本文主要讲解一下spark2.0版本Spark-StandAlone模式下executor的分配过程和分配机制。
跟踪这一块的源代码应该从SparkContext类开始。当用户new SparkContext时,会执行该类中定义在class body中的代码。这部分代码会执行spark作业初始化之类的操作,比如校验参数、初始化spark history server、初始化blockManager等等。我们需要关注的是他构建TaskScheduler这一部分的代码。这也是executor初始化的切入点,如下图:

点开createTaskScheduler方法可以看到,他基于spark master的类型构建了SchedulerBackend。而TaskScheduler的类型基本上都是TaskSchedulerImpl。

匹配spark master类型的正则表达式如下,感兴趣的可以了解一下:

然后我们一路ctrl + alt +左箭头返回SparkContext类,看到_taskScheduler.start(),点进去。然后看到backend.start()点进去。其中backend对象就是之前在createTaskScheduler方法中创建的StandaloneSchedulerBackend。
下图中command对象封装的是在worker端启动executor的命令。而initialExecutorLimit是spark-standalone模式提供的dynamic allocation机制,他可以在executor闲置一段时间后就将其移除。对应参数spark.dynamicAllocation.enabled,默认为false。

然后看一下client.start()方法,点进去。然后看到new ClientEndpoint,再点进去。

然后会调用到这个类中的onStart方法,有人会问为什么会调到这个方法呢,这里只是将其new出来了,并没有执行任何操作啊!?答案就在前边的rpcEnv.setupEndpoint方法。在该方法中通过回调机制会重新调用到onStart方法。点进去,跟到NettyRpcEnv的setupEndpoint方法

然后继续跟踪到dispatcher.registerRpcEndpoint方法,

然后点进new EndpointData方法,然后跟踪到new Inbox。Inbox在通信机制中起到一个消息存取的作用。

在Inbox中的class body中有如下一段

然后看到OnStart event的处理

�
点开ClientEndpoint后就会看到我们接下来要执行到的onStart()方法了。

然后再看这个类中的onStart()方法,registerWithMaster方法点进去,然后再看到tryRegisterAllMasters方法点进去。在这个方法中会看到构建了一个与master通信的RPC终端,并发送了RegisterApplication事件,

在发送过程中,会将这条消息序列化,如下:

在整个spark core中搜索一下这个case class,然后在Master的receive方法中找到了对这类消息的处理逻辑如下:
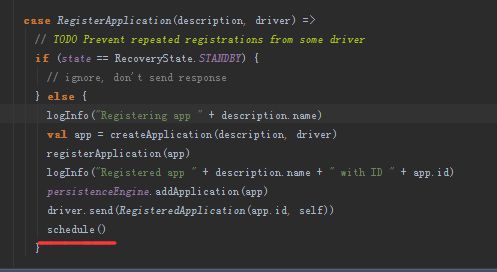
在这部分代码中createApplication方法会根据当前时间创建appId,appId格式为:
app-yyyyMMddHHmmss-nextAppNumber
nextAppNumber是随着app的提交而递增的。
除此之外还会构建ApplicationInfo对象,需要注意的是该对象的desc.command中存放了在worker端启动Executor的命令。
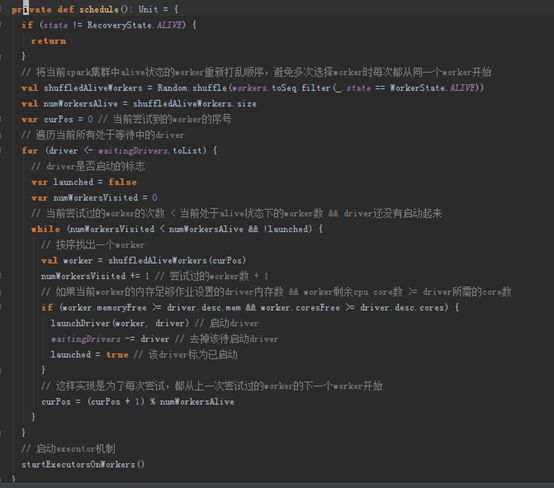
然后看一下scheduler()方法。该方法中实现了启动driver的逻辑,以及启动executor的入口方法。该部分代码的逻辑请参考图中的注释。
然后看一下startExecutorsOnWorkers方法,该方法对多个app采用FIFO策略分配executor。首先选出内存和cpu核数满足条件的worker,作为候选worker。然后按照scheduleExecutorsOnWorkers方法实现的策略分配executor。然后通过allocateWorkerResourceToExecutors方法在指定的worker上通过事件启动该executor。方法讲解参考备注。

�
接下来我们重点的看一下scheduleExecutorsOnWorkers方法。该方法实现了在worker集群中分配executor的策略。
首先看一下局部方法canLaunchExecutor,该方法用来判断指定序号的worker能否启动executor。判断的两个主要因素是内存和cpu core数是否满足单个executor的最小要求,除此之外还会考虑app要求的总资源数,以及单个worker上能否启动多个executor的配置。具体的实现逻辑请参考截图中的代码注释。

然后看一下scheduleExecutorsOnWorkers方法中的其他代码:
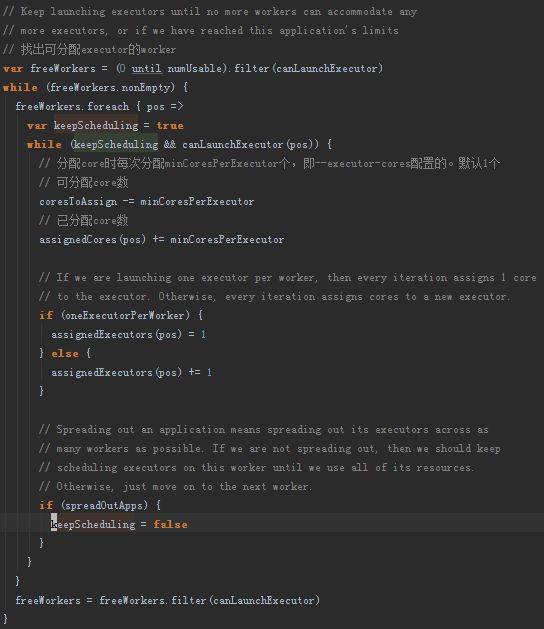
这部分代码是用来实现executor分配机制的。这段代码比较清晰,master会逐个遍历当前可用的worker,如果该worker可用,直接为其分配一个executor基数的core,然后会读取一个系统参数spark.deploy.spreadOut。当该参数配置为false,master会将该worker上的core一直分配给这个app,直到当前worker没有足够资源,或者app的要求已经满足。如果配置为true,则每个worker在分配完一次资源后,会跳转到下一个worker继续再分配,直到下一次对整个workers集群的遍历重新开始。这样做的意义是尽可能的将executor分配到更多的worker上去执行,有利于计算时的本地化计算,否则在计算时计算所需的数据不在当前节点,就需要占用网络资源拉取数据。系统默认配置为true。

我在阅读这段代码时有一个疑问。Executor的分配结果不仅是core,还包含了mem和某个worker上启动executor的个数。而方法的返回值只有某个worker上分配的core数,那么如何判断executor的个数呢。对于不了解计算逻辑的人会认为oneExecutorPerWorker模式下一个executor可能会被分配了minCorePerExecutor+个core,此时如果单纯通过worker上实际分配的core个数除以minCorePerExecutor就无法正确计算出executor个数了。这时就会想为什么不在方法返回值中带有executor个数呢?
继续往下看就会找到答案,在实际启动executor时,是根据用户是否配置了coresPerExecutor来决定executor个数的,在没有配置(也就是在OneExecutorPerWorker模式下)的情况下executor个数是固定为1的,其他情况下是用已分配core数/ coresPerExecutor计算的。

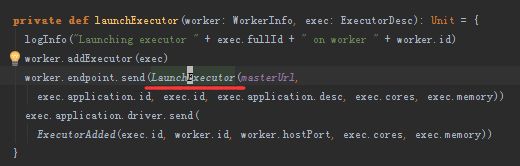
然后点进launchExecutor方法看一下,在master端会向worker端发送启动executor的命令LaunchExecutor,命令包含在exec.application.desc的command中。创建完成后会向driver端发送ExecutorAdded event,driver接收到后会打印日志。

然后worker端在收到LaunchExecutor命令后,会实例化一个ExecutorRunner,然后调用其start方法,在该方法中启动了一个workerThread线程,其run方法的实现逻辑为方法fetchAndRunExecutor。这个方法就比较直观了,取出创建Executor的命令appDesc.command封装成ProcessBuilder类,用它来执行启动Executor的命令。

没错,启动的命令就是前文中提到的command对象: