写在前面
我们写的JS代码浏览器是如何解析的?浏览器在执行JS代码的过程中发生了什么?...这些问题可能在完成业务功能代码的过程中并没有多么重要,但是作为一名前端开发工程师,了解这些会提升自己的思维能力、会让自己更深层次的理解JavaScript语言。这篇文章将详细阐述浏览器中堆栈内存的底层处理机制、垃圾回收机制以及内存泄漏的几种情况。
浏览器执行代码需要经历什么
编译
- 词法解析:这个过程会将由字符组成的字符串分解成有意义的代码块(词法单元)。
- 语法分析:这个过程将词法单元流转换成一个由元素逐级嵌套所组成的代表了程序语法的树(抽象语法树 =>
AST)。 - 代码生成:将
AST转换为可执行代码的过程被称为代码生成。
引擎编译执行代码
然后将构建出的代码交给引擎(V8),这个时候可能会遇到变量提升、作用域和作用域链/闭包、变量对象、堆栈内存、GO/VO/AO/EC/ECStack、...。
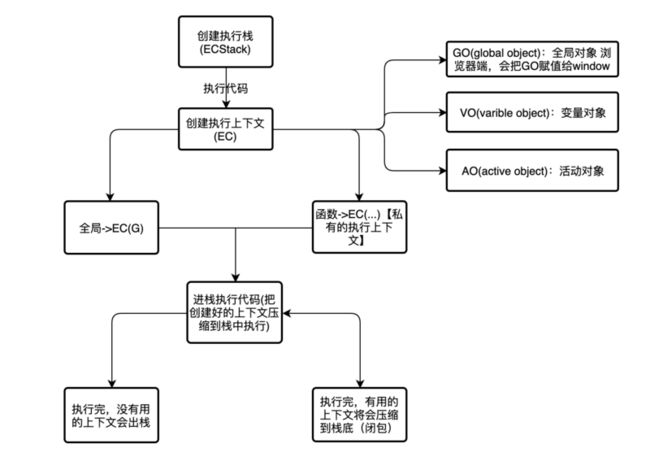
引擎在编译执行代码的过程中,首先会创建一个执行栈,也就是栈内存(ECStack => 执行环境栈),然后执行代码。
在代码执行会创建EC(执行上下文),执行上下文分为全局执行上下文(EC(G))和函数执行上下文(EC(...)),其中函数的执行上下文是私有的。
创建执行上下文的过程中,可能会创建:
-
GO(Global Object):全局对象 浏览器端,会把GO赋值给window -
VO(Varible Object):变量对象,存储当前上下文中的变量。 -
AO(Active Object):活动对象
然后将进栈执行,创建好的上下文将压缩到栈中执行,执行后一些没用的上下文将出栈,有用的上下文会压缩到栈底(闭包)。栈底永远是全局执行上下文,栈顶则永远是当前执行上下文。
下面的一张图表达了整个流程
变量赋值的三步操作
第一步,创建变量,这个过程叫做声明(declare)。
第二步,创建值。基本类型值会直接在栈中创建和存储;由于引用类型值是复杂的结构,所以需开辟一个存储对象中键值对(存储函数中代码)的内存空间,这个内存就是堆内存,所有的堆内存都有可被后续查找的16进制地址,后续关联赋值时,是把堆内存地址给予变量操作。
最后一步,将变量和值关联,这个过程叫做定义(defined)。这里,如果值只经过了声明,而没有进行赋值操作,这个值就是未定义(undefined)。
一道题理解这个过程
我将以画图的形式展示
// 1.
let a = 12;
let b = a;
b = 13;
console.log(a);
// 2.
let a = {n:12};
let b = a;
b['n'] = 13;
console.log(a.n);
// 3.
let a = {n:12};
let b = a;
b = {n:13};
console.log(a.n);- 第一问
创建执行栈,形成全局执行上下文,并且创建GO,进入栈中执行代码
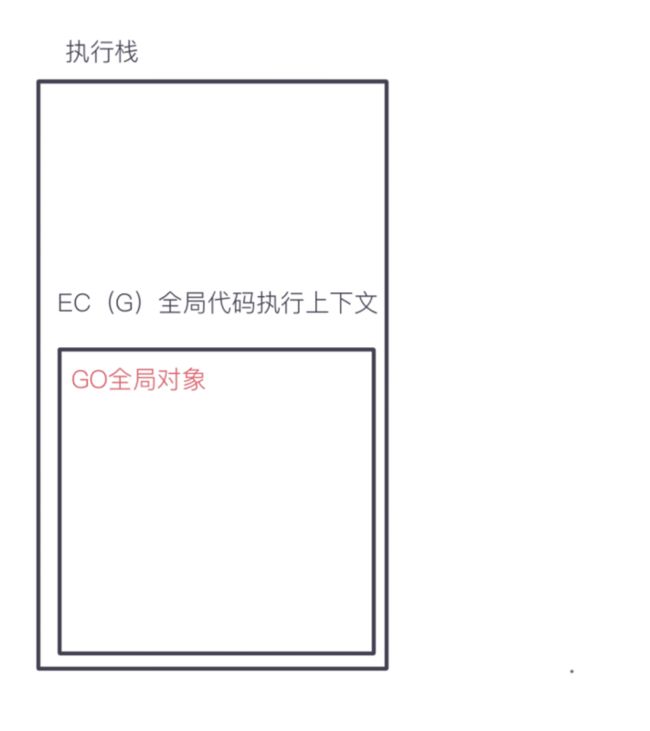
基本类型直接在栈中创建和存储
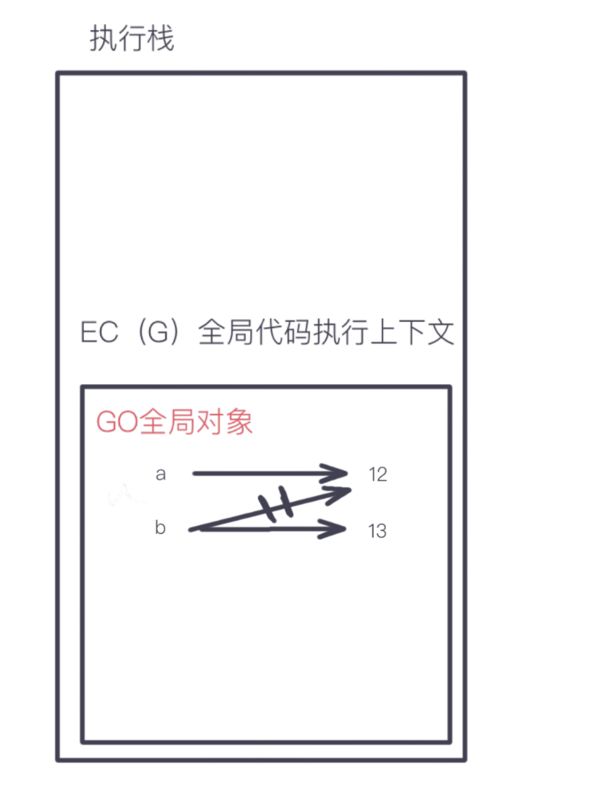
所以本问最终输出的a值为12。
- 第二问
创建执行栈,形成全局执行上下文,并且创建GO,进入栈中执行代码
引用类型值比较复杂,将创建堆内存
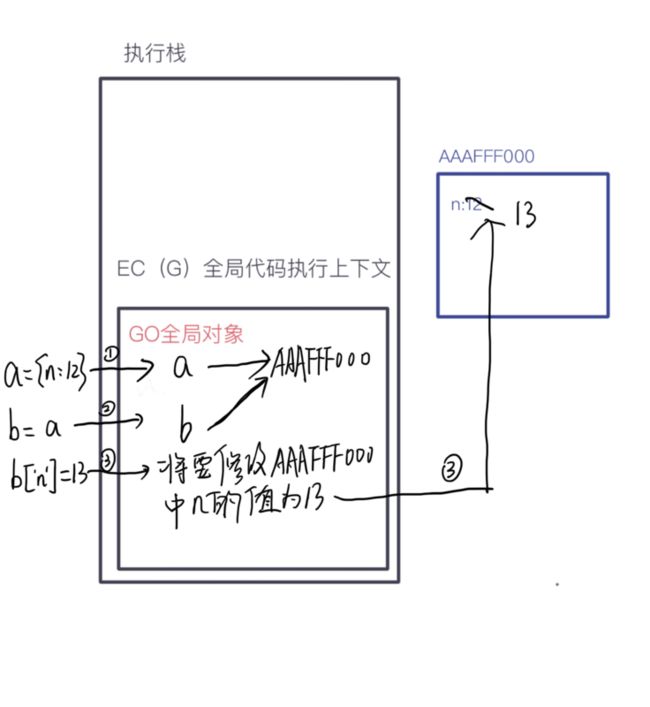
所以本问最终输出的a.n为13
- 第三问
创建执行栈,形成全局执行上下文,并且创建GO,进入栈中执行代码
引用类型值比较复杂,将创建堆内存

所以本问最终输出的a.n的值为12。
几道面试题让你更深次理解浏览器堆栈内存的底层处理机制
- 第一个题
let a = {
n: 10
};
let b = a;
b.m = b = {
n: 20
};
console.log(a);
console.log(b);创建执行栈,形成全局执行上下文,并且创建GO,进入栈中执行代码
引用类型值比较复杂,将创建堆内存
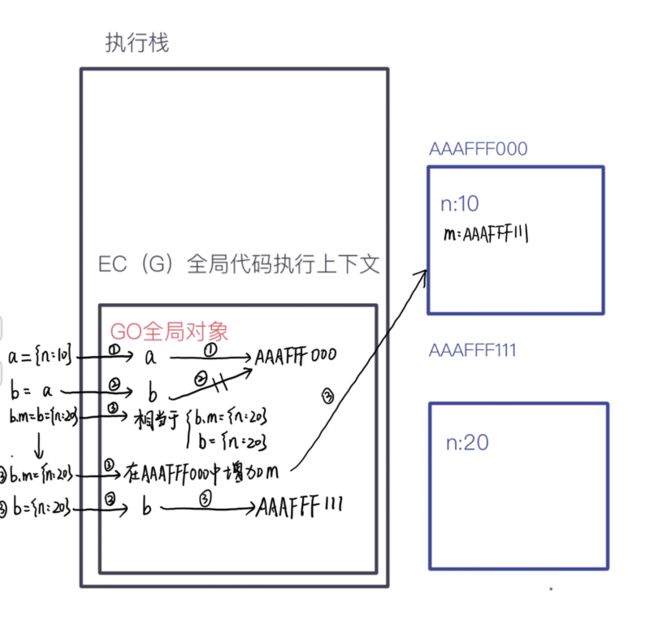
所以最终输出的a为{n: 10, m: {n: 20}};b为{n: 20}
- 第二个题:
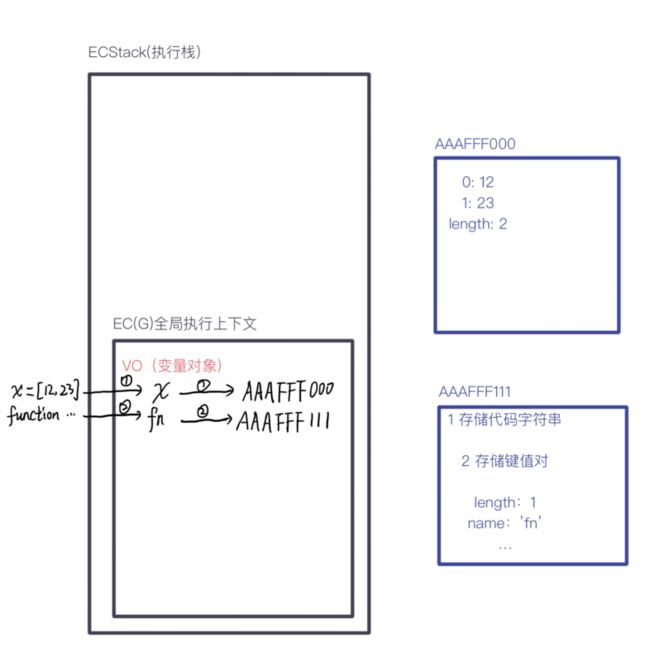
let x = [12, 23];
function fn(y) {
y[0] = 100;
y = [100];
y[1] = 200;
console.log(y);
}
fn(x);
console.log(x);首先会创建ECStack,形成全局执行上下文,创建VO(变量对象), 然后进入栈中执行代码
变量赋值
接下来会执行fn(x)函数,函数执行会形成一个全新的执行上下文,会产生AO。上面说过,栈顶永远是当前执行上下文,栈底是全局执行上下文,所以函数执行,函数执行上下文将进栈,会将全局执行上下文压入栈底。

然后进行代码的执行操作,执行后会出栈
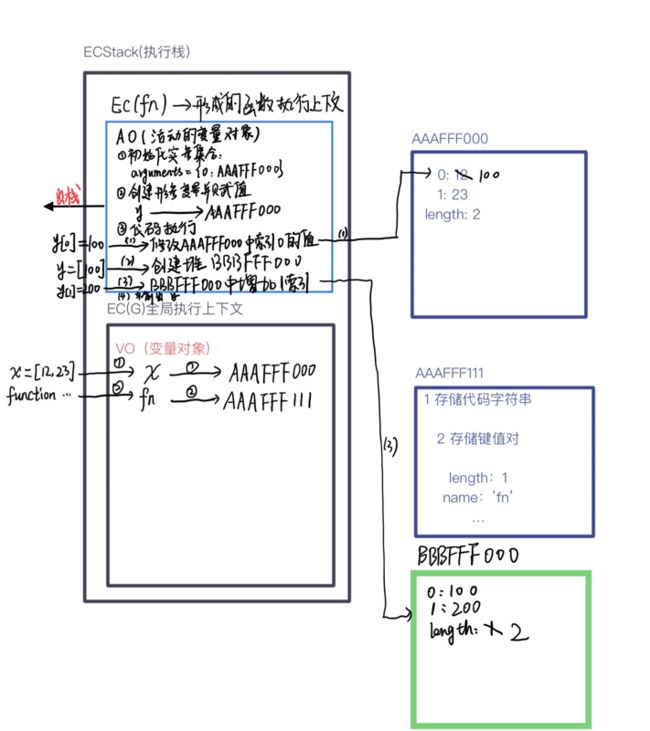
继续执行,打印出x,经过上述分析:
答案是:[100, 200] [100, 23]
- 第三个题
var x = 10;
~ function (x) {
console.log(x);
x = x || 20 && 30 || 40;
console.log(x);
}();
console.log(x);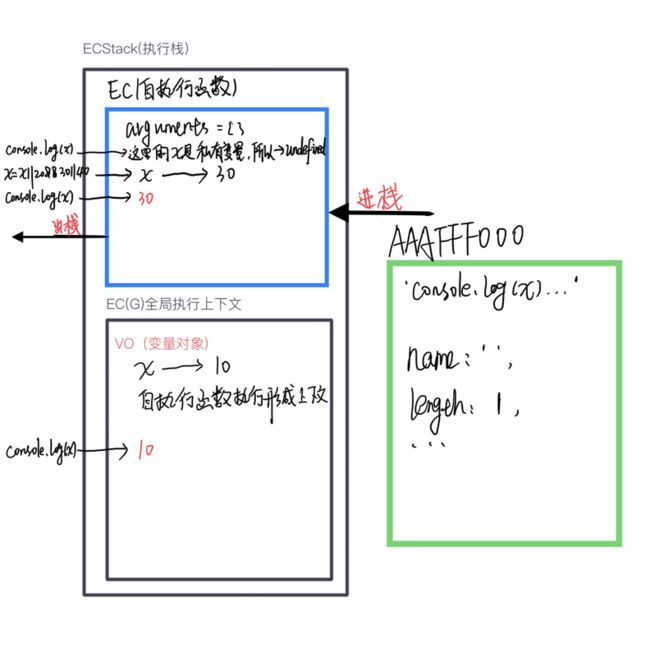
所以,最终的结果为:undefined 30 10
- 第四题
let x = [1, 2],
y = [3, 4];
~ function (x) {
x.push('A');
x = x.slice(0);
x.push('B');
x = y;
x.push('C');
console.log(x, y);
}(x);
console.log(x, y);
所以本题最终的输出结果为[3, 4, 'C'] [3, 4, 'C'] [1, 2, 'A'] [3, 4, 'C']。
垃圾回收机制
浏览器的Javascript具有自动垃圾回收机制(GC:Garbage Collecation),垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。
标记清除
在js中,最常用的垃圾回收机制是标记清除:当变量进入执行环境时,被标记为“进入环境”,当变量离开执行环境时,会被标记为“离开环境”。垃圾回收器会销毁那些带标记的值并回收它们所占用的内存空间。
function demo() {
var a = 1; // 标记"进入环境"
var b = 2; // 标记"进入环境"
}
demo(); // 函数执行完毕,a和b标记为"离开环境"引用计数
浏览器会跟踪记录值的引用次数,每多引用一次,引用次数就会加1,取消占用,引用次数就会减1,当引用次数为0时,浏览器会进行垃圾回收。
下面的例子说明a引用次数的变化
function demo() {
var a = {}; // +1
var b = a; // +1 => 2
b = null; // -1 => 1
a = null; // -1 => 0 ====> 此时会回收
}内存泄漏
内存泄露是指程序中的某些函数或者任务执行完毕之后,本该释放的内存空间,由于各种原因,没有被释放,导致程序越来越耗内存,最终可能引发程序崩溃等各种严重后果。
在 JS 中,常见的内存泄露主要有 4 种
全局变量
一个例子直接说明:
var obj = null;
function foo(){
obj = { name:"小红" };
}
foo();上述代码中,obj是一个全局变量,这样,所有和obj作用域同层级的函数都可以访问到obj对象,所以obj对象不会被回收。
闭包
闭包是 JS 中最容易引起内存泄露的特性
function foo(){
var obj = {name:"小红"}
return function(){
return obj.name;
}
}
var func = foo(); // foo返回的值是一个函数,func也变成了一个外部函数
func(); // 外部函数func能狗访问foo内部的user对象。上述代码中,foo函数执行完后,因为在func()中依然能够访问到obj,所以变量obj没有被释放,这就导致了内存泄漏,我们可以用下面的方法解决
function foo(){
var obj = {name:"小红"}
return function(){
var obj1 = obj;
obj = null;
return obj1.name;
}
}
var func = foo(); // foo返回的值是一个函数,func也变成了一个外部函数
func(); 上面的代码中,在foo函数返回的函数中,及时将obj释放了,这个时候,在func函数执行时,就不会访问到局部变量obj了。
DOM 元素的引用
对DOM元素的引用中,会出现内存泄漏
-
DOM元素删除了,但是JS对象中的引用没删除
上面的例子中,点击#app时,清除了该DOM节点,但是appDom依然保留对其的引用,导致#app没有被释放。
- 使用第三方库
定时器
setInterval函数的定时器会一直循环,除非手动清除,这就出现了内存隐患,所以我们应该在使用完定时器时对定时器及时清除。
var count = setInterval(() => {
console.log(1);
}, 1000);
// 使用完成
clearInterval(count)以上是导致内存泄漏的四种情况(例子不只有文中的几个,在平时的开发工作中还会有很多的例子),在我们的日常开发工作中,应该避免这四种情况的发生,所以我们写代码的额过程中,要多多注意。
总结
本文详细讲解了在浏览器中是如何对堆栈内存进行处理的,也简单说了一下垃圾回收机制的几种方法和造成内存泄漏的几种情况。还请大家在仔细阅读后,能够指出其中不合理甚至错误的地方,我们共同学习,共同进步~
最后,分享一下我的公众号「web前端日记」,希望大家多多关注
