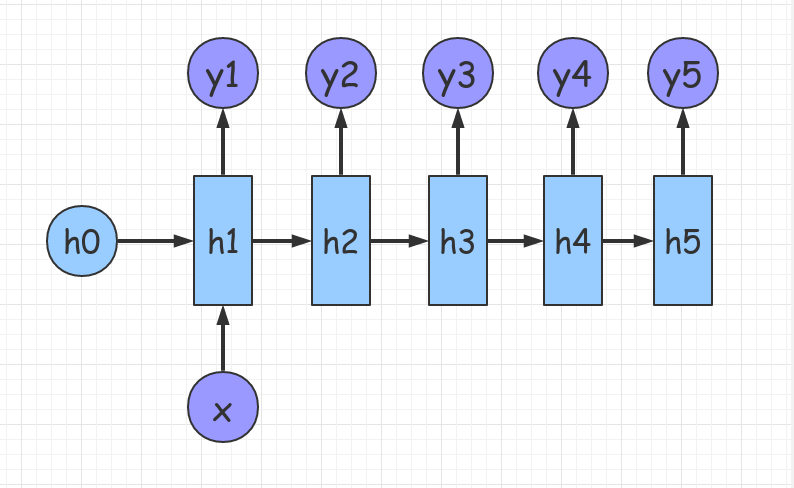
下图是把输入当作每个时刻的输入:
这种结构可应用于应用于 Image Caption ,输入是图像的特征矩阵,输出是一段对图像的描述。
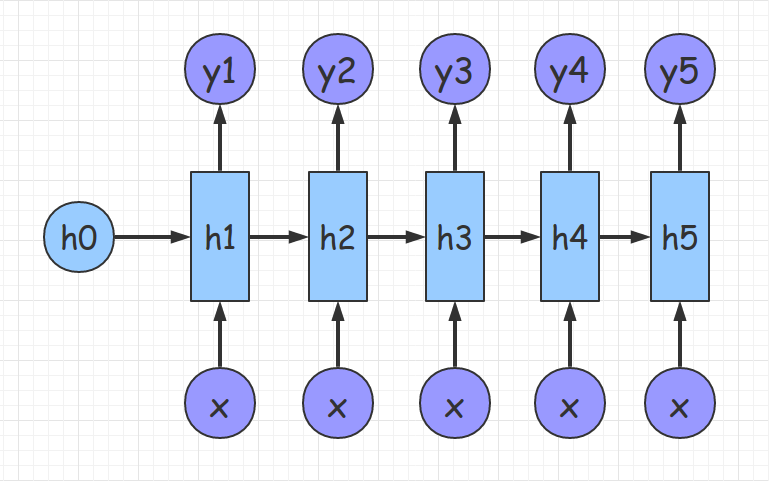
(3) n VS n

这种结构可应用于机器翻译等。如果感兴趣,可以参考下面的 文章。作者使用 RNN 实现了根据一个字母推测下一个字母的概率。
参考3:-原创翻译- RNNs的“神奇功效”(The Unreasonable Effectiveness of Recurrent Neural Networks)
(4) n VS m
在机器翻译中,源语言和目标语言的句子序列都是不等长的,而原始的 n VS n 结构都是要求序列等长的。为此,我们有了 n VS m 结构,这种结构又被称为 Encoder-Decoder模型 。具体请见下一部分。
三、Encoder-Decoder 模型
1. 简介
在第二节的第四部分,我们提出了 RNN 的 n VS m 结构:Encoder-Decoder 模型,Encoder-Decoder 模型是深度学习中常见的一种模型。在本文中,我们只简单介绍其在文本-文本的应用,比如将英语翻译成汉语,所以该模型也可以称为 Seq2Seq 模型 。下图为 Encoder-Decoder 模型的抽象图:

2. 分析
1) Encoder
给定句子对

首先,Encoder 对输入语句 X 进行编码,经过函数变换为中间语义向量 C (可以通过多种方式得到) :

2) Decoder
得到中间语义向量 C 后,使用 Decoder 进行解码。Decoder根据中间状态向量 C 和已经生成的历史信息 y1,y2…yi-1 去生成 t 时刻的单词 yi :
如果直接将 c 输入到 Decoder 中,则是 Seq2Seq 模型的第二种模型:

如果将 c 当作 Decoder 的每一时刻输入,则是 Seq2Seq 模型的第一种模型:

中英翻译中,
QA 系统中,X 是问题,Y 是回答。
-
……
Encoder-Decoder 模型是使用非常广泛的深度学习模型框架,与其说 Encoder-Decoder 是一种模型,不如称其为一种通用框架。因为 Encoder 和 Decoder 具体使用什么模型是根据任务而定义的。在自然语言处理研究中通常使用 LSTM 或者是 GRU 。
四、Attention 模型
1. Encoder-Decoder 模型的局限性
(1) 从第三节的第一部分的 Encoder-Decoder 模型的抽象图中可以看出 Encoder 和 Decoder 的唯一联系只有语义编码 C ,即将整个输入序列的信息编码成一个固定大小的状态向量再解码,相当于将信息”有损压缩”。很明显这样做有两个缺点:
- 中间语义向量无法完全表达整个输入序列的信息。
- 随着输入信息长度的增加,由于向量长度固定,先前编码好的信息会被后来的信息覆盖,丢失很多信息。
(2)大家看第三节的第二部分的第二个 Decoder 过程,其输出的产生如下:
明显可以发现在生成 时,语义编码 C 对它们所产生的贡献都是一样的。例如翻译:Cat chase mouse ,Encoder-Decoder 模型逐字生成:“猫”、“捉”、“老鼠”。在翻译 mouse 单词时,每一个英语单词对“老鼠”的贡献都是相同的。如果引入了Attention 模型,那么 mouse 对于它的影响应该是最大的。
2. 图解 Attention
为了解决上面两个问题,于是引入了 Attention 模型。Attention 模型的特点是 Decoder 不再将整个输入序列编码为固定长度的中间语义向量 C ,而是根据当前生成的新单词计算新的 ,使得每个时刻输入不同的 C,这样就解决了单词信息丢失的问题。引入了 Attention 的 Encoder-Decoder 模型如下图:

对于刚才提到的那个“猫捉老鼠”的翻译过程变成了如下:
整个翻译流程如下:
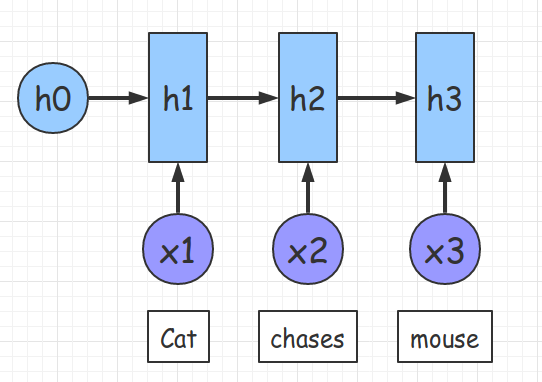
图中输入是 Cat chase mouse ,Encoder 中隐层 h1、h2、h3 可看作经过计算 Cat、chase、mouse 这些词的信息。

使用 表示 Encoder 中第 j 阶段的 和解码时第 i 阶段的相关性,计算出解码需要的中间语义向量 。 和 “猫” 关系最近,相对应的 要比 、 大;而 和 “捉” 关系最近,相对应的 要比 、 大;同理 和 “老鼠” 关系最近,相对应的 要比 、 大。

那么参数 是如何得到呢?
Encoder 中第 j 个隐层单元 和 Decoder 第 i-1 个隐层单元 经过运算得到 。
例如 的计算过程:

的计算过程:

参考 :引入Attention 并基于 RNN 的 Encoder-Decoder 模型公式推导