FrontendService(Thrift服务Server端)
FrontendService负责与客户端进行交互:维护与客户端的连接,并将SQL执行结果返回至客户端。
FrontendService.scala:
FrontendService的类声明如下所示:从FrontendService类声明中可以看出,该类实现了Runnable接口,看一下它如何重写的run方法。
- run()方法
override def run(): Unit = {
try {
// Server thread pool
val minThreads = conf.get(FRONTEND_MIN_WORKER_THREADS.key).toInt
val maxThreads = conf.get(FRONTEND_MAX_WORKER_THREADS.key).toInt
//使用Java线程池ThreadPoolExecutor
val executorService = new ThreadPoolExecutor(
minThreads,
maxThreads,
conf.getTimeAsSeconds(FRONTEND_WORKER_KEEPALIVE_TIME.key),
TimeUnit.SECONDS,
new SynchronousQueue[Runnable],
new NamedThreadFactory(threadPoolName))
// Thrift configs
authFactory = new KyuubiAuthFactory(conf)
val transportFactory = authFactory.getAuthTransFactory
val processorFactory = authFactory.getAuthProcFactory(this)
//使用TServerSocket创建阻塞式IO,TServerSocket继承自TTransport
//也就是说,TServerSocket属于TTransport这一层
val serverSocket: TServerSocket = getServerSocket(serverIPAddress, portNum)
// Server args
val maxMessageSize = conf.get(FRONTEND_MAX_MESSAGE_SIZE.key).toInt
val requestTimeout = conf.getTimeAsSeconds(FRONTEND_LOGIN_TIMEOUT.key).toInt
val beBackoffSlotLength = conf.getTimeAsMs(FRONTEND_LOGIN_BEBACKOFF_SLOT_LENGTH.key).toInt
val args = new TThreadPoolServer.Args(serverSocket)
.processorFactory(processorFactory)
.transportFactory(transportFactory)
//客户端协议要一致,这里使用的协议是TBinaryProtocol,它使用二进制格式
.protocolFactory(new TBinaryProtocol.Factory)
.inputProtocolFactory(
new TBinaryProtocol.Factory(true, true, maxMessageSize, maxMessageSize))
.requestTimeout(requestTimeout).requestTimeoutUnit(TimeUnit.SECONDS)
.beBackoffSlotLength(beBackoffSlotLength)
.beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executorService)
// TCP Server
//建立TThreadPoolServer线程池服务模型
server = Some(new TThreadPoolServer(args))
server.foreach(_.setServerEventHandler(serverEventHandler))
info(s"Starting $name on host ${serverIPAddress.getCanonicalHostName} at port $portNum with" +
s" [$minThreads, $maxThreads] worker threads")
//启动服务
server.foreach(_.serve())
} catch {
case t: Throwable =>
error("Error starting " + name + " for KyuubiServer", t)
System.exit(-1)
}
}
其中,TThreadPoolServer涉及到Thrift服务的通信模型,理解Thrift服务可以参照这篇博文:Thrift 通信模型
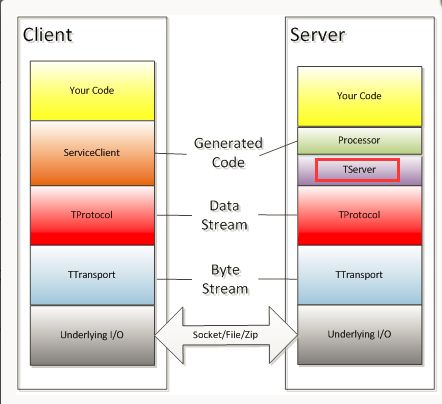
下面这张图是Thrift服务的通信协议栈,TThreadPoolServer属于TServer的一种模型(图中红色方框标注处)。TServer主要作用是接收Client的请求,并转到某个TProcessor上进行请求处理。针对不同的访问规模,Thrift提供了不同的TServer模型。TThreadPoolServer使用阻塞IO的多线程服务器,使用线程池管理处理线程。
TThreadPoolServer的示例代码参见:
Thrift 多线程阻塞式IO服务模型-TThreadPoolServer
我们与Hive源码中 org.apache.hive.service.cli.thrift包下 ThriftBinaryCLIService(该类继承自ThriftCLIService)的run方法进行类比,可以看出代码逻辑几乎完全相似。
@Override
public void run() {
// Server thread pool
String threadPoolName = "HiveServer2-Handler-Pool";
ExecutorService executorService = new ThreadPoolExecutorWithOomHook(minWorkerThreads,
maxWorkerThreads, workerKeepAliveTime, TimeUnit.SECONDS,
new SynchronousQueue(), new ThreadFactoryWithGarbageCleanup(threadPoolName),
oomHook);
// Thrift configs
hiveAuthFactory = new HiveAuthFactory(hiveConf);
TTransportFactory transportFactory = hiveAuthFactory.getAuthTransFactory();
TProcessorFactory processorFactory = hiveAuthFactory.getAuthProcFactory(this);
***省略部分代码***
// Server args
int maxMessageSize = hiveConf.getIntVar(HiveConf.ConfVars.HIVE_SERVER2_THRIFT_MAX_MESSAGE_SIZE);
int requestTimeout = (int) hiveConf.getTimeVar(
HiveConf.ConfVars.HIVE_SERVER2_THRIFT_LOGIN_TIMEOUT, TimeUnit.SECONDS);
int beBackoffSlotLength = (int) hiveConf.getTimeVar(
HiveConf.ConfVars.HIVE_SERVER2_THRIFT_LOGIN_BEBACKOFF_SLOT_LENGTH, TimeUnit.MILLISECONDS);
TThreadPoolServer.Args sargs = new TThreadPoolServer.Args(serverSocket)
.processorFactory(processorFactory).transportFactory(transportFactory)
.protocolFactory(new TBinaryProtocol.Factory())
.inputProtocolFactory(new TBinaryProtocol.Factory(true, true, maxMessageSize, maxMessageSize))
.requestTimeout(requestTimeout).requestTimeoutUnit(TimeUnit.SECONDS)
.beBackoffSlotLength(beBackoffSlotLength).beBackoffSlotLengthUnit(TimeUnit.MILLISECONDS)
.executorService(executorService);
// TCP Server
server = new TThreadPoolServer(sargs);
server.setServerEventHandler(new TServerEventHandler() {
***省略部分代码***
}
String msg = "Starting " + ThriftBinaryCLIService.class.getSimpleName() + " on port "
+ portNum + " with " + minWorkerThreads + "..." + maxWorkerThreads + " worker threads";
LOG.info(msg);
server.serve();
} catch (Throwable t) {
LOG.error(
"Error starting HiveServer2: could not start "
+ ThriftBinaryCLIService.class.getSimpleName(), t);
System.exit(-1);
}
}
是不是几乎一毛一样?哈哈~~
Thrift服务Hive JDBC客户端
既然Thrift服务是基于C/S模式,而FrontendService又负责与客户端交互。上文通过解析FrontendService的代码,可以看出Thrift Server端的大致逻辑。下面简单分析一下Thrift Client端的代码逻辑。
无论是MySQL还是Hive,通过JDBC连接时(包括Beeline客户端连接)的逻辑大致相同,在连接时都会基于反射机制去加载jar包中的代码。感兴趣的同学可以参考以下博文(这两篇分别是两个作者写的):JAVA JDBC(MySQL)驱动源码分析(一)和JDBC源码解析(二):获取connection。
Hive JDBC连接的jar包叫org.apache.hadoop.hive.jdbc.HiveDriver,当JDBC连接时会调用HiveDriver的connect方法,connect方法中又会实例化一个HiveConnection的对象。
HiveConnection.java:
- HiveConnection构造方法
public HiveConnection(String uri, Properties info) throws SQLException {
***省略部分代码***
for (int numRetries = 0;;) {
try {
// open the client transport
//这里的transport我理解为socket,当然transport不仅仅是socket
openTransport();
// set up the client
client = new TCLIService.Client(new TBinaryProtocol(transport));
// open client session
openSession();
//这行代码相关的JIRA还是Hive Commiter帮我提交进去的,哈哈哈~
executeInitSql();
break;
}
***省略部分代码***
}
Hive源码中的注释已经写得很清楚,我们来分析这一行代码:
client = new TCLIService.Client(new TBinaryProtocol(transport));
这行代码做了一层层的封装,最后创建了Client对象。结合Thrift服务的通信模型,也就是从底层往上一层层地进行封装:TTransport => TProtocol => Client。
openSession()的解析,请看我写的这篇博文:Kyuubi服务源码解析:OpenSession解析
这里有必要分析一下openTransport()的过程,因为涉及到Kerberos认证,有助于梳理Kerberos认证的流程。详细内容见我写的Kerberos文集中HiveConnection之openTransport()方法解析。